1. 流式api(DataStream API)
1.1. 样例程序
下面是一个窗口函数计算wordcount,每5秒计算一次数据,数据从websocket发送过来。
l 先在192.168.56.204机器上启动websocket:nc -lk 9999
l Java
package org.apache.flink.streaming;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
/**
* Created by wangsenfeng on 2017/11/15.
*/
public class WordCountStreamingJava {
public static void main(String[] args) throws Exception {
//初始化环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
//监听192.168.56.204的9999端口发过来的数据流,每5秒进行一次处理
DataStream<Tuple2<String, Integer>> dataStream = env
.socketTextStream("192.168.56.204", 9999)
.flatMap(new Splitter())
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1);
//打印数据到控制台
dataStream.print();
//开启streaming程序
env.execute("Window WordCount");
}
public static class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String sentence, Collector<Tuple2<String, Integer>> out) throws Exception {
for (String word : sentence.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
l Scala
package org.apache.flink.streaming
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
/**
* Created by wangsenfeng on 2017/11/15.
*/
object WordCountStreaming {
def main(args: Array[String]) {
//初始化环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//监听
val text = env.socketTextStream("192.168.56.204", 9999)
//每5秒计算
val counts = text.flatMap(_.toLowerCase.split(" ")
.filter(_.nonEmpty))
.map((_, 1))
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1)
//打印
counts.print
//开启
env.execute("Window Stream WordCount")
}
1.2. 算子DataStream Transformations
详情参考:
https://ci.apache.org/projects/flink/flink-docs-release-1.3/dev/datastream_api.html#top
l 一般的transformation

l 特殊的transformation

1.3. 数据源Data Sources
Flink可以通过StreamExecutionEnvironment.addSource(sourceFunction)加载数据源,并且flink提供了很多预先实现好的sourceFunction,你也可以通过继承RichParallelSourceFunction或者实现接口ParallelSourceFunction来实现自己的SourceFunction。
以下是一些实现好的数据读取方法,使用StreamExecutionEnvironment访问
l File-based:
- readTextFile(path) -读取文本文件,即尊重TextInputFormat规范的文件,逐行并将它们作为字符串返回。
- readFile(fileInputFormat, path) -读取(一次)文件,由指定的文件输入格式指定。
- readFile(fileInputFormat, path, watchType, interval, pathFilter, typeInfo) -这是前两个方法内部调用的方法。它根据给定的fileInputFormat来读取路径中的文件。根据watchType提供,这源可能定期监测(每间隔ms)新数据的路径(FileProcessingMode.PROCESS_CONTINUOUSLY),或过程一旦数据目前路径和退出(FileProcessingMode.PROCESS_ONCE)。使用pathFilter,用户可以进一步排除正在处理的文件。
l Socket-based:
- socketTextStream - Reads from a socket. 元素可以由分隔符分隔.
l Collection-based:
- fromCollection(Collection) -从Java Java.util.collection创建一个数据流。集合中的所有元素必须是相同类型的.
- fromCollection(Iterator, Class) -从迭代器创建数据流。该类指定迭代器返回的元素的数据类型.
- fromElements(T ...) -从给定的对象序列中创建一个数据流。所有对象都必须是相同类型的.
- fromParallelCollection(SplittableIterator, Class) -并行地从迭代器创建数据流。该类指定迭代器返回的元素的数据类型.
- generateSequence(from, to) -在给定的时间间隔内生成数字序列。
l Custom(自定义):
addSource - Attache a new source function. For example, to read from Apache Kafka you can use addSource(new FlinkKafkaConsumer08<>(...)). See connectors for more details.
1.4. 数据输出Data Sinks
- writeAsText() / TextOutputFormat -将元素作为字符串写入行。字符串是通过调用每个元素的toString()方法获得的
- writeAsCsv(...) / CsvOutputFormat -将元组写为逗号分隔值文件。行和字段分隔符是可配置的。每个字段的值都来自对象的toString()方法。
- print() / printToErr() -打印标准输出/标准错误流中的每个元素的toString()值。可选地,可以提供前缀(msg),这是对输出进行预先设置的。这可以帮助区分不同的打印请求。如果并行度大于1,输出也将被预先处理生成输出的任务的标识符。
- writeUsingOutputFormat() / FileOutputFormat -用于定制文件输出的方法和基类。支持自定义object-to-bytes转换.
- writeToSocket -根据序列化模式将元素写入套接字
- addSink -调用一个自定义沉没函数。Flink与其他系统(比如Apachekafka)绑定在一起,这些系统被实现为沉没功能。
2. Table api
https://ci.apache.org/projects/flink/flink-docs-release-1.3/dev/table/index.html
2.1. 样例程序
2.1.1. 从scv文件注册表
package org.apache.flink.table;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.core.fs.FileSystem;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.api.java.BatchTableEnvironment;
import org.apache.flink.table.sinks.CsvTableSink;
import org.apache.flink.table.sources.CsvTableSource;
import org.apache.flink.table.sources.TableSource;
/**
* Created by wangsenfeng on 2017/11/29.
