上一章我们有讲到一个mapreduce案例——移动流量排序,如果我们要将最后的输出结果按总流量大小逆序输出,该怎么实现呢?本节博主将分享这个实现的过程。
一、分析
首先,要实现这个功能,我们可能会想到是否有办法将输出的结果先缓存起来,等执行完成后,在排序一起次性全部输出。是的,这的确是一个可以实现的思路;
我们可以启动一个reduce来处理,在reduce阶段中reduce()方法每次执行时,将key和value缓存到一个TreeMap里面,并且不执行输出;当reduce全部切片处理完成后,会调用一个cleanup()方法,且这个方法仅会被调用一次,我们可以在这个方法里面做排序输出。

上面的这种方式确实是可以实现,当是并不是很优雅;我们可以利用mapreduce自身的map阶段输出key的特性来实现,这个特性就是所有的key会按照key类comparable方法实现的实现去做排序输出。详细过程,我们可以将整个需求分成两个mapreduce过程来执行,第一个mapreduce就和之前的博客中一样只做统计流量,第二个mapreduce我们就用key的特性去实现排序。
二、实现方案(key特性实现方式)
FlowBean(流量统计bean类)
package com.empire.hadoop.mr.flowsort;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
/**
* 类 FlowBean.java的实现描述:流量统计bean类
*
* @author arron 2018年12月1日 下午10:59:42
*/
public class FlowBean implements WritableComparable<FlowBean> {
private long upFlow;
private long dFlow;
private long sumFlow;
//反序列化时,需要反射调用空参构造函数,所以要显示定义一个
public FlowBean() {
}
public FlowBean(long upFlow, long dFlow) {
this.upFlow = upFlow;
this.dFlow = dFlow;
this.sumFlow = upFlow + dFlow;
}
public void set(long upFlow, long dFlow) {
this.upFlow = upFlow;
this.dFlow = dFlow;
this.sumFlow = upFlow + dFlow;
}
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getdFlow() {
return dFlow;
}
public void setdFlow(long dFlow) {
this.dFlow = dFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
/**
* 序列化方法
*/
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(dFlow);
out.writeLong(sumFlow);
}
/**
* 反序列化方法 注意:反序列化的顺序跟序列化的顺序完全一致
*/
public void readFields(DataInput in) throws IOException {
upFlow = in.readLong();
dFlow = in.readLong();
sumFlow = in.readLong();
}
public String toString() {
return upFlow + "\t" + dFlow + "\t" + sumFlow;
}
public int compareTo(FlowBean o) {
return this.sumFlow > o.getSumFlow() ? -1 : 1; //从大到小, 当前对象和要比较的对象比, 如果当前对象大, 返回-1, 交换他们的位置(自己的理解)
}
}
FlowCountSort(流量统计后的mapreduce排序实现主类)
package com.empire.hadoop.mr.flowsort;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 13480253104 180 180 360 13502468823 7335 110349 117684 13560436666 1116 954
* 2070 类 FlowCountSort.java的实现描述:流量排序的mapreduce主实现类
*
* @author arron 2018年12月1日 下午11:00:07
*/
public class FlowCountSort {
static class FlowCountSortMapper extends Mapper<LongWritable, Text, FlowBean, Text> {
FlowBean bean = new FlowBean();
Text v = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 拿到的是上一个统计程序的输出结果,已经是各手机号的总流量信息
String line = value.toString();
String[] fields = line.split("\t");
String phoneNbr = fields[0];
long upFlow = Long.parseLong(fields[1]);
long dFlow = Long.parseLong(fields[2]);
bean.set(upFlow, dFlow);
v.set(phoneNbr);
context.write(bean, v);
}
}
/**
* 根据key来掉, 传过来的是对象, 每个对象都是不一样的, 所以每个对象都调用一次reduce方法
*
* @author: 张政
