Fayson的github: https://github.com/fayson/cdhproject
推荐关注微信公众号:“Hadoop实操”,ID:gh_c4c535955d0f,或者扫描文末二维码。

1.什么是小文件
小文件一般是指明显小于Hadoop的block size的文件。Hadoop的block size一般是64MB,128MB或者256MB,现在一般趋向于设置的越来越大。后文要讨论的内容会基于128MB,这也是CDH中的默认值。为了方便后面的讨论,Fayson这里假定如果文件大小小于block size的75%,则定义为小文件。但小文件不仅是指文件比较小,如果Hadoop集群中的大量文件略大于block size,同样也会存在小文件问题。
比如,假设block size是128MB,但加载到Hadoop的所有文件都是136MB,就会存在大量8MB的block。处理这种“小块”问题你可以调大block size来解决,但解决小文件问题却要复杂的多。
2.小文件是怎么来的
一个Hadoop集群中存在小文件问题是很正常的,可能的原因如下:
1.现在我们越来越多的将Hadoop用于(准)实时计算,在做数据抽取时处理的频率可能是每小时,每天,每周等,每次可能就只生成一个不到10MB的文件。
2.数据源有大量小文件,未做处理直接拷贝到Hadoop集群。
3.MapReduce作业的配置未设置合理的reducer或者未做限制,每个reduce都会生成一个独立的文件。另外如果数据倾斜,导致大量的数据都shuffle到一个reduce,然后其他的reduce都会处理较小的数据量并输出小文件。
3.为什么Hadoop会有小文件问题

Hadoop的小文件问题主要是会对NameNode内存管理和MapReduce性能造成影响。Hadoop中的每个目录、文件和block都会以对象的形式保存在NameNode的内存中。根据经验每个对象在内存中大概占用150个字节。如果HDFS中保存2000万个文件,每个文件都在同一个文件夹中,而且每个文件都只有一个block,则NameNode需要6GB内存。如果只有这么点文件,这当然也没有什么问题,但是随着数据量的增长集群的扩容,最终会达到单台NameNode可以处理的文件(block)数量的上限。基于同样的假设,如果HDFS中保存的数据文件增长到10亿个,则NameNode需要300GB内存。以下Fayson带大家看看300GB内存的NameNode会有什么影响:
1.当NameNode重启时,它都需要从本地磁盘读取每个文件的元数据,意味着你要读取300GB数据到内存中,不可避免导致NameNode启动时间较长。
2.一般来说,NameNode会不断跟踪并检查每个数据块的存储位置。这是通过DataNode的定时心跳上报其数据块来实现的。数据节点需要上报的block越多,则也会消耗越多的网络带宽/时延。即使节点之间是高速网络(万兆/光纤),但不可避免的会带来一些不好的影响。
3.NameNode本身使用300G内存,相当于JVM你需要配置300GB的heap,对于JVM来说本来就存在稳定性的风险,比如GC时间较长。
所以优化和解决小文件问题基本是必须的。如果可以减少集群上的小文件数,则可以减少NameNode的内存占用,启动时间以及网络影响。
4.MapReduce的性能问题
如果集群中有大量小文件,会降低MapReduce的处理性能,无论是Hive,Pig还是Java MapReduce,当然其实其他计算引擎比如Spark,Impala也会受到影响。第一个原因是大量小文件意味着大量的随机磁盘IO。磁盘IO通常是MapReduce性能的最大瓶颈之一,在HDFS中对于相同数量的数据,一次大的顺序读取往往优于几次随机读取的性能。如果可以将数据存储在较少,而更大的一些block中,可以降低磁盘IO的性能影响。
性能下降的第二个原因有点复杂,需要了解MapReduce如何处理文件和资源调度。当MapReduce任务启动时,每个数据block会被分配为一个map任务。HDFS中的每个文件至少是一个block。如果你有10000个文件,而且每个文件10MB,那么这个MapReduce作业会被分配为10000个map任务。一般来说每个Hadoop的map任务会运行在自己的JVM中,所以会带来10000个JVM的启动和关闭的资源开销。
集群的资源是有限的,为了方便计算,假设我们在YARN的配置中为每个NodeManager配置20个vcore,那么为了同时运行10000个mapper,你需要500台节点。大多数Hadoop集群都小于这个规模,所以一般情况下大量map任务可能只能排队等待ResourceManager来分配资源。如果你只有10台机器,那么总共只有200个vcore,这个排队的队列会较大,相应的处理时间也会变的较长。另外,往往你的集群中可能不止这一个作业。
如果10000个10MB文件换成800个128MB的文件,那么你就只需要800个map任务。相当于减少了一个数量级的JVM维护时间,同时也优化了磁盘IO。尽管一个单独的map任务处理一个128MB的文件比一个10MB的文件时间要慢,但是整个作业的总运行时间肯定可以降低一个数量级。
5.解决NameNode的内存问题
上面的内容提到过每个block的元数据都需要加载到NameNode的内存中,这导致一个Hadoop集群在NameNode中存储的对象是有上限的,并且对象太多会带来启动时间较长以及网络延迟的问题。常见的有两种解决方案,减少集群的NameNode中的对象数量,或者以某种方式让NameNode使用更多的“内存”但不会导致较长的启动时间,这就是Hadoop Archive(HAR)文件和NameNode联邦。
5.1.Hadoop Archive Files