*/
public class BatchTableFromCsvFile {
public static void main(String[] args) throws Exception {
//创建batch环境
ExecutionEnvironment bEnv = ExecutionEnvironment.getExecutionEnvironment();
// 创建table环境用于batch查询
BatchTableEnvironment bTableEnv = TableEnvironment.getTableEnvironment(bEnv);
//将外部的csv文件直接注册成表
TableSource csvTableSource = CsvTableSource
.builder()
.path("file:///f:/person.csv")//文件路径
.field("id", Types.INT)//第一列
.field("name", Types.STRING)//第二列
.field("age", Types.INT)//第三列
.fieldDelimiter(",")//列分隔符,默认是逗号
.lineDelimiter("\n")//行分隔符,回车
.ignoreFirstLine()//忽略第一行
.ignoreParseErrors()//忽略解析错误
.build();//构建
//将csv文件注册成表
bTableEnv.registerTableSource("mytable", csvTableSource);
//查询
Table sqlResult = bTableEnv.sql("select id,name,age from mytable where id > 0 order by id limit 2");
//将数据写出去
sqlResult.writeToSink(new CsvTableSink("file:///f:/aaaaaa.csv", ",", 1, FileSystem.WriteMode.OVERWRITE));
//执行
bEnv.execute();
}
}
2.1.2. 从dataset转换成表
package org.apache.flink.table;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.core.fs.FileSystem;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.api.java.BatchTableEnvironment;
import org.apache.flink.table.sinks.CsvTableSink;
import org.apache.flink.util.Collector;
/**
* Created by wangsenfeng on 2017/11/29.
*/
public class BatchTableSql {
public static void main(String[] args) throws Exception {
/**
* batch
*/
//创建batch环境
ExecutionEnvironment bEnv = ExecutionEnvironment.getExecutionEnvironment();
// 创建table环境用于batch查询
BatchTableEnvironment bTableEnv = TableEnvironment.getTableEnvironment(bEnv);
//从文件系统加载数据,并将数据处理成符合表结构的数据
DataSet<Tuple3<String, String, String>> batchData = bEnv.readTextFile("file:///c:/person.txt").flatMap(new LineSplitter());
//注册表和表结构
bTableEnv.registerDataSet("myTable", batchData, "id,name,age");
//查询
Table sqlResult = bTableEnv.sql("select id from myTable where id > 0 order by id limit 2");
//将数据写出去
sqlResult.writeToSink(new CsvTableSink("file:///f:/aaaaaa.csv", ",", 1, FileSystem.WriteMode.OVERWRITE));
//执行
bEnv.execute();
}
//分割字符串的方法
public static class LineSplitter implements FlatMapFunction<String, Tuple3<String, String, String>> {
@Override
public void flatMap(String line, Collector<Tuple3<String, String, String>> out) {