* @date: 2016年4月11日 下午7:08:18
* @package_name: day07.sample
*/
static class FlowCountSortReducer extends Reducer<FlowBean, Text, Text, FlowBean> {
// <bean(),phonenbr>
@Override
protected void reduce(FlowBean bean, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
context.write(values.iterator().next(), bean);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
/*
* conf.set("mapreduce.framework.name", "yarn");
* conf.set("yarn.resoucemanager.hostname", "mini1");
*/
Job job = Job.getInstance(conf);
/* job.setJar("/home/hadoop/wc.jar"); */
//指定本程序的jar包所在的本地路径
job.setJarByClass(FlowCountSort.class);
//指定本业务job要使用的mapper/Reducer业务类
job.setMapperClass(FlowCountSortMapper.class);
job.setReducerClass(FlowCountSortReducer.class);
//指定mapper输出数据的kv类型
job.setMapOutputKeyClass(FlowBean.class);
job.setMapOutputValueClass(Text.class);
//指定最终输出的数据的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
//指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
//指定job的输出结果所在目录
Path outPath = new Path(args[1]);
/*
* FileSystem fs = FileSystem.get(conf); if(fs.exists(outPath)){
* fs.delete(outPath, true); }
*/
FileOutputFormat.setOutputPath(job, outPath);
//将job中配置的相关参数,以及job所用的java类所在的jar包,提交给yarn去运行
/* job.submit(); */
boolean res = job.waitForCompletion(true);
System.exit(res ? 0 : 1);
}
}
三、打包运行
#提交hadoop集群运行
hadoop jar flowsort_aaron.jar com.empire.hadoop.mr.flowsort.FlowCountSort /user/hadoop/flowcountount /flowsort
#查看输出结果目录
hdfs dfs -ls /flowsort
#浏览输出结果
hdfs dfs -cat /flowsort/part-r-00000运行效果图:
[hadoop@centos-aaron-h1 ~]$ hadoop jar flowsort_aaron.jar com.empire.hadoop.mr.flowsort.FlowCountSort /user/hadoop/flowcountount /flowsort
18/12/02 07:10:46 INFO client.RMProxy: Connecting to ResourceManager at centos-aaron-h1/192.168.29.144:8032
18/12/02 07:10:46 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
18/12/02 07:10:48 INFO input.FileInputFormat: Total input files to process : 1
18/12/02 07:10:48 INFO mapreduce.JobSubmitter: number of splits:1
18/12/02 07:10:48 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
18/12/02 07:10:49 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1543705650872_0001
18/12/02 07:10:50 INFO impl.YarnClientImpl: Submitted application application_1543705650872_0001
18/12/02 07:10:50 INFO mapreduce.Job: The url to track the job: http://centos-aaron-h1:8088/proxy/application_1543705650872_0001/
18/12/02 07:10:50 INFO mapreduce.Job: Running job: job_1543705650872_0001
18/12/02 07:11:00 INFO mapreduce.Job: Job job_1543705650872_0001 running in uber mode : false
18/12/02 07:11:00 INFO mapreduce.Job: map 0% reduce 0%
18/12/02 07:11:10 INFO mapreduce.Job: map 100% reduce 0%
