文章目录
1. 关于list
1.1 首先在介绍list之前先来观察一下list的节点结构:
template <class T>
struct __list_node {
typedef void* void_pointer;
void_pointer prev;
void_pointer next;
T data;
};
- 从上述节点结构很清楚list是一个双向链表
1.2 与vector的区别
- 相比于vector的连续线性空间,list显得更为复杂;但list每次插入或删除一个元素时,就将对应的空间释放掉,因此,对于任何位置的插入或元素删除,list永远是常数时间
2. list的迭代器
- list中的元素由于都是节点,因此其迭代器递增时取用的是下一个节点,递减时取用上一个节点,取值时取的是节点的数据值,成员取用时取用的是节点的成员
- 由于list是双向链表,迭代器必须具备前移、后移的能力,因此,list提供的是Bidirectional Iterators
- 关于list的迭代器的设计,大抵就是递增、递减运算符、取值以及比较运算符的重载,在这就不细说
3. list的数据结构
- list是一个双向链表,而且是一个环状双向链表:
//取首元素,node是尾端的一个空节点
iterator begin() { return (link_type) ((*node).next); }
//取尾元素的下一个,即node
iterator end() { return node; }
//为空,说明只有node
bool empty() const { return node->next == node; }
size_type size() const {
size_type result = 0;
distance(begin(), end(), result);
return result;
}
reference front() { return *begin(); }
reference back() { return *(--end()); }
- 可见,STL将node作为一个空节点放在尾端,与首元素、尾元素相连,形成一个环
4. list内存构造
- 还是老样子,以实例说明:
#include <iostream>
#include <list>
#include <algorithm>
using namespace std;
int main(int argc, char** argv) {
list<int> ilist;
cout << "size = " << ilist.size() << endl; //size = 0
ilist.push_back(0);
ilist.push_back(1);
ilist.push_back(2);
ilist.push_back(3);
ilist.push_back(4);
cout << "size = " << ilist.size() << endl; //size = 5
list<int>::iterator ite;
for (ite = ilist.begin(); ite != ilist.end(); ++ite)
cout << *ite << ' '; //0 1 2 3 4
cout << endl;
return 0;
}
- 当创建一个list时,调用list的默认构造函数构造一个空list:
public:
list() { empty_initialize(); } //默认构造函数
protected:
void empty_initialize() {
node = get_node(); //配置一个节点空间
node->next = node;
node->prev = node;
}
//既然说到配置空间,就将配置、释放、构造、销毁一并提了吧
//配置一个节点
link_type get_node() { return list_node_allocator::allocate(); }
//释放一个节点
void put_node(link_type p) { list_node_deallocator::deallocate(p); }
//产生一个节点,带有元素值
link_type create_node(const T& x) {
link_type p = get_node();
construct(&p->data, x);
return p;
}
//销毁一个节点
void destroy_node(link_type p) {
destroy(&p->data);
put_node(p);
}
- 其中push_back一个元素,实则调用insert(与指针插入节点一样)
5. list的元素操作:
| 操作 | 功能 |
|---|---|
| push_front | 插入一个节点作为头节点 |
| push_back | 插入一个节点作为尾节点 |
| erase | 删除迭代器所指的节点 |
| pop_front | 移除头节点 |
| pop_back | 移除尾节点 |
| clear | 清除整个链表 |
| remove | 移除某个元素 |
| unique | 删除连续相同的元素的重复项 |
| splice | 将迭代器所指元素或链表接合于目的迭代器之前 |
| merge | 将两个链表合并 |