Tuple3<String, String, String> t3 = new Tuple3<String, String, String>();
String[] split = line.split(" ");
for (int i = 0; i < split.length; i++) {
t3.setField(split[i], i);
}
out.collect(t3);
}
}
}
2.1.3. 从datastream转换成表
package org.apache.flink.table;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.core.fs.FileSystem;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.api.java.StreamTableEnvironment;
import org.apache.flink.table.sinks.CsvTableSink;
import org.apache.flink.util.Collector;
/**
* Created by wangsenfeng on 2017/11/29.
*/
public class StreamTableSQL {
public static void main(String[] args) throws Exception {
/**
* streaming
*/
//创建stream环境
StreamExecutionEnvironment sEnv = StreamExecutionEnvironment.getExecutionEnvironment();
// 创建Table环境用于streaming查询
StreamTableEnvironment sTableEnv = TableEnvironment.getTableEnvironment(sEnv);
//接收流式数据,并处理成符合表的列,source步骤
DataStream<Tuple3<String, String, String>> dataStream = sEnv.socketTextStream("192.168.56.151", 9999).flatMap(new LineSplitter());
//将数据注册成表,并带上表的结构
sTableEnv.registerDataStream("myTable", dataStream, "id,name,age");
//查询语句,相当于transformation
Table sqlResult = sTableEnv.sql("select id,name,age from myTable where id > 0");
//将结果保存,sink步骤
sqlResult.writeToSink(new CsvTableSink("file:///f:/bbb.csv", ",", 1, FileSystem.WriteMode.OVERWRITE));
//执行程序
sEnv.execute();
}
/**
* 将就收到的字符串分割成符合表结构的列
*/
public static class LineSplitter implements FlatMapFunction<String, Tuple3<String, String, String>> {
@Override
public void flatMap(String line, Collector<Tuple3<String, String, String>> out) {
//创建3列的tuple
Tuple3<String, String, String> t3 = new Tuple3<String, String, String>();
//分割
String[] split = line.split(" ");
//赋值
for (int i = 0; i < split.length; i++) {
t3.setField(split[i], i);
}
//输出
out.collect(t3);
}
}
}
2.2. TableSource
2.2.1. 支持的DataSource的种类
目前,Flink提供了CsvTableSource读取CSV文件和一些datasource来读取来自Kafka的JSON或Avro数据。自定义TableSource可以通过实现BatchTableSource或StreamTableSource接口来定义。
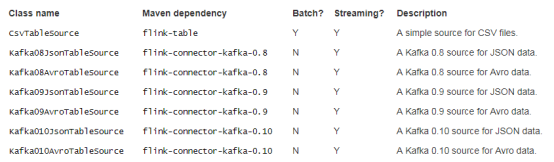
2.2.2. KafkaJsonTableSource
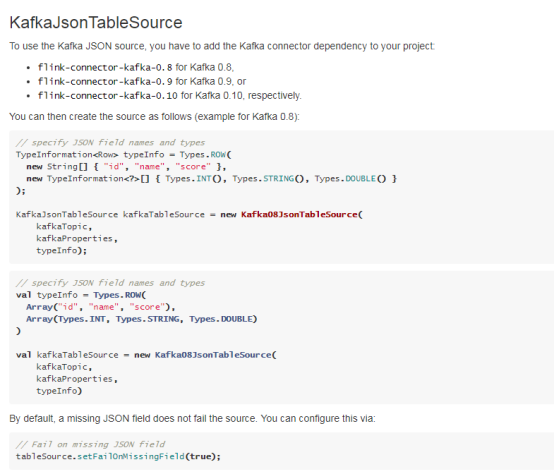
2.2.3. KafkaAvroTableSource
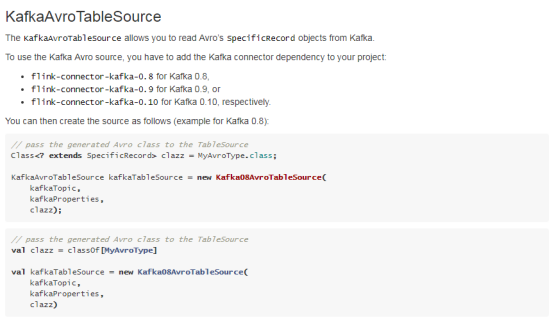
2.2.4. CsvTableSource

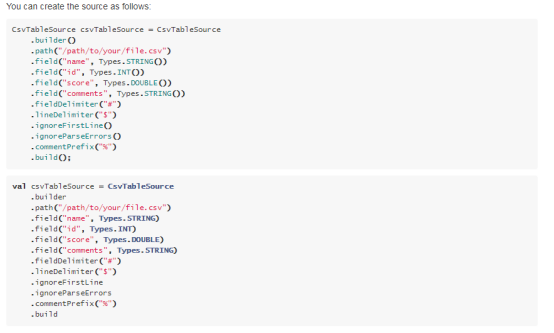
2.3. TableSink
2.3.1. Provided TableSinks

2.3.2. CsvTableSink
3. 基本概念
