版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/marvHuang/article/details/84592532
什么是数据库索引?数据库索引类型有哪些?什么是最左前缀原则?索引算法有哪些?有什么区别?
数据库索引
定义:索引是对数据库表中一列或多列的值进行排序的一种结构。一个非常恰当的比喻就是书的目录页与书的正文内容之间的关系,为了方便查找书中的内容,通过对内容建立索引形成目录。索引是一个文件,它是要占据物理空间的。
数据库索引类型
- 主键索引:数据列不能重复,不允许有NULL,一个表只能有一个主键
- 唯一索引:数据列表不允许重复,允许为NULL,一个表可以创建多个唯一索引
- 普通索引:基本的索引类型,没有唯一性的限制,允许为NULL
- 全文索引:通过
Alter TABLE table_name ADD FULLTEXT(column);创建全文索引
最左前缀
- 定义:就是最左优先,在创建多列索引时,要根据业务需求,where子句中使用最频繁的一列放在最左边
- 生效原则:组合索引的生效原则是 从前往后依次使用生效,如果中间某个索引没有使用,那么断点前面的索引部分起作用,断点后面的索引没有起作用
比如:
where a=3 and b=45 and c=5 .... 这种三个索引顺序使用中间没有断点,全部发挥作用;
where a=3 and c=5... 这种情况下b就是断点,a发挥了效果,c没有效果
where b=3 and c=4... 这种情况下a就是断点,在a后面的索引都没有发挥作用,这种写法联合索引没有发挥任何效果;
where b=45 and a=3 and c=5 .... 这个跟第一个一样,全部发挥作用,abc只要用上了就行,跟写的顺序无关
(0) select * from mytable where a=3 and b=5 and c=4;
abc三个索引都在where条件里面用到了,而且都发挥了作用
(1) select * from mytable where c=4 and b=6 and a=3;
这条语句列出来只想说明 mysql没有那么笨,where里面的条件顺序在查询之前会被mysql自动优化,效果跟上一句一样
(2) select * from mytable where a=3 and c=7;
a用到索引,b没有用,所以c是没有用到索引效果的
(3) select * from mytable where a=3 and b>7 and c=3;
a用到了,b也用到了,c没有用到,这个地方b是范围值,也算断点,只不过自身用到了索引
(4) select * from mytable where b=3 and c=4;
因为a索引没有使用,所以这里 bc都没有用上索引效果
(5) select * from mytable where a>4 and b=7 and c=9;
a用到了 b没有使用,c没有使用
(6) select * from mytable where a=3 order by b;
a用到了索引,b在结果排序中也用到了索引的效果,前面说了,a下面任意一段的b是排好序的
(7) select * from mytable where a=3 order by c;
a用到了索引,但是这个地方c没有发挥排序效果,因为中间断点了,使用 explain 可以看到 filesort
(8) select * from mytable where b=3 order by a;
b没有用到索引,排序中a也没有发挥索引效果
索引算法
- BTree:BTree是最常用的mysql数据库索引算法,也是mysql默认的算法。因为它不仅可以被用在=,>,>=,<,<=和between这些比较操作符上,而且还可以用于like操作符,只要它的查询条件是一个不以通配符开头的常量
- Hash:Hash索引只能用于对等比较,例如=,<=>(相当于=)操作符。由于是一次定位数据,不像BTree索引需要从根节点到枝节点,最后才能访问到页节点这样多次IO访问,所以检索效率远高于BTree索引
- 区别:BTree索引不仅可以用在=,>,>=,<,<=和between这些比较操作符上,而且还可以用于like操作符,而Hash索引只能用于对等比较,例如=,<=>(相当于=)操作符
索引设计的原则是什么?
- 适合索引的列是出现在where子句中的列,或者连接子句中指定的列
- 基数较小的类,索引效果较差,没有必要在此列建立索引
- 使用短索引,如果长字符串列进行索引,应该指定一个前缀长度,这样能够节省大量索引空间
- 不用过度索引。索引需要额外的磁盘空间,并降低写操作的性能。在修改表内容的时候,索引会进行更新甚至重构,索引列越多,这个时间就会越长。所以只保持需要的索引有利于查询即可
如何定位和优化SQL语句的性能问题?