Hadoop archive files通过将许多小文件打包到更大的HAR文件中来缓解NameNode内存问题,类似于Linux上的TAR文件。这样可以让NameNode只处理单个HAR文件,而不是数十个或数百个小文件。可以使用har://前缀而不是hdfs://来访问HAR文件中的文件。HAR文件是基于HDFS中已有的文件创建的。因此,HAR文件不仅可以合并从数据源抽取到HDFS中的数据,也可以合并通过正常的MapReduce处理创建的数据。HAR文件可以独立的用于解决小文件问题,除了HDFS,没有其他的依赖。
虽然HAR文件减少了NameNode中小文件对内存的占用,但访问HAR文件内容性能可能会更低。HAR文件仍然随机存储在磁盘上,并且读取HAR内的文件需要访问两个索引 - 一个用于NameNode找到HAR文件本身,一个用于在HAR文件内找到小文件的位置。在HAR中读取文件实际上可能比读取存储在HDFS上的相同文件慢。MapReduce作业的性能同样会受到影响,因为它仍旧会为每个HAR文件中的每个文件启动一个map任务。
所以这里我们需要有一个权衡(trade-off),HAR文件可以解决NameNode内存问题,但同时会降低读取性能。如果你的小文件主要用于存档,并且不经常访问,那么HAR文件是一个很好的解决方案。如果小文件经常要被读取或者处理,那么可能需要重新考虑解决方案。
5.2.NameNode联邦