3.1. Stream & Transformation & Operator
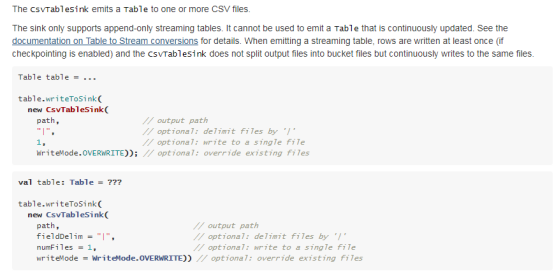
用户实现的Flink程序是由Stream和Transformation这两个基本构建块组成,其中Stream是一个中间结果数据,而Transformation是一个操作,它对一个或多个输入Stream进行计算处理,输出一个或多个结果Stream。
当一个Flink程序被执行的时候,它会被映射为Streaming Dataflow(数据流)。一个Streaming Dataflow是由一组Stream和Transformation Operator组成,它类似于一个DAG图,在启动的时候从一个或多个Source Operator开始,结束于一个或多个Sink Operator。
下面是一个由Flink程序映射为Streaming Dataflow的示意图,如下所示:
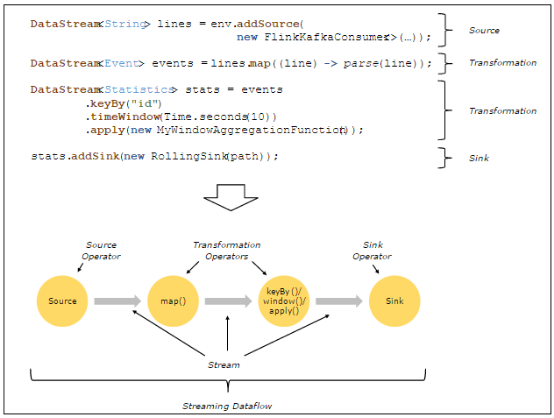
FlinkKafkaConsumer是一个Source Operator
map、keyBy、timeWindow、apply是Transformation Operator
RollingSink是一个Sink Operator
3.2. Parallel Dataflow
在Flink中,程序天生是并行和分布式的:一个Stream可以被分成多个Stream分区(Stream Partitions),一个Operator可以被分成多个Operator Subtask,每一个Operator Subtask是在不同的线程中独立执行的。一个Operator的并行度,等于Operator Subtask的个数,一个Stream的并行度总是等于生成它的Operator的并行度。
有关Parallel Dataflow的实例,如下图所示:
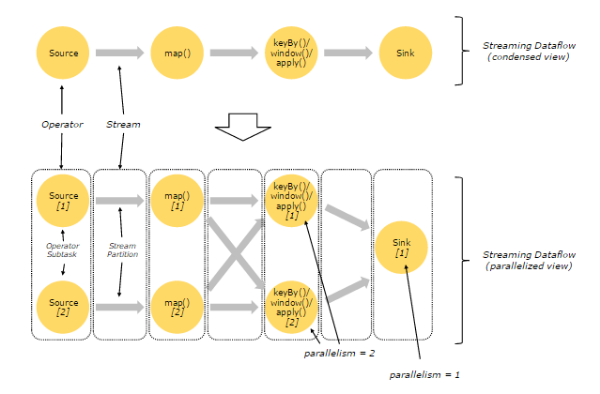
上图Streaming Dataflow的并行视图中,展现了在两个Operator之间的Stream的两种模式:
- One-to-one模式
比如从Source[1]到map()[1],它保持了Source的分区特性(Partitioning)和分区内元素处理的有序性,也就是说map()[1]的Subtask看到数据流中记录的顺序,与Source[1]中看到的记录顺序是一致的。
- Redistribution模式
这种模式改变了输入数据流的分区,比如从map()[1]、map()[2]到keyBy()/window()/apply()[1]、keyBy()/window()/apply()[2],上游的Subtask向下游的多个不同的Subtask发送数据,改变了数据流的分区,这与实际应用所选择的Operator有关系。
另外,Source Operator对应2个Subtask,所以并行度为2,而Sink Operator的Subtask只有1个,故而并行度为1。
3.3. Task & Operator Chain
在Flink分布式执行环境中,会将多个Operator Subtask串起来组成一个Operator Chain,实际上就是一个执行链,每个执行链会在TaskManager上一个独立的线程中执行,如下图所示:
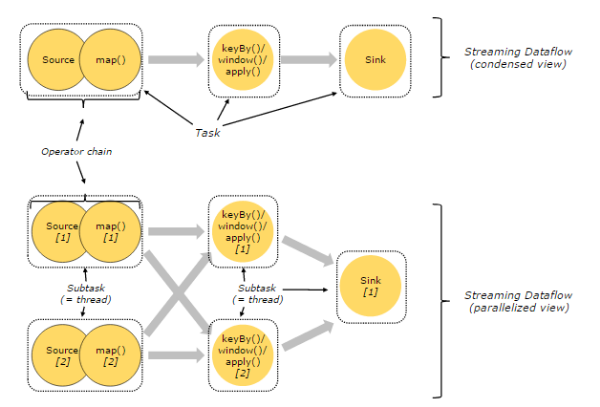
上图中上半部分表示的是一个Operator Chain,多个Operator通过Stream连接,而每个Operator在运行时对应一个Task;图中下半部分是上半部分的一个并行版本,也就是对每一个Task都并行化为多个Subtask。
3.4. Time & Window
Flink支持基于时间窗口操作,也支持基于数据的窗口操作,如下图所示:

上图中,基于时间的窗口操作,在每个相同的时间间隔对Stream中的记录进行处理,通常各个时间间隔内的窗口操作处理的记录数不固定;而基于数据驱动的窗口操作,可以在Stream中选择固定数量的记录作为一个窗口,对该窗口中的记录进行处理。
有关窗口操作的不同类型,可以分为如下几种:倾斜窗口(Tumbling Windows,记录没有重叠)、滑动窗口(Slide Windows,记录有重叠)、会话窗口(Session Windows),具体可以查阅相关资料。
在处理Stream中的记录时,记录中通常会包含各种典型的时间字段,Flink支持多种时间的处理,如下图所示:
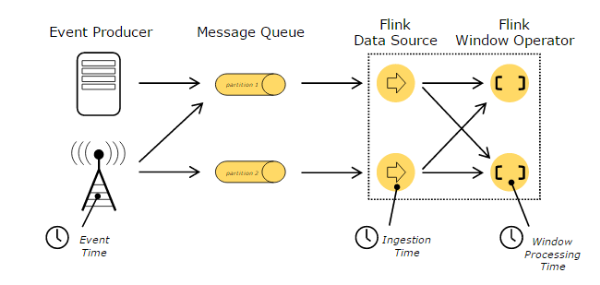
上图描述了在基于Flink的流处理系统中,各种不同的时间所处的位置和含义,其中,Event Time表示事件创建时间,Ingestion Time表示事件进入到Flink Dataflow的时间 ,Processing Time表示某个Operator对事件进行处理事的本地系统时间(是在TaskManager节点上)。这里,谈一下基于Event Time进行处理的问题,通常根据Event Time会给整个Streaming应用带来一定的延迟性,因为在一个基于事件的处理系统中,进入系统的事件可能会基于Event Time而发生乱序现象,比如事件来源于外部的多个系统,为了增强事件处理吞吐量会将输入的多个Stream进行自然分区,每个Stream分区内部有序,但是要保证全局有序必须同时兼顾多个Stream分区的处理,设置一定的时间窗口进行暂存数据,当多个Stream分区基于Event Time排列对齐后才能进行延迟处理。所以,设置的暂存数据记录的时间窗口越长,处理性能越差,甚至严重影响Stream处理的实时性。
