Zookeeper 工作原理(原子广播协议Zab)
-
Zookeeper 的核心是原子广播,这个机制保证了各个 server 之间的同步。实现这个机制的协议叫做 Zab 协议。Zab 协议有两种模式,它们分别是恢复模式和广播模式。
-
当服务启动或者在领导者崩溃后,Zab 就进入了恢复模式,当领导者被选举出来,且大多数 server 的完成了和 leader 的状态同步以后,恢复模式就结束了。
-
状态同步保证了 leader 和 server 具有相同的系统状态
-
一旦 leader 已经和多数的 follower 进行了状态同步后,他就可以开始广播消息了,即进入广播状态。这时候当一个 server 加入 zookeeper 服务中,它会在恢复模式下启动,发现 leader,并和 leader 进行状态同步。待到同步结束,它也参与消息广播。Zookeeper服务一直维持在 Broadcast 状态,直到 leader 崩溃了或者 leader 失去了大部分的 followers 支持。
-
广播模式需要保证 proposal 被按顺序处理,因此 zk 采用了递增的事务 id 号(zxid)来保证。所有的提议(proposal)都在被提出的时候加上了 zxid。
-
实现中 zxid 是一个 64 为的数字,它高 32 位是 epoch 用来标识 leader 关系是否改变,每次一个 leader 被选出来,它都会有一个新的 epoch。低 32 位是个递增计数。
-
当 leader 崩溃或者 leader 失去大多数的 follower,这时候 zk 进入恢复模式,恢复模式需要重新选举出一个新的 leader,让所有的 server 都恢复到一个正确的状态。
Znode 有四种形式的目录节点
-
PERSISTENT:持久的节点。
-
EPHEMERAL:暂时的节点。
-
PERSISTENT_SEQUENTIAL:持久化顺序编号目录节点。
-
EPHEMERAL_SEQUENTIAL:暂时化顺序编号目录节点。
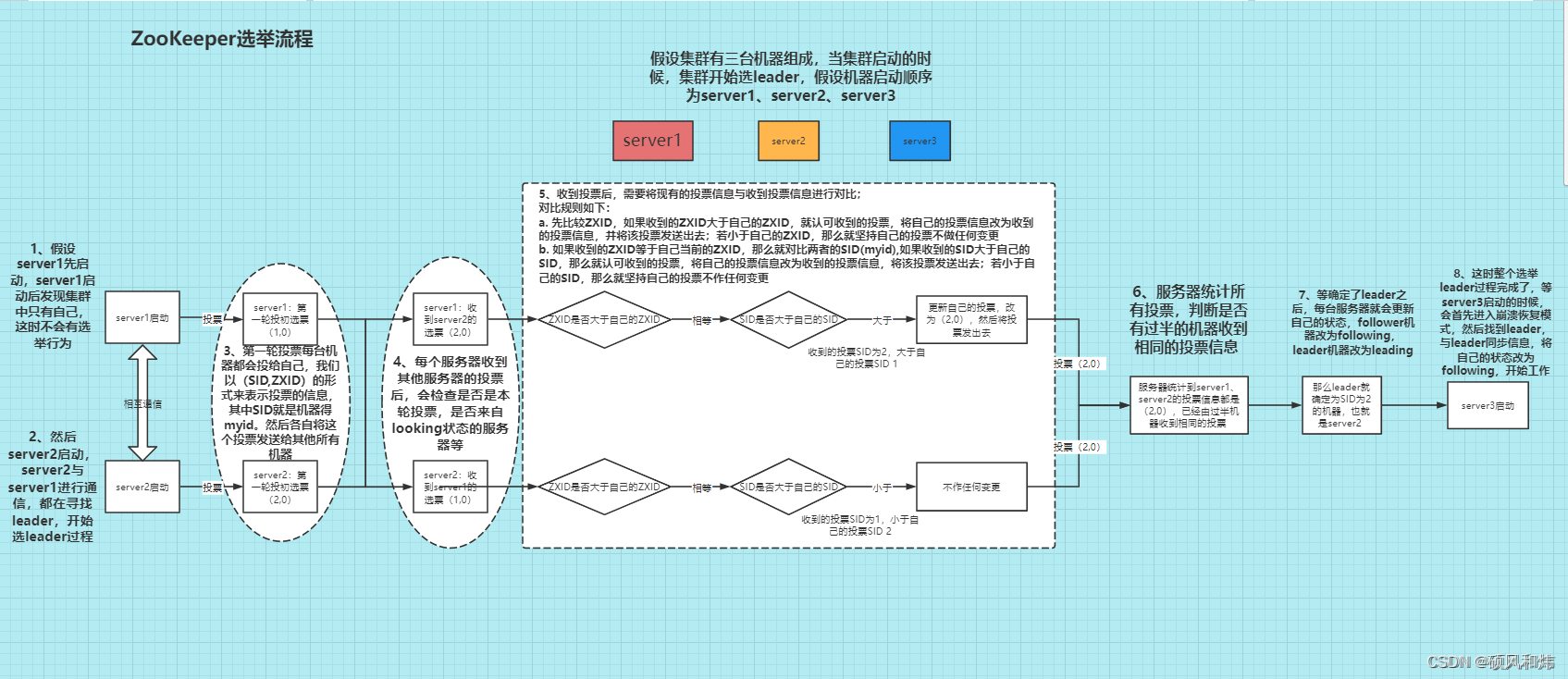
Zookeeper集群的选举机制
请看我的这篇博客:【Zookeeper集群的选举机制&&Zookeeper服务器的状态】