| reverse | 将链表逆置 |
| sort | 排序 |
- 以下重点理解下transfer以及sort:
- transfer:
// 将 [first,last) 内的所有元素搬移到 position 之前
void transfer(iterator position, iterator first, iterator last)
{
if (position != last) // 如果last == position, 则相当于链表不变化, 不进行操作
{
(*(link_type((*last.node).prev))).next = position.node; //(1)
(*(link_type((*first.node).prev))).next = last.node; //(2)
(*(link_type((*position.node).prev))).next = first.node; //(3)
link_type tmp = link_type((*position.node).prev); //(4)
(*position.node).prev = (*last.node).prev; //(5)
(*last.node).prev = (*first.node).prev; //(6)
(*first.node).prev = tmp; //(7)
}
}
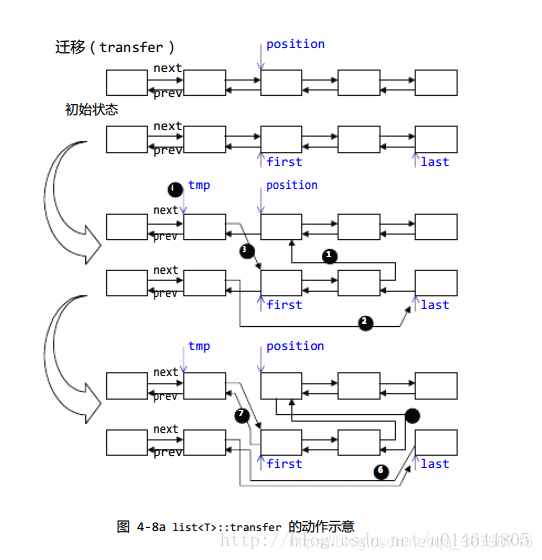
- 理解了上述transfer的操作,splice、merge、reverse也就迎刃而解
- sort:这个sort源码虽然不长,但理解起来却是最为费劲的
废话不多说,让我们来一起解析它:
//侯捷老师在本书中讲解本函数使用quick sort
//但看过该段源码的都知道不是使用quick sort,而是merge sort,这应该是一处错误吧
template <class T, class Alloc>
void list<T, Alloc>::sort() {
//如果是空链表或仅有一个元素,不进行任何操作
if (node->next == node || link_type(node_next)->next == node)
return;
list<T, Alloc> carry;
list<T, Alloc> counter[64]; //维护数组,最大一层可存储2 ^64 - 1个元素
int fill = 0;
while (!empty())
{
//每次取出list中的一个元素
carry.splice(carry.begin(), *this, begin());
int i = 0;
while (i < fill && !counter[i].empty()) {
counter[i].merge(carry); //将当前carry与count[i]中的数据归并
carry.swap(counter[i++]); //交换carry与count[i]中的数据
}
carry.swap(counter[i]); //将count[i]中的数据存入count[i+1]中
if (i == fill)
++fill;
}
for (int i = 1; i < fill; ++i)
counter[i].merge(counter[i - 1]);
swap(counter[fill - 1]);
}
具体分析:假定list中元素为45,21,1,35,28,3,6,75
则此时调用sort,逐步进行分析:
fill = 0,carry = 45,此时i<fill,执行swap,则此时counter[0]中存有元素45 i = fill,fill = 1fill = 1,carry = 21,此时i被重置为0,进入while循环,执行merge语句得到counter[0]{21,45},进行swap,carry{21,45},出循环,再swap得counter[1]{21,45},i= fill,fill=2fill = 2,carry = 1,此时i被重置为0,但此时counter[0]为空,则跳过while执行外层swap得counter[0]{1}fill = 2,i = 0,carry = 35,i < fill并且counter[0]不为空,进入while,执行merge得counter[0]{1,35},swap得到carry{1,35},此时i<fill继续,i= 2,merge得counter[1]{1,21,35,45},swap得到carry{1,21,35,45},i= fill,出while得counter[2]{1,21,35,45},i = fill, fill = 3....经过上面的分析,我们发现每次counter[i]达到2^(i+1)个元素时,会转给counter[i+1],因此可以得出当counter[2]达到8个元素时,会转给counter[3]得到counter[3]{1,3,6,21,28,35,45,75}
1.其实我们观察,不难发现counter[64]数组每层最多维护2^(n) 个元素(n从0开始),则不难得出count[64]最多一次能处理2^64 -1个元素
2.看完上述大概就能理解为何是一个归并排序,即每次两个元素merge完放入下一层中进行merge,然后4个再进入下一层merge,如此得到merge好的8个、16个…元素,实现一个归并排序