有关基于时间的Streaming处理,可以参考官方文档,在Flink中借鉴了Google使用的WaterMark实现方式,可以查阅相关资料。
3.5. 基本架构
Flink系统的架构与Spark类似,是一个基于Master-Slave风格的架构,如下图所示:
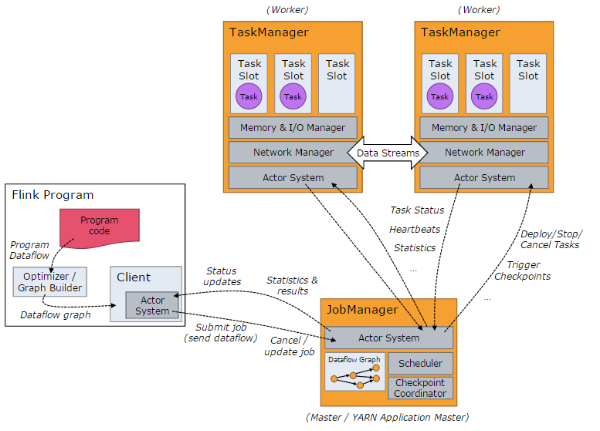
Flink集群启动时,会启动一个JobManager进程、至少一个TaskManager进程。在Local模式下,会在同一个JVM内部启动一个JobManager进程和TaskManager进程。当Flink程序提交后,会创建一个Client来进行预处理,并转换为一个并行数据流,这是对应着一个Flink Job,从而可以被JobManager和TaskManager执行。在实现上,Flink基于Actor实现了JobManager和TaskManager,所以JobManager与TaskManager之间的信息交换,都是通过事件的方式来进行处理。
如上图所示,Flink系统主要包含如下3个主要的进程:
l JobManager
JobManager是Flink系统的协调者,它负责接收Flink Job,调度组成Job的多个Task的执行。同时,JobManager还负责收集Job的状态信息,并管理Flink集群中从节点TaskManager。JobManager所负责的各项管理功能,它接收到并处理的事件主要包括:
- RegisterTaskManager
在Flink集群启动的时候,TaskManager会向JobManager注册,如果注册成功,则JobManager会向TaskManager回复消息AcknowledgeRegistration。
- SubmitJob
Flink程序内部通过Client向JobManager提交Flink Job,其中在消息SubmitJob中以JobGraph形式描述了Job的基本信息。
- CancelJob
请求取消一个Flink Job的执行,CancelJob消息中包含了Job的ID,如果成功则返回消息CancellationSuccess,失败则返回消息CancellationFailure。
- UpdateTaskExecutionState
TaskManager会向JobManager请求更新ExecutionGraph中的ExecutionVertex的状态信息,更新成功则返回true。
- RequestNextInputSplit
运行在TaskManager上面的Task,请求获取下一个要处理的输入Split,成功则返回NextInputSplit。
- JobStatusChanged
ExecutionGraph向JobManager发送该消息,用来表示Flink Job的状态发生的变化,例如:RUNNING、CANCELING、FINISHED等。
l TaskManager
TaskManager也是一个Actor,它是实际负责执行计算的Worker,在其上执行Flink Job的一组Task。每个TaskManager负责管理其所在节点上的资源信息,如内存、磁盘、网络,在启动的时候将资源的状态向JobManager汇报。TaskManager端可以分成两个阶段:
- 注册阶段
TaskManager会向JobManager注册,发送RegisterTaskManager消息,等待JobManager返回AcknowledgeRegistration,然后TaskManager就可以进行初始化过程。
- 可操作阶段
该阶段TaskManager可以接收并处理与Task有关的消息,如SubmitTask、CancelTask、FailTask。如果TaskManager无法连接到JobManager,这是TaskManager就失去了与JobManager的联系,会自动进入“注册阶段”,只有完成注册才能继续处理Task相关的消息。
l Client
当用户提交一个Flink程序时,会首先创建一个Client,该Client首先会对用户提交的Flink程序进行预处理,并提交到Flink集群中处理,所以Client需要从用户提交的Flink程序配置中获取JobManager的地址,并建立到JobManager的连接,将Flink Job提交给JobManager。 Client会将用户提交的Flink程序组装一个JobGraph, 并且是以JobGraph的形式提交的。一个JobGraph是一个Flink Dataflow,它由多个JobVertex组成的DAG。其中,一个JobGraph包含了一个Flink程序的如下信息:JobID、Job名称、配置信息、一组JobVertex等。
3.6. 组件栈
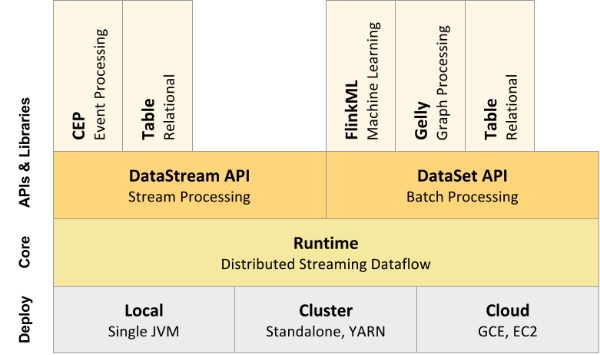