NameNode联邦允许你在一个集群中拥有多个NameNode,每个NameNode都存储元数据对象的子集。这样可以让所有的元数据对象都不止存储在单个机器上,也消除了单个节点的内存限制,因为你可以扩容。这听上去是一个很美丽的方案,但其实它也有局限性。
NameNode联邦隔离了元数据对象 - 仅仅只有某一个NameNode知道某一个特定的元数据对象在哪里,意思就是说如果你想找到某个文件,你必须知道它是保存在哪个NameNode上的。如果你的集群中有多个租户和/或隔离的应用程序,那使用NameNode联邦是挺不错的,你可以通过租户或者应用程序来隔离元数据对象。但是,如果要在所有的应用程序之间共享数据,则该方法其实也并不是完美的。
由于NameNode联邦并不会改变集群中对象或者块的数量,所以它并没有解决MapReduce的性能问题。相反,联邦会增加Hadoop集群安装和维护的复杂度。所以我们说联邦可以解决小文件问题,倒不如说它提供了一种办法让你“隐藏”小文件。
6.解决MapReduce性能问题
根据之前讨论的内容,MapReduce性能问题主要是由随机磁盘IO和启动/管理太多的map任务组合引起的。解决方案似乎很明显 - 合并小文件,然而这个事往往说起来容易做起来难。以下讨论一下几种解决方案:
注:虽然本章名为解决MapReduce的性能问题,但其实同样也是为了解决NameNode的压力,以及解决其他计算引擎比如Impala/Spark的性能问题。
1.修改数据抽取方法/间隔
2.批量文件合并
3.Sequence文件
4.HBase
5.S3DistCp (如果使用Amazon EMR)
6.使用CombineFileInputFormat
7.通过Hive合并小文件
8.使用Hadoop的追加特性
6.1.修改数据抽取方法/间隔
解决小文件问题的最简单方法就是在生成阶段就进行杜绝。如果是由数据源产生大量小文件并直接拷贝到Hadoop,可以调研了解数据源是否能生成一些大文件,或者从数据源到HDFS的数据抽取过程中进行数据处理合并小文件。如果每小时只抽取10MB的数据,考虑是否改为每天一次,这样创建1个240MB的文件而不是24个10MB的文件。但是,你可能无法控制数据源的改动配合或业务对数据抽取间隔的需求,这样小文件问题无法避免,这时可能需要考虑其他的解决方案。
6.2.批量文件合并
当产生小文件是不可避免时,文件合并是常见的解决方案。使用这种方法,你可以定期运行一个MapReduce任务,读取某一个文件夹中的所有小文件,并将它们重写为较少数量的大文件。比如一个文件夹中有1000个文件,你可以在一个MapReduce任务中指定reduce的数量为5,这样1000个输入文件会被合并为5个文件。随后进行一些简单的HDFS文件/文件夹操作(将新文件覆盖回原目录),则可以将NameNode的内存使用减少到200分之1,并且可以提高以后MapReduce或其他计算引擎对同一数据处理的性能。
举例如果使用Pig,只需要2行包括load和store语句即可以实现。比如合并文本文件:

在Hive或Java MapReduce中实现同样比较容易。这些MapReduce作业运行同样需要集群资源,所以建议调度在生产系统非繁忙时间段执行。但是,应该定期执行这种合并的MapReduce作业,因为小文件随时或者几乎每天都可能产生。但这个合并程序需要有额外的逻辑来判断存在大量小文件的目录,或者你自己是知道哪些目录是存在大量小文件的。因为假如某个目录只有3个文件,运行合并作业远不如合并一个500个文件的文件夹的性能优势提升明显。
检查所有文件夹并确认哪些文件夹中的小文件需要合并,目前主要是通过自定义的脚本或程序,当然一些商业工具也能做,比如Pentaho可以迭代HDFS中的一组文件夹,找到最小合并要求的文件夹。这里还推荐另外一个开源工具File Crush
https://github.com/edwardcapriolo/filecrush/
File Crush没有专业支持,所以无法保证它可以与Hadoop的后续版本一直保持兼容。
批量合并文件的方法无法保留原始文件名,如果原始文件名对于你了解数据来源非常重要,则批量合并文件的方法也不适用。但一般来说,我们一般只会设计HDFS的各级目录的文件名,而不会细化到每个文件的名字,所以理论来说这种方法问题也不大。
6.3.Sequence文件

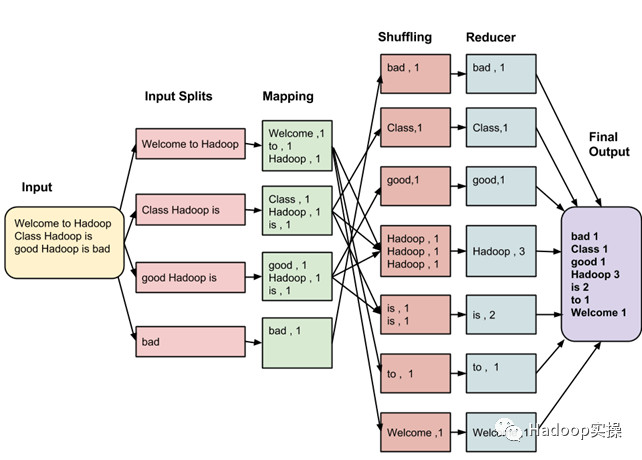
当需要维护原始文件名时,常见的方法是使用Sequence文件。 在此解决方案中,文件名作为key保存在sequence文件中,然后文件内容会作为value保存。下图给出将一些小文件存储为sequence文件的示例:

