自动化常用模块
urllib和request模块学习笔记
‘获取页面,UI自动化校验页面展示作用’:
#-*- coding : utf-8 -*-
import urllib.request
import re
url = 'https://www.cnblogs.com/phoebes/p/8379490.html'
req = urllib.request.urlopen(url)
res = req.read().decode()
print(res)
获取页面html页面的编码,根据html元素信息获取数据
urllib需要decode进行转码,requests不需要:
发起get请求(无参数)格式
import requests
url = 'https://www.cnblogs.com/phoebes/p/8379490.html'
req = requests.get(url)
print(req.text)
requests相对简单。
发起post请求格式:
例如登录的接口:url2='https://192.168.1.1:80/login?'
data = {
'username' : 'wangjiasen'
'passwd' : 'a123456'
key : 'sa54dsad4534d54dsa5sd4'
}
则语法:
import requests,json
url2 = 'https://192.168.1.1:80/login?'
data = {
'username' : 'wangjiasen'
'passwd' : 'a123456'
key : 'sa54dsad4534d54dsa5sd4'
}
req = requests.get(url2,data)
print(req.json)
发送有参数的get请求:
import requests,json
url3 = 'https://192.168.1.1:80/login?username=wangjiasen'
req = requests.get(url3)
print(req.json()) 返回json形式
发送cookice的post请求:
import requests,json
url4 = 'https://192.168.1.1:80/login'
data ={
key : '64sad65sa4d6sadas2dsa'
user_id : 456546546
}
cookices = {'wangjiasen' : 'a465546s6ad4sa65d4sa6d54'}
req = requests.post(url4,data,cookice)
print(req.json())
。。。。。。。。。。。。。。。。。。。。。。
通过request请求获取登陆的token
import requests , json
import sens as sens
url = 'https://192.168.1.1:80/api/v1/login'
data = {
'username' : '18209799421',
'password' : '123456'
}
req = requests.post(url,data)
token1 = req.json()
print(token1['result']['token'])
输出token的值
通过re模块以及urllib模块练习简单的爬虫
#-*- coding : utf-8 -*-
import urllib.request,json
import re,chardet
url = 'https://www.360kuai.com/pc/?sign=360_e39369d1&refer_scene=so_92'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
req = urllib.request.Request(url=url, headers=headers)
page = urllib.request.urlopen(req)
# req = urllib.request.urlopen(url)
res1 = page.read()
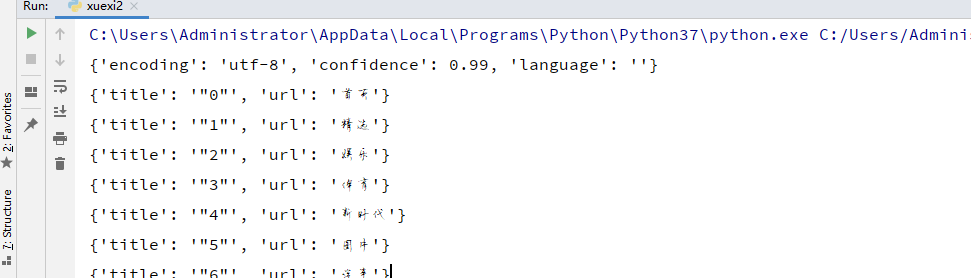
print(chardet.detect(res1)) #打印返回网页的编码方式
res = res1.decode('utf-8')
result = []
pepei = re.compile(r'<li data-index=.*?>.*?<span></span>',re.S)
basic_content = re.finditer(pepei,res)
for i in basic_content:
init_dict = {}
d = re.match(r'<li data-index=(.*?)><a class="nav-item" .*?>(.*?)<span></span>',i.group(),re.S)
init_dict['title'] = d.group(1)
init_dict['url'] = d.group(2)
result.append(init_dict)
for i in result:
print(i)
这是一个简单的快资讯页面的类型爬虫