- 对于低性能的SQL语句的定位,最重要也是最有效的方法就是使用执行计划
- 我们知道,不管是哪种数据库或者哪种数据库引擎,在对一条SQL语句进行执行的过程中都会做很多相关的优化,对于查询语句,最重要的优化方式就是使用索引
- 而执行计划,就是显示数据库引擎对于SQL语句的执行的详细情况,其中包含是否使用索引,使用了什么索引,使用索引的相关信息等
执行计划:
定义:explain主要是用来获取一个query的执行计划,描述mysql如何执行查询操作、执行顺序,使用到的索引,以及mysql成功返回结果集需要执行的行数。可以帮助我们分析 select 语句,让我们知道查询效率低下的原因,从而改进我们的查询,让查询优化器能够更好的工作。

- id:包含一组数字,表示查询中执行select子句或操作表的顺序
id相同执行顺序由上至下。 id不同,id值越大优先级越高,越先被执行。 id为null时表示一个结果集,不需要使用它查询,常出现在包含union等查询语句中。 - select_type:表示每个子查询的查询类型,一些常见的查询类型
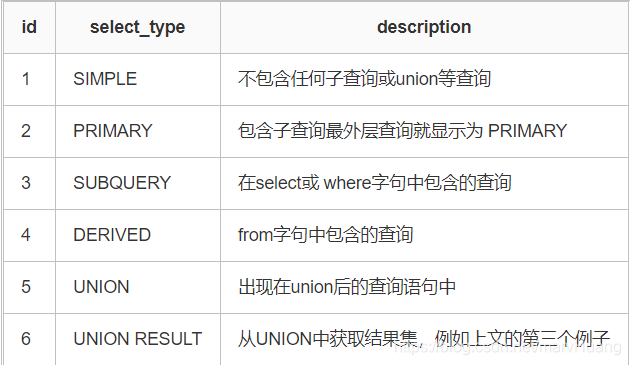
- table:显示的查询表名,如果查询使用了别名,那么这里显示的是别名,如果不涉及对数据表的操作,那么这显示为null,如果显示为尖括号括起来的
<derived N>就表示这个是临时表,后边的N就是执行计划中的id,表示结果来自于这个查询产生。如果是尖括号括起来的<union M,N>,与<derived N>类似,也是一个临时表,表示这个结果来自于union查询的id为M,N的结果集 - partitions:表分区、表创建的时候可以指定通过那个列进行表分区,例如:
create table tmp ( id int unsigned not null AUTO_INCREMENT, name varchar(255), PRIMARY KEY (id) ) engine = innodb partition by key (id) partitions 5; - type:表示MySQL在表中找到所需行的方式,又称“访问类型”,常见类型如下:

- possible_keys:可能使用的索引,注意不一定会使用。查询涉及到的字段上若存在索引,则该索引将被列出来。当该列为 NULL时就要考虑当前的SQL是否需要优化了
- key:在查询中实际使用的索引,若没有使用索引,显示为NULL
- key_len:用于处理查询的索引长度,如果是单列索引,那就整个索引长度算进去,如果是多列索引,那么查询不一定都能使用到所有的列,具体使用到了多少个列的索引,这里就会计算进去,没有使用到的列,这里不会计算进去。另外,key_len只计算where条件用到的索引长度,而排序和分组就算用到了索引,也不会计算到key_len中
- ref:表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值。如果是使用的常数等值查询,这里会显示const,如果是连接查询,被驱动表的执行计划这里会显示驱动表的关联字段,如果是条件使用了表达式或者函数,或者条件列发生了内部隐式转换,这里可能显示为func
- rows:执行计划中估算的扫描行数,不是精确值
- filtered:表示存储引擎返回的数据在server层过滤后,剩下多少满足查询的记录数量的比例,注意是百分比,不是具体记录数
- extra:可以显示的信息非常多,有几十种,常用的有:

某个表有近千万数据,CRUD比较慢,如何优化?分库分表了是怎么做的?分表分库了有什么问题?有用到中间件么?他们的原理知道么?