如果一个sequence文件包含10000个小文件,则同时会包含10000个key在一个文件中。sequence文件支持块压缩,并且是可被拆分的。这样MapReduce作业在处理这个sequence文件时,只需要为每个128MB的block启动一个map任务,而不是每个小文件启动一个map任务。当你在同时抽取数百个或者数千个小文件,并且需要保留原始文件名时,这是非常不错的方案。
但是,如果你一次仅抽取少量的小文件到HDFS,则sequence文件的方法也不太可行,因为sequence文件是不可变的,无法追加。比如3个10MB文件将产生1个30MB的sequence文件,根据本文前面的定义,这仍然是一个小文件。另外一个问题是如果需要检索sequence文件中的文件名列表则需要遍历整个文件。
另外一个问题是Hive并不能较好的处理由该方法合并出来的sequence文件。Hive将value中的所有数据视为单行。这样会导致Hive查看这些数据不方便,因为以前小文件中的一行的所有数据也是Hive中的单行,即相当于只有一个字段。同时,Hive没办法访问这种sequence的key,即文件名。当然你可以自定义Hive serde来实现,不过这个超过了本文需要讨论的范围。
6.4.HBase

解决小文件问题,除了HDFS存储外,当然还可以考虑HBase列式存储。使用HBase可以将数据抽取过程从生成大量小HDFS文件更改为以逐条记录写入到HBase表。如果你对数据访问的需求主要是随机查找或者叫点查,则HBase是最好的选择。HBase在架构上就是为快速插入,存储大量数据,单个记录的快速查找以及流式数据处理而设计的。但如果你对数据访问的需求主要是全表扫描,则HBase不是最适合的。
可以基于HBase的表的数据创建Hive表,但是查询这种Hive表对于不同的查询类型性能会不一样。当查询单行或者范围查找时,Hive on HBase会表现不错,但是如果是全表扫描则效率比较低下,大多数分析查询比如带group by的语句都是全表扫描。
使用HBase,可以较好的应对实时数据写入以及实时查询的场景。但是如何分配和平衡HBase与集群上其他的组件的资源使用,以及HBase本身运维都会带来额外的运维管理成本。另外,HBase的性能主要取决于你的数据访问方式,所以在选择HBase解决小文件问题之前,应该进行仔细调研和设计。
6.5.S3DistCp (如果使用Amazon EMR)