Flink是一个分层架构的系统,每一层所包含的组件都提供了特定的抽象,用来服务于上层组件。Flink分层的组件栈如下图所示:
下面,我们自下而上,分别针对每一层进行解释说明:
l Deployment层
该层主要涉及了Flink的部署模式,Flink支持多种部署模式:本地、集群(Standalone/YARN)、云(GCE/EC2)。Standalone部署模式与Spark类似,这里,我们看一下Flink on YARN的部署模式,如下图所示:
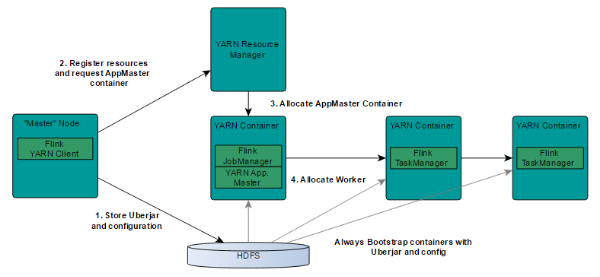
了解YARN的话,对上图的原理非常熟悉,实际Flink也实现了满足在YARN集群上运行的各个组件:Flink YARN Client负责与YARN RM通信协商资源请求,Flink JobManager和Flink TaskManager分别申请到Container去运行各自的进程。通过上图可以看到,YARN AM与Flink JobManager在同一个Container中,这样AM可以知道Flink JobManager的地址,从而AM可以申请Container去启动Flink TaskManager。待Flink成功运行在YARN集群上,Flink YARN Client就可以提交Flink Job到Flink JobManager,并进行后续的映射、调度和计算处理。
l Runtime层
Runtime层提供了支持Flink计算的全部核心实现,比如:支持分布式Stream处理、JobGraph到ExecutionGraph的映射、调度等等,为上层API层提供基础服务。
l API层
API层主要实现了面向无界Stream的流处理和面向Batch的批处理API,其中面向流处理对应DataStream API,面向批处理对应DataSet API。
l Libraries层
该层也可以称为Flink应用框架层,根据API层的划分,在API层之上构建的满足特定应用的实现计算框架,也分别对应于面向流处理和面向批处理两类。面向流处理支持:CEP(复杂事件处理)、基于SQL-like的操作(基于Table的关系操作);面向批处理支持:FlinkML(机器学习库)、Gelly(图处理)。
4. 内部原理
4.1. 容错机制
Flink基于Checkpoint机制实现容错,它的原理是不断地生成分布式Streaming数据流Snapshot(快照)。在流处理失败时,通过这些Snapshot可以恢复数据流处理。理解Flink的容错机制,首先需要了解一下Barrier这个概念:
Stream Barrier是Flink分布式Snapshotting中的核心元素,它会作为数据流的记录被同等看待,被插入到数据流中,将数据流中记录的进行分组,并沿着数据流的方向向前推进。每个Barrier会携带一个Snapshot ID,属于该Snapshot的记录会被推向该Barrier的前方。因为Barrier非常轻量,所以并不会中断数据流。带有Barrier的数据流,如下图所示:
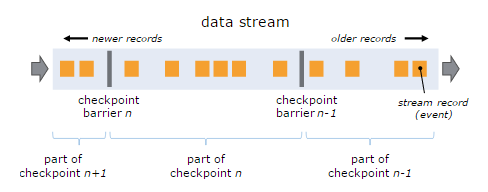
基于上图,我们通过如下要点来说明:
- 出现一个Barrier,在该Barrier之前出现的记录都属于该Barrier对应的Snapshot,在该Barrier之后出现的记录属于下一个Snapshot
- 来自不同Snapshot多个Barrier可能同时出现在数据流中,也就是说同一个时刻可能并发生成多个Snapshot
- 当一个中间(Intermediate)Operator接收到一个Barrier后,它会发送Barrier到属于该Barrier的Snapshot的数据流中,等到Sink Operator接收到该Barrier后会向Checkpoint Coordinator确认该Snapshot,直到所有的Sink Operator都确认了该Snapshot,才被认为完成了该Snapshot
这里还需要强调的是,Snapshot并不仅仅是对数据流做了一个状态的Checkpoint,它也包含了一个Operator内部所持有的状态,这样才能够在保证在流处理系统失败时能够正确地恢复数据流处理。也就是说,如果一个Operator包含任何形式的状态,这种状态必须是Snapshot的一部分。
Operator的状态包含两种:一种是系统状态,一个Operator进行计算处理的时候需要对数据进行缓冲,所以数据缓冲区的状态是与Operator相关联的,以窗口操作的缓冲区为例,Flink系统会收集或聚合记录数据并放到缓冲区中,直到该缓冲区中的数据被处理完成;另一种是用户自定义状态(状态可以通过转换函数进行创建和修改),它可以是函数中的Java对象这样的简单变量,也可以是与函数相关的Key/Value状态。
对于具有轻微状态的Streaming应用,会生成非常轻量的Snapshot而且非常频繁,但并不会影响数据流处理性能。Streaming应用的状态会被存储到一个可配置的存储系统中,例如HDFS。在一个Checkpoint执行过程中,存储的状态信息及其交互过程,如下图所示:
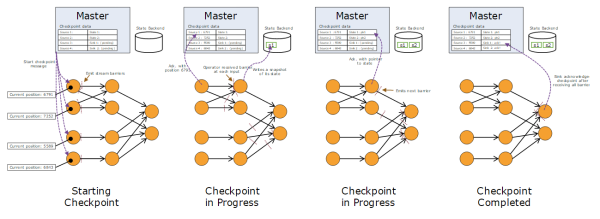
