Hive支持的文件存储格式有
-
TEXTFILE
-
SEQUENCEFILE
-
RCFILE
-
Parquet
-
ORCFile
-
自定义格式
在建表的时候,可以使用STORED AS子句指定文件存储的格式。一般情况下,先建立一张存储格式为TEXTFILE的表,然后建立一张同类型、存储格式不同(ORC/PARQUET)的表,一方面实现数据压缩,另外增加查询效率。
TEXTFILE
即通常说的文本格式,默认长期,数据不做压缩,磁盘开销大、数据解析开销大。
SEQUENCEFILE
Hadoop提供的一种二进制格式,使用方便、可分割、可压缩,并且按行进行切分
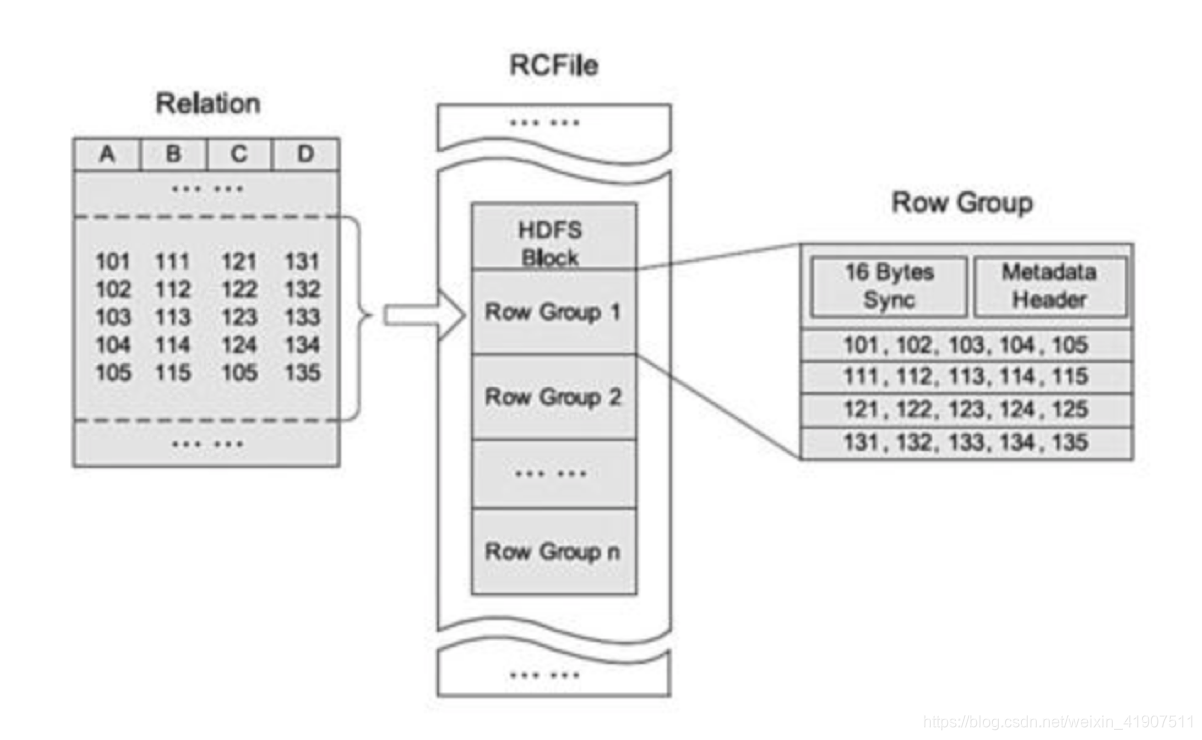
RCFILE
一种行列存储相结合的存储方式,首先,其将数据按行分块,保证同一条记录在一个块上,避免读一条记录涉及多个块。
其次,块上的数据按照列式存储,有利于数据压缩和快速地进行列存取。
ORCFile
ORC是在一定程度上扩展了RCFile,是对RCFile的优化。
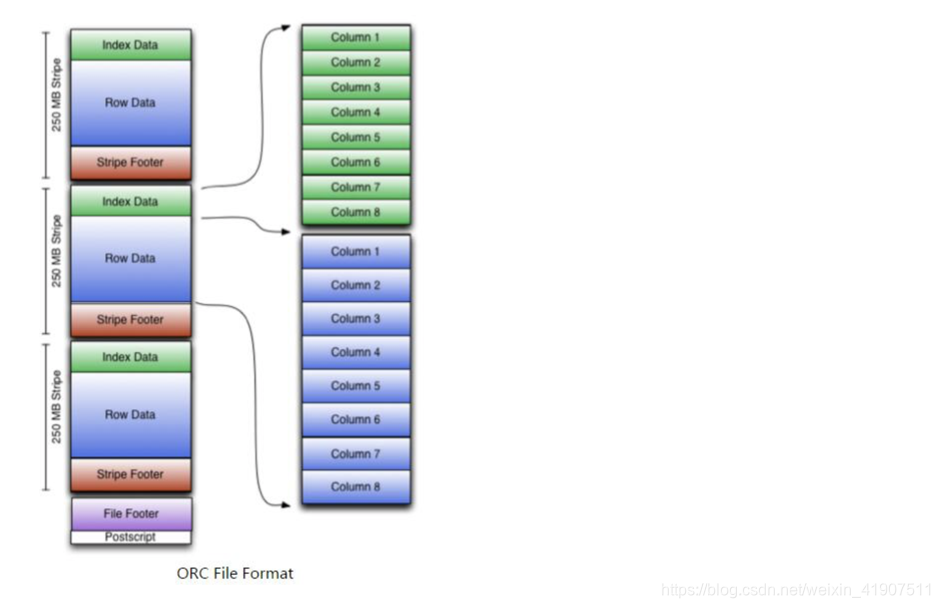 根据结构图,我们可以看到ORCFile在RCFile基础上引申出来Stripe和Footer等。每个ORC文件首先会被横向切分成多个Stripe,而每个Stripe内部以列存储,所有的列存储在一个文件中,而且每个stripe默认的大小是250MB,相对于RCFile默认的行组大小是4MB,所以比RCFile更高效。
根据结构图,我们可以看到ORCFile在RCFile基础上引申出来Stripe和Footer等。每个ORC文件首先会被横向切分成多个Stripe,而每个Stripe内部以列存储,所有的列存储在一个文件中,而且每个stripe默认的大小是250MB,相对于RCFile默认的行组大小是4MB,所以比RCFile更高效。create table Addresses (
name string,
street string,
city string,
state string,
zip int
) stored as orc tblproperties (“orc.compress”=“NONE”);
orc存储格式的压缩形式包括:NONE, ZLIB, SNAPPY,默认情况下(不添加tblproperties (“orc.compress”=“NONE”)),orc选择ZLIB压缩形式,开发中经常采用SNAPPY压缩形式。
Parquet
Parquet是面向分析型业务的列式存储格式,具有高压缩比,Spark已经将Parquet设为默认的文件存储格式,Cloudera投入了很多工程师到Impala+Parquet相关开发中,Hive/Pig都原生支持Parquet。Parquet现在为Twitter至少节省了1/3的存储空间,同时节省了大量的表扫描和反序列化的时间。
> CREATE TABLE employee_par_snappy //创建子表
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY '\t'
> STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY') //设置压缩形式
>AS select * from employee;
自定义文件格式
用户通过实现InputFormat和OutputFormat来自定义输入输出格式。