终于把第一次作业完成了,不过实现效果貌似很差,调不好了就这样吧。
Section 1
第一部分先装环境。没啥好说的。我用的anaconda直接pip install 对应的作业1文件夹里的requirement.txt。其中MuJoCo需要激活个key,可以去官网使用学生邮箱申请一个免费的,时间为一年。
这次要用的6个环境如下,盗图一张:

Section2
进入正题。这次的作业是完成模仿学习。在gym仿真环境里,依赖于MoJoCo的模拟器。提供了6个环境的专家策略,运行run_expert.py生成对应的状态动作的数据,然后根据这些数据来进行模仿学习。
第一步自然是看懂run_expert.py的代码然后运行啦。将产生的数据放进expert_data文件夹。利用的是默认的参数,20个rollouts,每个最多1000步。因此有20000个对应的状态动作对。当然有的任务里走不到1000步一次rollout。
第二步进行仿真学习:
仿真学习的思想很简单,本质上就是个监督学习。根据给定的状态-动作对数据,拟合那个策略函数,其实就是个回归问题。

第一步里面已经根据专家策略生成了对应的数据,只需要利用这些数据进行一个回归即可。啪啪啪写一通,大概用2到3层全连接层即可。状态作为x,动作作为对应的y。
然后开始训练。超参什么的也没什么要求,但是我怎么调参训练都得不到太好的效果,很难受。
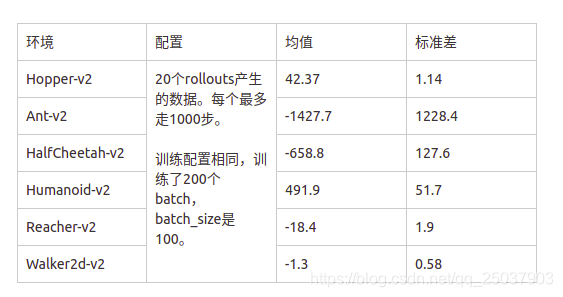
这是最开始训练得到的效果,后来调了大半天比这个好很多,但是本质上没啥差别,可能多训练了几轮稍微好点。总之比专家策略的效果差到不知道哪里去了。
Section3
看来直接使用模仿学习不太行,不过还有个更好的算法Dagger。Dagger的算法重点在于解决训练集合与应用学到的策略时遇到的状态集合不一致的情况,算法如下:

其实就是个不断融合数据集的过程,次数足够多之后训练集与会遇到的状态趋于同一个分布。(将测试集加到训练集里的感觉23333)
代码的部分没啥好说的,就是先按BC的算法训练得到一个模型,然后应用到环境中。把应用的时候的状态存下来,使用专家策略policy_fn来对这些状态进行标注(相当于算法图中的3),之后融合数据继续训练。
然而我实在没有调出什么好的效果,只能宣告gg。
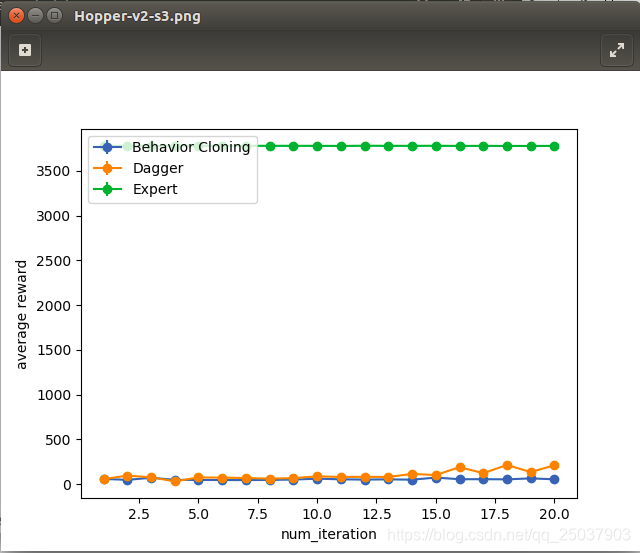
这张图算是6个环境里我的Dagger算法比BC效果好的最明显的一个,然而比专家算法的效果差了实在太多。其中超参设置为batch_size=200,Iteration = 200,epoch = 20。这里的关系不太严谨,对于用来对比的BC算法来说因为只有20000条数据,所以一个epoch用了batch_size*iteration/20000=2轮数据。对于Dagger而言参数设置也是一样,但是每一个epoch之后Dagger算法又会增加20000条新的数据。比如epoch=3时,BC算法迭代了3*200*200条数据,但是总数只有20000条,每条数据都用了6次。DAgger也迭代了3*200*200条数据,但Dagger的数据有60000条,因此每条只用了2次。
我的代码实现在github cs294作业,虽然实现得效果不好,但还是求star。
这里顺便推一下知乎看到的一个实现,他实现的效果很好。强化学习传说。我把网络结构和超参改得和他一样效果还是半死不活,百思不得其解。大概是因为版本的原因吧,他做的是春季的,mojoco版本不太一样。whatever,这次的作业就是这样。