在Checkpoint过程中,还有一个比较重要的操作——Stream Aligning。当Operator接收到多个输入的数据流时,需要在Snapshot Barrier中对数据流进行排列对齐,如下图所示:
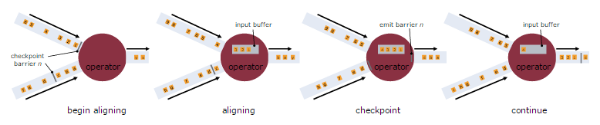
具体排列过程如下:
Operator从一个incoming Stream接收到Snapshot Barrier n,然后暂停处理,直到其它的incoming Stream的Barrier n(否则属于2个Snapshot的记录就混在一起了)到达该Operator
接收到Barrier n的Stream被临时搁置,来自这些Stream的记录不会被处理,而是被放在一个Buffer中
一旦最后一个Stream接收到Barrier n,Operator会emit所有暂存在Buffer中的记录,然后向Checkpoint Coordinator发送Snapshot n
继续处理来自多个Stream的记录
基于Stream Aligning操作能够实现Exactly Once语义,但是也会给流处理应用带来延迟,因为为了排列对齐Barrier,会暂时缓存一部分Stream的记录到Buffer中,尤其是在数据流并行度很高的场景下可能更加明显,通常以最迟对齐Barrier的一个Stream为处理Buffer中缓存记录的时刻点。在Flink中,提供了一个开关,选择是否使用Stream Aligning,如果关掉则Exactly Once会变成At least once。
4.2. 调度机制
在JobManager端,会接收到Client提交的JobGraph形式的Flink Job,JobManager会将一个JobGraph转换映射为一个ExecutionGraph,如下图所示:
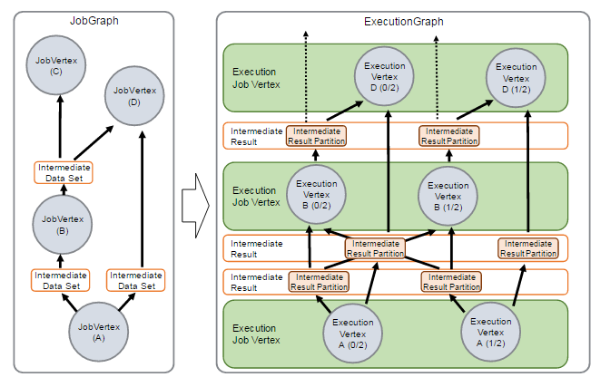
通过上图可以看出:
JobGraph是一个Job的用户逻辑视图表示,将一个用户要对数据流进行的处理表示为单个DAG图(对应于JobGraph),DAG图由顶点(JobVertex)和中间结果集(IntermediateDataSet)组成,其中JobVertex表示了对数据流进行的转换操作,比如map、flatMap、filter、keyBy等操作,而IntermediateDataSet是由上游的JobVertex所生成,同时作为下游的JobVertex的输入。
而ExecutionGraph是JobGraph的并行表示,也就是实际JobManager调度一个Job在TaskManager上运行的逻辑视图,它也是一个DAG图,是由ExecutionJobVertex、IntermediateResult(或IntermediateResultPartition)组成,ExecutionJobVertex实际对应于JobGraph图中的JobVertex,只不过在ExecutionJobVertex内部是一种并行表示,由多个并行的ExecutionVertex所组成。另外,这里还有一个重要的概念,就是Execution,它是一个ExecutionVertex的一次运行Attempt,也就是说,一个ExecutionVertex可能对应多个运行状态的Execution,比如,一个ExecutionVertex运行产生了一个失败的Execution,然后还会创建一个新的Execution来运行,这时就对应这个2次运行Attempt。每个Execution通过ExecutionAttemptID来唯一标识,在TaskManager和JobManager之间进行Task状态的交换都是通过ExecutionAttemptID来实现的。
下面看一下,在物理上进行调度,基于资源的分配与使用的一个例子,来自官网,如下图所示:
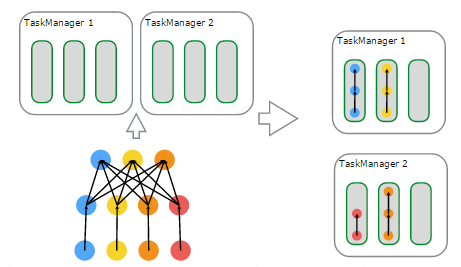
说明如下:
左上子图:有2个TaskManager,每个TaskManager有3个Task Slot
左下子图:一个Flink Job,逻辑上包含了1个data source、1个MapFunction、1个ReduceFunction,对应一个JobGraph
左下子图:用户提交的Flink Job对各个Operator进行的配置——data source的并行度设置为4,MapFunction的并行度也为4,ReduceFunction的并行度为3,在JobManager端对应于ExecutionGraph
右上子图:TaskManager 1上,有2个并行的ExecutionVertex组成的DAG图,它们各占用一个Task Slot
右下子图:TaskManager 2上,也有2个并行的ExecutionVertex组成的DAG图,它们也各占用一个Task Slot
在2个TaskManager上运行的4个Execution是并行执行的
4.3. 迭代机制
机器学习和图计算应用,都会使用到迭代计算,Flink通过在迭代Operator中定义Step函数来实现迭代算法,这种迭代算法包括Iterate和Delta Iterate两种类型,在实现上它们反复地在当前迭代状态上调用Step函数,直到满足给定的条件才会停止迭代。下面,对Iterate和Delta Iterate两种类型的迭代算法原理进行说明:
l Iterate
