1、环境详情
**·**1台HMaster 2台HRegionServer
2、创建一张订单表
**·**create table if not exists order_1 (id varchar primary key,sale_amount double,discount_amount double,current_time varchar);
3、生成模拟订单数据
·
注:upsert 而不是 insert
**·**生成300M数据 大约300万条
4、将生成的test.txt 修改为 test.sql
5、将test.sql 放到 主机 phoenix的bin目录下
6、运行test.sql文件
**·**psql.py test.sql
7、插入速度
·开始速度每秒1000+
·数据到达40w+时,速度变为500+
**·**当数据达到80w,速度非常迟缓,每秒不一定有1条插入
**·**查看内存使用
发现还有2.7G内存处于空闲状态
**·**退出 重新执行psql.py test.sql (把test.sql前80+w行删掉 vi test.sql => 800000dd)
**·**查看执行速度 执行速度还是相当快的
**·**分析:
Phoenix适合插入和修改数据
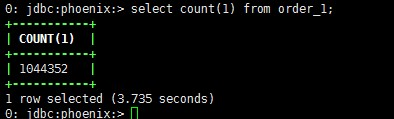
8、查询性能测试
100w为例
**·**简单的count(1)查询100W 需要3.7秒
**·**查询数据效率还是相当快的
**·**查询order by
我们发现,插入数据时,是按照key 的升序存储的
**·**其他列的order by
我们发现,查询速度比较缓慢。建议把需要order by的字段,组合拼成key
**·**查询所有的订单数 ID是由订单ID+物品ID组成的
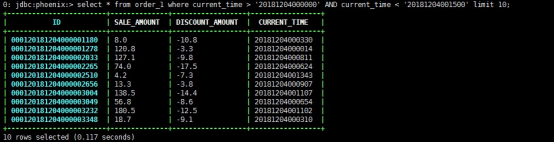
**·**查询某个时间段内的数据 查询速度还是特别快的
**·**根据时间,查询时间段内的订单数
**·**根据时间,查询某个时间段的总交易额
**·**换种方式尝试下(数据在不断插入,可能数额可能会有差异)
问题:使用sum进行计算double时,出现了精度失真问题
解决方案:使用DECIMAL(10,2)类型,替换掉double
**·**分析:
Phoenix适合过滤操作
聚合操作性能一般
9、测试join性能
**·**创建会员-订单表
**·**生成随机数据 100w+ 约80M
**·**修改文件名字 test01.txt=>test01.sql
**·**执行sql脚本 psql.py test01.sql
**·**由于订单ID 只会有4950个值(策划失误),结束运行test01.sql脚本
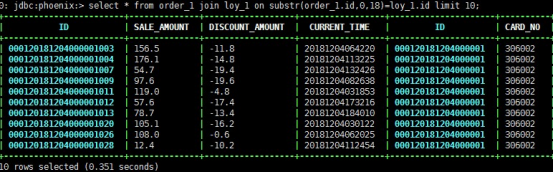
**·**join操作
**·**join聚合操作 查看有多少订单是会员订单数
不建议使用join聚合操作
运行时间 >5分钟













10、总结
**·**phoenix适合修改数据
**·**phoenix适合过滤、查询、join操作
**·**phoenix不适合聚合操作
**·**合理地设置rowkey 提升性能
**·**自动按照rowkey的升序进行存储