一、HashMap的数据结构
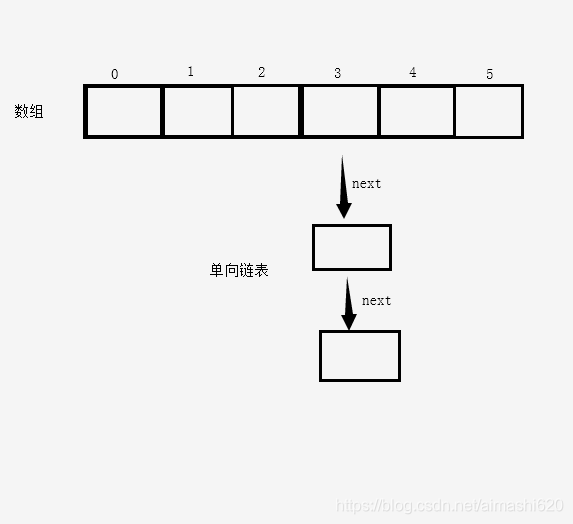
首先有一个数组,如果hashMap不进行扩容的话默认是16个长度的数组,如果有hash冲突的话会使用单向链表来解决冲突。
1.1 HashMap的存储结构
数组、链表、红黑树(jdk1.8)
HashMap中不单单只有数组结构,还有链表、红黑树
1.2 HashMap的特点
1.2.1 快速存储(put)
1.2.2 快速查找(时间复杂度O(1))(get)
1.2.3 可伸缩(数组可以边长;单向链表长度超过8以后可以变成红黑树)
二、Hash算法(HashMap的核心)
要了解HashMap底层执行原理必须了解HashMap的核心–hash算法
2.1 Hash算法
所有的Java对象(Object.hashCode可以得到一个hash值)都有hashCode(hashMap中使用对象的hashCode去计算hash值)
具体的hash值的计算方法:(hashCode)^(hashCode>>>16)
这样算可以确保得出的数足够的随机、分散(算数组下标的时候要使用这个hash值,hash值足够的随机、分散才能保证算出的数组下标的值足够的分散)。
2.2 数组下标计算
hashMap底层是数组组成的,数组的默认大小是16,数组的下标是如何计算的呢
使用2.1计算出来的hash值再进行运算计算出来的:hash%16
HashMap中算下标的方式:hash&(16-1) 这样的效率会更高
三、Hash冲突
原因:不同的对象计算出来数组下标是相同的
单向链表:用于解决Hash冲突的方案,加入一个next记录下一个节点。如果链表非常长的话,效率是非常低的,所以在jdk1.8之后采用了红黑树。
三、HashMap扩容
HashMap底层是用数组存储数据的,数组存储的话不可能所有的数组存满16以后就变成链表,上面说了链表过长会影响效率,链表只是为了解决冲突准备的。
数组扩容的原理:存储量达到75% (一个数组有16个长度,75%大概就是12个长度)就对数组进行扩容,由于计算机里都是二进制的,所以扩容的标准是最好是变长2倍。75%是基于时间与空间的考虑,如果扩容比例设得很小,例如是50%,那么有一半的空间是浪费的,如果比例设置得很高,例如是90%,当发生hash冲突的时候很难去触发这个条件。
四、红黑树
红黑树是一种二叉树,有着高效的检索效率
触发条件:在链表的长度大于8的时候,将后面的数据存在红黑树中 。当链表的长度小于6的时候,又会把红黑树转化成链表