前言
经典的链表应用场景:LRU 缓存淘汰算法
缓存是一种提高数据读取性能的技术,由于缓存的大小有限,当缓存被用满时,哪些数据应该被清理出去,哪些数据应该被保留?这就需要缓存淘汰策略来决定。
- 常见的策略有三种:
- 先进先出策略 FIFO(First In,First Out)
- 最少使用策略 LFU(Least Frequently Used)
- 最近最少使用策略 LRU(Least Recently Used)
==》如何用链表来实现 LRU 缓存淘汰策略呢? ==》详见 五 的解答
一、链表
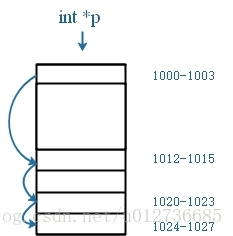
链表:不需要一块连续的内存空间,它通过“指针”将一组零散的内存块串联起来使用.
内存分布:
最常用的链表结构:单链表、双向链表和循环链表
二、单链表
1、基本概念
结点(Node):单链表的结点结构
链表中的每一个数据元素称为 “结点” ,每个结点都由两部分组成:数据域 + 指针域。其中,数据域存储数据元素信息,指针域存储链表的下一个结点的位置信息,是一个指针。

单链表:当一个序列中只含有指向它的后继结点的链接时,就称该链表为单链表。
- 非空表(有头结点):
- 空表:

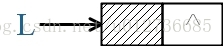
头指针:是指链表指向第一个结点的指针,若链表有头结点,则是指向头结点的指针。头指针具有标识作用。任何情况下,头指针都存在,无论链表是否为空。
头结点:为了操作的统一和方便(插入/删除首元结点)设立的,放在首元结点(第一元素结点)之前,其数据域一般无意义(也可以 存放链表的长度)。非必需要素。
最后一个结点:最后一个结点指针为“空”(通常用NULL或“^”符号表示),是链表的结束标志,表示它没有后继结点。
2、查找操作
目标:随机访问第 k 个元素 ==》依次遍历 ==》时间复杂度:O(n)
3、插入操作
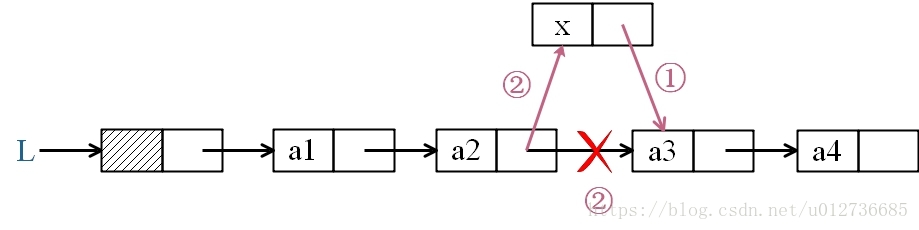
插入 x 结点: ==》时间复杂度:O(1)
① x->next = a2 -> next
② a2 -> next = x
4、删除操作
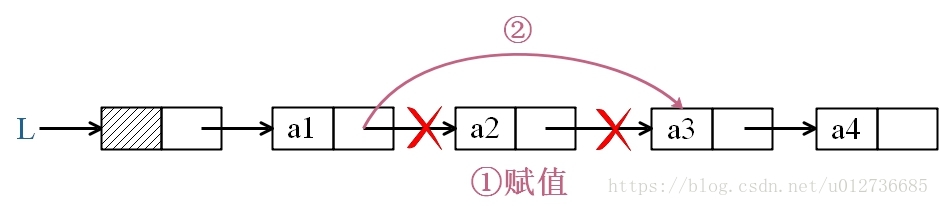
删除 a2 结点: ==》时间复杂度:O(1)
① p = a1->next
② a1->next = p->next
三、循环链表
循环链表:与单链表的唯一区别就是最后一个结点的指针指向链表的头结点。

四、双向链表
双向链表:每个结点不止有一个后继指针 next 指向后面的结点,还有一个前驱指针 prev 指向前面的结点。
特点:支持双向遍历,更具灵活性;O(1) 时间复杂度的情况下前驱结点
结点:


2、双向链表的优势
(1)删除
删除的两种情况:
- 删除结点中“值等于某个给定值”的结点
- 删除给定指针指向的结点
第一种情况
无论单链表还是双向链表,均需要从头开始遍历对比,直至找到值等于给定值的结点,然后再执行删除操作。==》时间复杂度:O(n)
第二种情况
已找到需删除的结点,但是删除某个结点 q 需要得到其前驱结点,双向链表可以不用遍历就得到前驱结点。 ==》时间复杂度:O(1)
(2)有序链表的查找操作
对于有序链表,双向链表的按值查询的效率要比单链表高一些。具体来说,可以记录上次查找的位置 p ,每次查找时,根据查询值与 p 的大小关系,决定向前还是向后查找。
五、设计思想:空间 <-> 时间
- 当内存足够时,若追求代码的执行速度 ==》选择空间复杂度高、时间复杂度相对较低的算法或者数据结构
- 当内存比较紧张 ==》时间换空间
链表实现LRU缓存淘汰算法:越靠近链表尾部的结点是越早之前访问的
- 若此数据之前就在缓存链表中,遍历得到该数据所对应的结点,并将其从原来的位置删除,然后插入到链表的头部。
- 若此数据没在缓存链表中,具体分为以下两种情况:
- 若此时缓存未满 ==》此结点直接插入到链表的头部;
- 若此时缓存已满,则链表的最后一个结点删除,并将新的数据结点插入链表的头部