18/12/02 07:11:23 INFO mapreduce.Job: map 100% reduce 100%
18/12/02 07:11:23 INFO mapreduce.Job: Job job_1543705650872_0001 completed successfully
18/12/02 07:11:23 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=801
FILE: Number of bytes written=396695
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=725
HDFS: Number of bytes written=594
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=6980
Total time spent by all reduces in occupied slots (ms)=8661
Total time spent by all map tasks (ms)=6980
Total time spent by all reduce tasks (ms)=8661
Total vcore-milliseconds taken by all map tasks=6980
Total vcore-milliseconds taken by all reduce tasks=8661
Total megabyte-milliseconds taken by all map tasks=7147520
Total megabyte-milliseconds taken by all reduce tasks=8868864
Map-Reduce Framework
Map input records=21
Map output records=21
Map output bytes=753
Map output materialized bytes=801
Input split bytes=131
Combine input records=0
Combine output records=0
Reduce input groups=21
Reduce shuffle bytes=801
Reduce input records=21
Reduce output records=21
Spilled Records=42
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=402
CPU time spent (ms)=1890
Physical memory (bytes) snapshot=342441984
Virtual memory (bytes) snapshot=1694273536
Total committed heap usage (bytes)=137867264
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=594
File Output Format Counters
Bytes Written=594运行结果:
[hadoop@centos-aaron-h1 ~]$ hdfs dfs -ls /flowsort
Found 2 items
-rw-r--r-- 2 hadoop supergroup 0 2018-12-02 07:11 /flowsort/_SUCCESS
-rw-r--r-- 2 hadoop supergroup 594 2018-12-02 07:11 /flowsort/part-r-00000
[hadoop@centos-aaron-h1 ~]$ hdfs dfs -cat /flowsort/part-r-00000
13502468823 36675 551745 588420
13925057413 55290 241215 296505
13726238888 12405 123405 135810
13726230503 12405 123405 135810
18320173382 47655 12060 59715
13560439658 10170 29460 39630
13660577991 34800 3450 38250
15013685858 18295 17690 35985
13922314466 15040 18600 33640
15920133257 15780 14680 30460
84138413 20580 7160 27740
13602846565 9690 14550 24240
18211575961 7635 10530 18165
15989002119 9690 900 10590
13560436666 5580 4770 10350
13926435656 660 7560 8220
13480253104 900 900 1800
13826544101 1320 0 1320
13926251106 1200 0 1200
13760778710 600 600 1200
13719199419 1200 0 1200四、最后总结
细心的小伙伴们从上的mapreduce主代码中肯定会看出和之前的写法有所差别,如下图所示: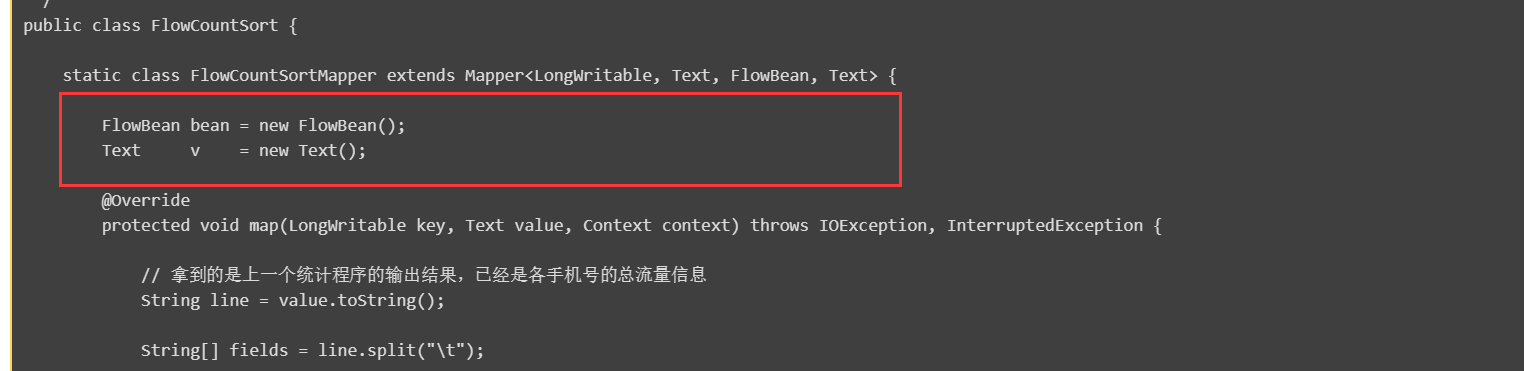
此处我们之前都是在map方法里面去申明对象,那么之前的做法有什么问题呢?那就是之前的代码如果在数据很多的时候,我们在调用map的时候回创建很多个对象,有可能会导致我们内存溢出。但是,如果们向上面这样写,就只创建一个对象就够了,在map中设置相应的值,而后序列换输出去,然后依次重复前面的设置动作即可。注意,此处是因为我们mapreduce会做序列化输出,所以同一个对象序列化后只需的结果,并不影响。
最后寄语,以上是博主本次文章的全部内容,如果大家觉得博主的文章还不错,请点赞;如果您对博主其它服务器大数据技术或者博主本人感兴趣,请关注博主博客,并且欢迎随时跟博主沟通交流。