此解决方案仅适用于Amazon EMR的用户,当然你在AWS中使用CDH也一样。Amazon EMR集群一般设计为短期存储,而在S3中持久化保存数据。即使使用S3,依旧存在小文件问题,所以这时需要选择S3DistCp。
S3DistCp是由Amazon提供的一个工具,用于分布式将S3中的数据拷贝到临时的HDFS或其他S3 bucket。这个工具可以通过配置groupBy和targetSize参数来将文件合并到一起。如果S3中存储了数千个EMR需要处理的小文件时,这个工具是一个不错的选择。S3DistCp通过连接许多小文件并导入到HDFS中,据报道,该方式的性能也非常优秀。
S3DistCp这个工具跟之前文章提到的批量合并文件的方法其实是类似的,只是说Amazon给你提供了一个现成的工具。
6.6.使用CombineFileInputFormat
CombineFileInputFormat是Hadoop提供的抽象类,它在MapReduce读取时合并小文件。合并的文件不会持久化到磁盘,它是在一个map任务中合并读取到的这些小文件。好处是MapReduce可以不用为每个小文件启动一个map任务,而且因为是自带的实现类,你不用额外将小文件先提前合并。这解决了MapReduce作业启动太多map任务的问题,但是因为作业仍然在读取多个小文件,随机磁盘IO依旧是一个问题。另外,CombineFileInputFormat大多数情况下都不会考虑data locality,往往会通过网络从其他节点拉取数据。
为了实现这个,需要为不同的文件类型编写Java代码扩展CombineFileInputFormat类。这样实现一个自定义的类后,就可以配置最大的split大小,然后单个map任务会读取小文件并进行合并直到满足这个大小。以下有一个示例参考:
http://www.idryman.org/blog/2013/09/22/process-small-files-on-hadoop-using-combinefileinputformat-1/
当然如果是Hive作业有简单的方式,直接配置以下参数即可:
hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat
set mapreduce.input.fileinputformat.split.maxsize=1073741824
set mapreduce.input.fileinputformat.split.minsize=1073741824
以上是以Hive的单个map作业合并小文件到1GB为示例。
注意以上无论是MapReduce代码实现方式还是Hive,因为合并的文件并不会持久化保存到磁盘,因此CombineFileInputFormat方式并不会缓解NameNode内存管理问题。只是提高MapReduce或者Hive作业的性能。
6.7.通过Hive合并小文件
如果你在使用Hive时因为“create table as”或“insert overwrite”语句输出了小文件,你可以通过设置一些参数来缓解。通过设置这些参数。Hive会在本身的SQL作业执行完毕后会单独起一个MapReduce任务来合并输出的小文件。
注意这个设置仅对Hive创建的文件生效,比如你使用Sqoop导数到Hive表,或者直接抽数到HDFS等,该方法都不会起作用。涉及的配置参数如下:

6.8.使用Hadoop的追加特性
有些人可能会问,为什么不使用Hadoop自带的Append特性来解决小文件问题,即当第一次输出是小文件时,后面的输出可以继续追加这些小文件,让小文件变成大文件,这听上去是个不错的建议,但其实做起来挺难的,因为Hadoop生态系统里的工具都不支持包括Flume,Sqoop,Pig,Hive,Spark,Impala和Java MapReduce。比如MapReduce任务有一个规定,输出结果目录必须是在之前不存在的。所以MapReduce作业肯定无法使用Append特性,由于Sqoop,Pig和Hive都使用了MapReduce,所以这些工具也不支持Append。Flume不支持Append主要是因为它假设经过一段时间比如几秒,多少字节,多少事件数或者不活动的秒数,Flume就会关闭文件而不再打开它。
如果你想使用Append来解决小文件问题,则你需要自己编写特定的程序来追加到现有的文件。另外,当集群中其他应用程序如果正在读取或处理这些需要追加的文件,你就不能使用自定义的MapReduce或者Spark程序来追加这些文件了。所以如果要使用这种方法,你最好还是谨慎考虑。
7.总结
选择何种办法来解决小文件问题取决于各个方面,主要来自数据访问方式以及存储要求,具体包括:
1.小文件是在整个数据pipeline的哪个部分生成的?我们是要在抽数之前处理还是抽取到集群后处理?
2.是什么工具生成的小文件?可以通过调整工具的配置来减少小文件的数量吗?
3.企业的大数据团队的技能水平怎么样?他们有能力编写一些自定义程序来处理小文件或者抽数逻辑吗?他们未来有能力维护吗?
4.小文件生成的频率是多少?为了生成大文件,需要多久合并一次小文件?
5.什么工具会访问这些小文件?比如Hive,Impala,Spark或者其他程序?
6.对于一个生产集群来说的话,存在哪些时间窗口,集群有空余的资源来运行合并小文件的程序?
7.计算引擎访问数据时能接受怎样的延迟?这涉及我们考虑如何合并小文件,包括大小,压缩格式等。
当你把上面的问题都能回答了,我想就能找到自己的解决方案了。后续Fayson会以实操的方式来讲解Hive,Impala具体如何来合并小文件,可以持续关注。
原文参考:
为天地立心,为生民立命,为往圣继绝学,为万世开太平。
推荐关注Hadoop实操,第一时间,分享更多Hadoop干货,欢迎转发和分享。
原创文章,欢迎转载,转载请注明:转载自微信公众号Hadoop实操