电脑最先是美国人发明出来开始使用的,他们觉得一个字节(可以表示256个编码)表示英语世界里所有的字母、数字和常用特殊符号已经绰绰有余了(其实ASCII只用了前127个编码)于是他们使用ASCII编码,后来传到欧洲地区,法国人在小写字母加上变音符号(如:é),德国人又需要加几个字母(Ä ä、Ö ö、Ü ü、ß)。于是,欧洲人就将ASCII没用完的编码(128-255)为自己特有的符号编码(后来称之为“扩展字符集”)。来到中国,改为使用两个字节表示汉字,产生了GB2312编码,后来又升级出新的编码GBK编码。台湾因为使用繁体字,不和GBK兼容,于是又自己弄了个繁体字编码-大五码(Big-5)。韩国人自己搞的编码叫韩EUC-KR编码。。。。。。
因为各个国家有自己的文字,对自己的文字有自己的编码方式。Windows为了保证能在不同语言的地区使用,就采用了标准代码页(code page)的方法,即把全世界的编码方式都聚集到一起并编上号,在不同的地方采用对应地方的编码方式,比如简体中文GBK编码就是936代码页,繁体中文 Big5编码就是950代码页。
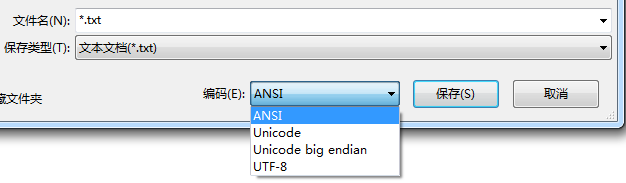
当记事本或者软件采用Windows代码页中对应的编码方式就是“ANSI”编码,在不同的地区“ANSI”编码是不同的。比如在中国,“ANSI”就是GBK编码;在韩国就是EUC-KR编码。默认的“ANSI”编码方式可以通过修改Windows的区域来修改:
“控制面板” =>“时钟、语言和区域”=>“区域和语言”=>“管理”=>“更改系统区域设置...”

当系统的locale为简体中文,意味着当前“ANSI编码”实际是GBK编码。当你把它改成Korean(Korea)时,“ANSI编码”实际是EUC-KR编码,“한국어”就能正常显示了;当你把它改成English(US)时,“ANSI编码”实际是ASCII编码,“汉字”和“한국어”都成乱码了。(改了之后需要重启系统)
Windows中的Code Page,按照引用领域来划分,可以分为两类:ANSI Code Page和 OEM Code Page。可自行了解。