json 和pickle 模块
json和pickle模块下都有4个功能
dumps <---> loads (序列化 <--->反序列化)
dump <---> load (简单写法序列化<---> 简单写法反序列化)
用途:序列化模块
什么是序列化
序列化就是把内存中数据类型转换成一种可以存储到硬盘/基于网络传输的中间格式
反序列化就是将中间格式转成相对应的数据类型
PS:不同平台的数据类型是无法识别的,如果数据要夸平台交互,被其他平台识别,那就要把数据序列化后传输到其他平台,然后该平台再反序列后即可读取
PS:序列化写入的文件是什么类型,反序列化出来就是什么类型
为何要序列化
1. 持久保存状态
2. 数据跨平台交互
如何序列化
json:
优点: 是一种通用的格式
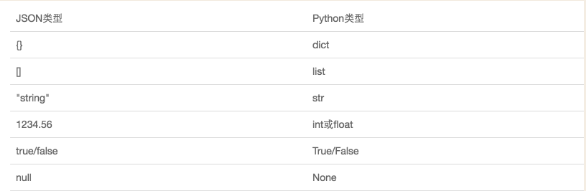
缺点: 只能识别部分python数据类型(dict、list、str、int、float、True\False、None)
PS:json是开发运维中常用模式,而且json只能识别双引号 “ ”
pickle:
优点: 可以识别所有python的数据类型
缺点: 只能被python识别
序列化实例import json序列化
将序列化的结果写入文件
dic={'user':'egon','age':18}
res=json.dumps(dic)
with open('a.json',mode='wt',encoding='utf-8') as f:
f.write(res)
PS:用json模块将字典转换成json格式写入文件这就是一个序列化过程
PS:序列化写入的文件可以使txt文件,也可以是json后缀的文件
从文件中读取内容转换成相关的格式
with open('a.json',mode='rt',encoding='utf-8') as f:
dic=json.loads(f.read())
print(dic,dic['user'])
序列化并且写入文件(简写法)
dic={'user':'egon','age':18}
with open('b.json',mode='wt',encoding='utf-8') as f:
json.dump(dic,f) #这一步就是先把dic做了json.dumps,然后执行了f.read(),最后把内容写入文件
反序列化读取文件(简写法)
with open('b.json',mode='rt',encoding='utf-8') as f:
res= json.load(f) #这一步就是先执行了f.read(),然后执行了json.load反序列化操作
print(res)
eval内置函数(无法用作反序列化)
原理就是把python中内置表达式运行一下,什么是python内置表达式,就是如1+2python中会得到一个3,所以做了加法运算,又如[1,2,3],python中会得到一个liest
with open('c.txt',mode='rt',encoding='utf-8') as f:
dic_str=f.read()
dic=eval(dic_str)
print(dic['aaa'])
PS:由于eval转换只是把文件的内容读取然后用python解释器运行,并没有做任何平台类型对应的反序列化,单纯的把表达式拿出来运行,所以会报错,导致读取的代码无法运行
pickle序列化与反序列化
json.dumps({1,2,3,})
import pickle
s={1,2,3}
res=pickle.dumps(s)
print(res,type(res))
with open('e.pkl',mode='wb') as f:
f.write(res)
PS:pickle序列化是将文件转成二进制,读取时候一定要以b模式读取
pikle模块反序列化
with open('e.pkl',mode='rb') as f:
data=f.read()
res=pickle.loads(data)
print(res,type(res))
JSON和Python中类型对应