zookeeper的简介
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
ZooKeeper包含一个简单的原语集, [1] 提供Java和C的接口。
ZooKeeper代码版本中,提供了分布式独享锁、选举、队列的接口,代码在zookeeper-3.4.3\src\recipes。其中分布锁和队列有Java和C两个版本,选举只有Java版本。(以上介绍来自百度百科)
工作原理图解
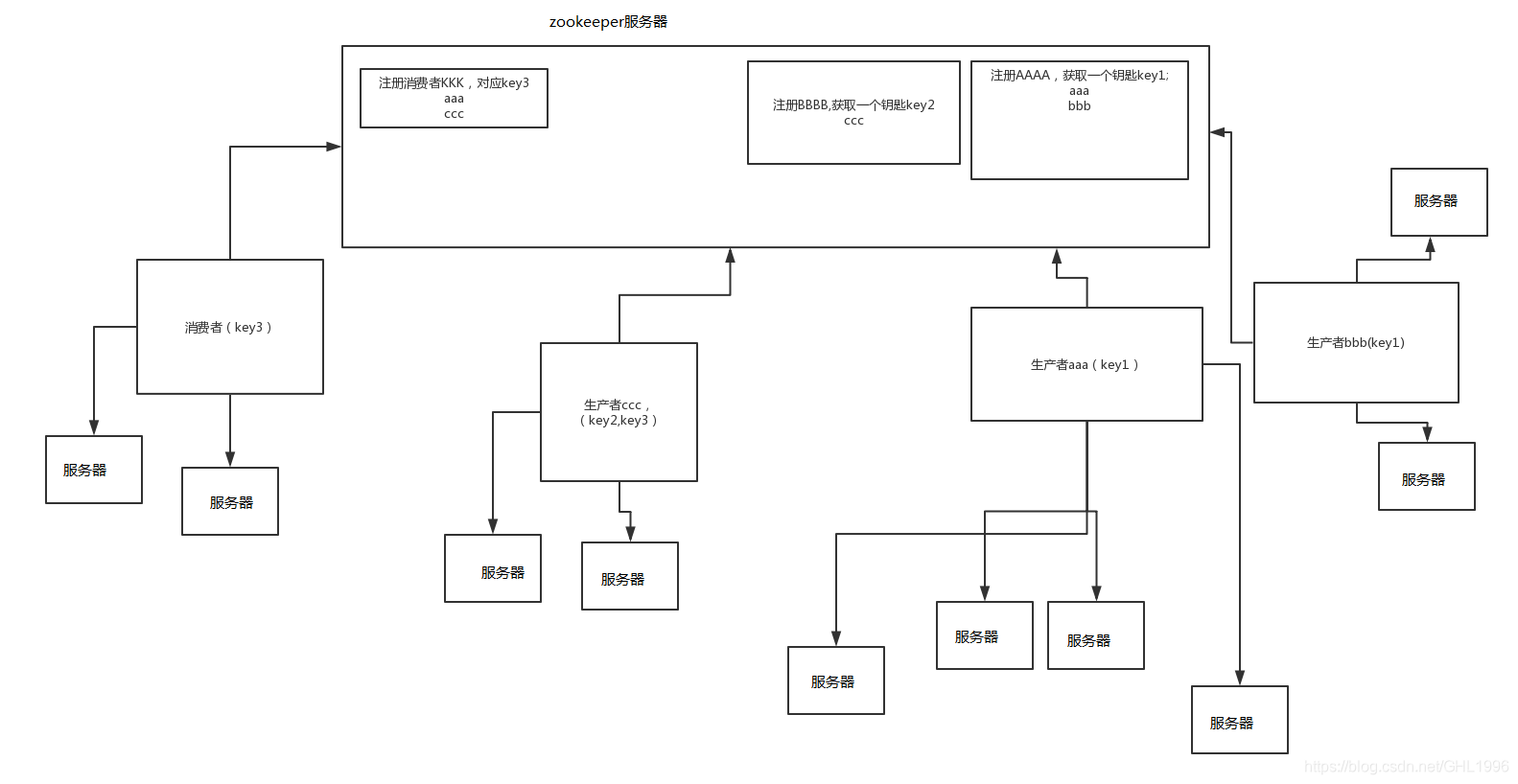
工作原理简介
-
zookeeper服务器相当于一个中介,把生产者的服务提供给消费者。
-
生产者相当于提供服务的一方,生产者写。好自己的服务后在zookeeper服务器上注册一下,会获得一个带有自己标识的key,然后zookeeper服务器就能加载到这个生产者所提供的服务列表,当生产者的某台服务器宕机时,zookeeper服务器会更新到,然后更新此生产者服务列表。
-
消费者就是使用某些服务的一方,消费者在zookeeper服务器上注册自己的信息也会获得一个key,当消费者需要生产者的某个服务是,就回去zookeeper获取相应生产者的key然后加载到相应的服务列表。
当次消费者第二次访问这个生产者的服务时,就会直接访问生产者的服务器。
关于消费者第二次及以后访问某个生产者服务时发生的问题解析
消费者第二次及以后访问某个生产者的服务时,是直接访问生产者的服务器的,但是当生产者的那台服务器正好宕机了,此时该怎么办呢?
解析 当生产的服务器宕机后,消费者继续请求那台服务器时,如果请求失败,消费者会继续请求第二次,当后续请求也失败时,消费者就会请求zookeeper服务器来更新此生产者所提供的服务列表。