1、先于main函数执行的函数或语句,以及在main函数之后会被执行的语句。
全局对象(会调用它的构造函数)在main函数之前执行,全局对象的生命周期跨越整个程序的运行时间,优先于main函数被调用,同样,全局对象(会调用它的析构函数),在main函数之后执行,会在main执行完毕之后被调用。
给段代码演示一下:
#include< iostream>
#include< cstdlib>
using namespace std;
int x;
class A
{
public:
A()
{
cout<<“A 构造函数”<<endl;
cout<<“x=”<<x<<endl;
}
~A()
{
cout<<“A 析构函数”<<endl;
}
};
//A a;把这个放在main函数后面的结果是一样的
int main()
{
cout<<“进入主函数”<<endl;
cout<<“离开主函数”<<endl;
return 0;
}
A a; //看这里
运行结果:
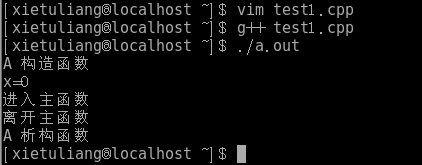
2、获取0~n之间m个不相同的随机数(n>m,且每个n中数出现的概率相等,这m个数都不相同,也就是说m中每个元素的值都不能相同)。
这个问题让我想到了棋牌算法,有两种方法:
方法一:
先直接得到一个随机数,并把它直接赋给对应位置的数组元素,然后再与数组中前面元素的值进行比较,若相等,则把该位置元素对应的下标的值重新rand,重复这个步骤,最后重复上面这个步骤直到找足m个数组元素
对应的代码:
#include< iostream>
#include< cstdlib>
#include< ctime>
using namespace std;
int main()
{
int A[20],i;
srand((unsigned)time(NULL));
for(i=0;i<20;i++)
{
A[i]=rand()%100;
for(int j=0;j<i;j++)
if(A[i]==A[j])
{
i–;
break;
}
}
cout<<“得到20个[0,100)之间的(互不相等)随机数”<<endl;
for(int i=0;i<20;i++)
cout<<A[i]<<" “;
cout<<endl;
return 0;
}
运行的结果:

程序分析:这种方法不是很好,但很好理解,因为当n的值很大的时候,每次判断A[i]的值与前面的是否相等就要花费很多时间,且开销大,它的算法复杂度为n*m。下面再介绍第二种方法。
方法二:
初始化一个整型数组100,每个元素的值等于其索引值(0~99),采用随机调换位置的方法将A[rand()%100]与A[i]的值进行调换,循环一次调换第i个和随机出来的索引位置的元素值(相当于洗牌)。最后随便取其中20个元素。
实现代码:
#include< iostream>
#include< cstdlib>
#include< ctime>
using namespace std;
int main()
{
int a[100];
for(int i=0;i<100;i++)
a[i]=i;
srand((unsigned)time(NULL));
for(int i=0;i<20;i++)
{
int tmp=a[rand()%100];
a[rand()%100]=a[i];
a[i]=tmp;
}
for(int i=0;i<20;i++)
cout<<a[i]<<” ";
cout<<endl;
return 0;
}
实验结果:
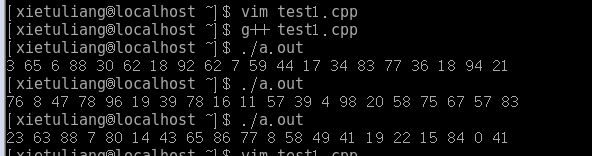
代码分析:
这种方法的算法复杂度为m,比第一种要高很多,值得推荐。
c++面试笔记2(关于main和获取不重复的随机数)
猜你喜欢
转载自blog.csdn.net/qq_37012376/article/details/84829411
今日推荐
周排行