- 数据有千万级别之多,占用的存储空间比较大,可想而知它不会存储在一块连续的物理空间上,而是链式存储在多个碎片的物理空间。可能对于长字符串的比较,就用更多的时间查找和比较,这就导致用更多的时间。因此,优化方法有:
1、可以做表拆分,减少单表字段数量,优化表结构
2、在保证主键有效的情况下,检查主键索引的字段顺序,使得查询语句中条件的字段顺序和主键索引的字段顺序保持一致 - 垂直分表
垂直分表也就是“大表拆小表”,基于列字段进行的。一般是表中的字段较多,将不常用的, 数据较大,长度较长(比如text类型字段)的拆分到“扩展表“。 一般是针对那种几百列的大表,也避免查询时,数据量太大造成的“跨页”问题。
垂直分库针对的是一个系统中的不同业务进行拆分,比如用户User一个库,商品Producet一个库,订单Order一个库。 切分后,要放在多个服务器上,而不是一个服务器上。为什么? 我们想象一下,一个购物网站对外提供服务,会有用户,商品,订单等的CRUD。没拆分之前, 全部都是落到单一的库上的,这会让数据库的单库处理能力成为瓶颈。按垂直分库后,如果还是放在一个数据库服务器上, 随着用户量增大,这会让单个数据库的处理能力成为瓶颈,还有单个服务器的磁盘空间,内存,tps等非常吃紧。 所以我们要拆分到多个服务器上,这样上面的问题都解决了,以后也不会面对单机资源问题。
数据库业务层面的拆分,和服务的“治理”,“降级”机制类似,也能对不同业务的数据分别的进行管理,维护,监控,扩展等。 数据库往往最容易成为应用系统的瓶颈,而数据库本身属于“有状态”的,相对于Web和应用服务器来讲,是比较难实现“横向扩展”的。 数据库的连接资源比较宝贵且单机处理能力也有限,在高并发场景下,垂直分库一定程度上能够突破IO、连接数及单机硬件资源的瓶颈。 - 水平分表
针对数据量巨大的单张表(比如订单表),按照某种规则(RANGE,HASH取模等),切分到多张表里面去。 但是这些表还是在同一个库中,所以库级别的数据库操作还是有IO瓶颈。不建议采用,因此使用:
水平分库分表
将单张表的数据切分到多个服务器上去,每个服务器具有相应的库与表,只是表中数据集合不同。 水平分库分表能够有效的缓解单机和单库的性能瓶颈和压力,突破IO、连接数、硬件资源等的瓶颈
水平分库分表切分规则
1、RANGE从0到10000一个表,10001到20000一个表;
2、HASH取模:例如一个商场系统,一般都是将用户,订单作为主表,然后将和它们相关的作为附表,这样不会造成跨库事务之类的问题。 取用户id,然后hash取模,分配到不同的数据库上;
3、地理区域:比如按照华东,华南,华北这样来区分业务,七牛云应该就是如此;
4、时间:按照时间切分,就是将6个月前,甚至一年前的数据切出去放到另外的一张表,因为随着时间流逝,这些表的数据 被查询的概率变小,所以没必要和“热数据”放在一起,这个也是“冷热数据分离”; - 分库分表后面临的问题
- 事务支持:分库分表后,就成了分布式事务了。如果依赖数据库本身的分布式事务管理功能去执行事务,将付出高昂的性能代价; 如果由应用程序去协助控制,形成程序逻辑上的事务,又会造成编程方面的负担
- 跨库join:只要是进行切分,跨节点Join的问题是不可避免的。但是良好的设计和切分却可以减少此类情况的发生。解决这一问题的普遍做法是分两次查询实现。在第一次查询的结果集中找出关联数据的id,根据这些id发起第二次请求得到关联数据
- 跨节点的count,order by,group by以及聚合函数问题:这些是一类问题,因为它们都需要基于全部数据集合进行计算。多数的代理都不会自动处理合并工作。解决方案:与解决跨节点join问题的类似,分别在各个节点上得到结果后在应用程序端进行合并。和join不同的是每个结点的查询可以并行执行,因此很多时候它的速度要比单一大表快很多。但如果结果集很大,对应用程序内存的消耗是一个问题
- 数据迁移,容量规划,扩容等问题
- ID问题
- 一旦数据库被切分到多个物理结点上,我们将不能再依赖数据库自身的主键生成机制。一方面,某个分区数据库自生成的ID无法保证在全局上是唯一的;另一方面,应用程序在插入数据之前需要先获得ID,以便进行SQL路由
- 一些常见的主键生成策略
- UUID:使用UUID作主键是最简单的方案,但是缺点也是非常明显的。由于UUID非常的长,除占用大量存储空间外,最主要的问题是在索引上,在建立索引和基于索引进行查询时都存在性能问题
- Twitter的分布式自增ID算法Snowflake:在分布式系统中,需要生成全局UID的场合还是比较多的,twitter的snowflake解决了这种需求,实现也还是很简单的,除去配置信息,核心代码就是毫秒级时间41位 机器ID 10位 毫秒内序列12位
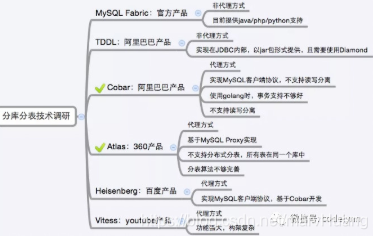
- 中间件推荐
mysql中in和exists 区别
- mysql中的in语句是把外表和内表作hash 连接,而exists语句是对外表作loop循环,每次loop循环再对内表进行查询
- 关于exists和in语句的效率比较,是要看情况的:
1、如果查询的两个表大小相当,那么用in和exists差别不大
2、如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in
3、not in 和not exists如果查询语句使用了not in 那么内外表都进行全表扫描,没有用到索引;而not extsts的子查询依然能用到表上的索引。所以无论那个表大,用not exists都比not in要快
文章参考:
https://www.cnblogs.com/fishlynn/p/9674793.html
https://blog.csdn.net/u012410733/article/details/66472157