Iterate Operator是一种简单的迭代形式:每一轮迭代,Step函数的输入或者是输入的整个数据集,或者是上一轮迭代的结果,通过该轮迭代计算出下一轮计算所需要的输入(也称为Next Partial Solution),满足迭代的终止条件后,会输出最终迭代结果,具体执行流程如下图所示:
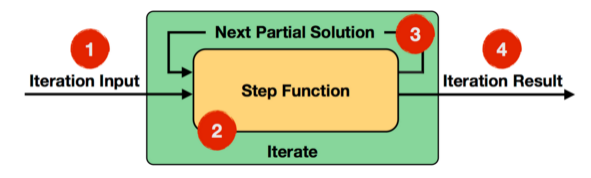
Step函数在每一轮迭代中都会被执行,它可以是由map、reduce、join等Operator组成的数据流。下面通过官网给出的一个例子来说明Iterate Operator,非常简单直观,如下图所示:
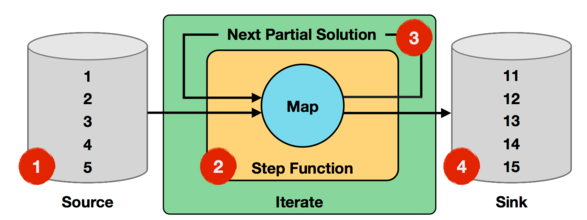
上面迭代过程中,输入数据为1到5的数字,Step函数就是一个简单的map函数,会对每个输入的数字进行加1处理,而Next Partial Solution对应于经过map函数处理后的结果,比如第一轮迭代,对输入的数字1加1后结果为2,对输入的数字2加1后结果为3,直到对输入数字5加1后结果为变为6,这些新生成结果数字2~6会作为第二轮迭代的输入。迭代终止条件为进行10轮迭代,则最终的结果为11~15。
- Delta Iterate
Delta Iterate Operator实现了增量迭代,它的实现原理如下图所示:
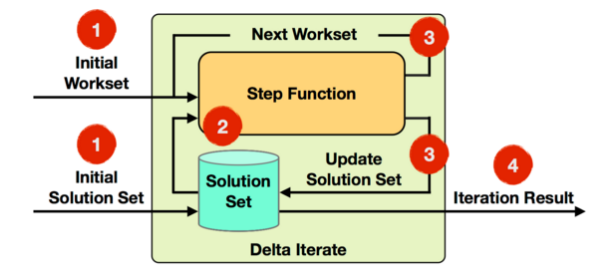
基于Delta Iterate Operator实现增量迭代,它有2个输入,其中一个是初始Workset,表示输入待处理的增量Stream数据,另一个是初始Solution Set,它是经过Stream方向上Operator处理过的结果。第一轮迭代会将Step函数作用在初始Workset上,得到的计算结果Workset作为下一轮迭代的输入,同时还要增量更新初始Solution Set。如果反复迭代知道满足迭代终止条件,最后会根据Solution Set的结果,输出最终迭代结果。
比如,我们现在已知一个Solution集合中保存的是,已有的商品分类大类中购买量最多的商品,而Workset输入的是来自线上实时交易中最新达成购买的商品的人数,经过计算会生成新的商品分类大类中商品购买量最多的结果,如果某些大类中商品购买量突然增长,它需要更新Solution Set中的结果(原来购买量最多的商品,经过增量迭代计算,可能已经不是最多),最后会输出最终商品分类大类中购买量最多的商品结果集合。更详细的例子,可以参考官网给出的“Propagate Minimum in Graph”,这里不再累述。
4.4. Backpressure监控
Backpressure在流式计算系统中会比较受到关注,因为在一个Stream上进行处理的多个Operator之间,它们处理速度和方式可能非常不同,所以就存在上游Operator如果处理速度过快,下游Operator处可能机会堆积Stream记录,严重会造成处理延迟或下游Operator负载过重而崩溃(有些系统可能会丢失数据)。因此,对下游Operator处理速度跟不上的情况,如果下游Operator能够将自己处理状态传播给上游Operator,使得上游Operator处理速度慢下来就会缓解上述问题,比如通过告警的方式通知现有流处理系统存在的问题。
Flink Web界面上提供了对运行Job的Backpressure行为的监控,它通过使用Sampling线程对正在运行的Task进行堆栈跟踪采样来实现,具体实现方式如下图所示:

JobManager会反复调用一个Job的Task运行所在线程的Thread.getStackTrace(),默认情况下,JobManager会每间隔50ms触发对一个Job的每个Task依次进行100次堆栈跟踪调用,根据调用调用结果来确定Backpressure,Flink是通过计算得到一个比值(Radio)来确定当前运行Job的Backpressure状态。在Web界面上可以看到这个Radio值,它表示在一个内部方法调用中阻塞(Stuck)的堆栈跟踪次数,例如,radio=0.01,表示100次中仅有1次方法调用阻塞。Flink目前定义了如下Backpressure状态:
OK: 0 <= Ratio <= 0.10
LOW: 0.10 < Ratio <= 0.5
HIGH: 0.5 < Ratio <= 1
另外,Flink还提供了3个参数来配置Backpressure监控行为:
| 参数名称 |
默认值 |
说明 |
| jobmanager.web.backpressure.refresh-interval |
60000 |
默认1分钟,表示采样统计结果刷新时间间隔 |
| jobmanager.web.backpressure.num-samples |
100 |
评估Backpressure状态,所使用的堆栈跟踪调用次数 |
| jobmanager.web.backpressure.delay-between-samples |
50 |
默认50毫秒,表示对一个Job的每个Task依次调用的时间间隔 |
通过上面个定义的Backpressure状态,以及调整相应的参数,可以确定当前运行的Job的状态是否正常,并且保证不影响JobManager提供服务。