何为关联规则学习
关联规则学习是一种基于规则的机器学习方法,用于发现大型数据库中变量之间的有趣关系。它旨在使用一些有趣的度量来识别在数据库中发现的强规则。这种基于规则的方法在分析更多数据时也会生成新规则。假设数据集足够大,最终目标是帮助机器模拟人类大脑的特征提取和新未分类数据的抽象关联能力。
基于强有力规则的概念,Rakesh Agrawal,TomaszImieliński和Arun Swami介绍了关联规则,用于发现超市中销售点(POS)系统记录的大规模交易数据中产品之间的规律性。例如,在超市的销售数据中发现,如果顾客一起购买洋葱和土豆,他们也可能会购买汉堡肉。这些信息可以用作关于营销活动的决策的基础,例如促销定价或产品放置。
除了市场购物篮分析的上述示例之外,目前在许多应用领域中使用关联规则,包括Web使用挖掘,入侵检测,连续生产和生物信息学。与序列挖掘相反,关联规则学习通常不考虑事务内或跨事务的项目顺序。
常用的关联算法包括
Apriori、FP-Growth、PrefixSpan、SPADE、AprioriAll、Apriori-Some等。
关联算法评估规则
频繁规律与有效规则:
- 频繁规则指的是关联结果中支持度和置信度都比较高的规则
- 有效规则指关联规则真正能促进规则中的前后项提升
假如,数据集有1000条事务数据用来显示购买苹果和香蕉的订单记录,其中有600个客户的订单记录中包含了苹果,有800个客户的订单记录中包含了香蕉,而有400个客户同时购买了苹果和香蕉。假如我们产生了一条关联规则,用来表示购买了苹果的客户中还有很多人购买香蕉,那么该规则可以表示为:苹果→香蕉。
支持度:support = 400/1000= 40%
置信度:confidence = 400/600=67%
如果只是看支持度和置信度,这个规则似乎非常显著的说明了苹果和香蕉之间的频繁关系,买了苹果的客户中有67%的人也会一起购买香蕉。但是,如果忽略购买苹果的事实,只购买香蕉的客户比例会高达是80%(800/1000)!这显示了购买苹果这种条件不会对购买香蕉产生积极的促进作用,反而会阻碍其销售,苹果和香蕉之间是一种负相关的关系。因此,只看支持度和置信度将无法完整体现规则的有效性,这里我们使用提升度来有效应对该问题。
提升度(Lift)指的是应用关联规则和不应用产生结果的比例。在本示例中,Lift=(400)/(800)=0.5(有关联规则的前提下只有400个客户会购买香蕉,没有关联规则的前提下会有800个购买香蕉)。当提升度为1时,说明应用关联规则和不应用关联规则产生相同的结果;当提升度大于1时,说明应用关联规则比不应用关联规则能产生更好的结果;当提升度小于1时,关联规则具有负相关的作用,该规则是无效规则。
做关联规则评估时,需要综合考虑支持度、置信度和提升度三个指标,支持度和置信度的值越大越好。
提升度低的负相关关联其实也是一种关联模式,也是可以通过避免的方式利用这种关联:不将互斥商品放在一个组合中,不将互斥广告投放整合投放,不将互斥关键字提供个客户,不将互斥信息流展现给客户。
运营分析中关联分析的使用
- 网站页面关联分析:帮助我们找到用户在不同页面之间的频繁访问关系,以分析用户特定的页面浏览方式,这样可以帮助了解不同页面之间的分流和引流情况,可用于不同页面间的推荐已达到提高转化率。
- 广告流量关联分析:针对站外广告投放渠道用户浏览或点击的行为分析,该分析主要用于了解用户的浏览和点击广告的规则。这种站外广告曝光和点击的关联分析可以为广告客户的精准投放提供参考。
- 用户关键字搜索:通过分析用户在站内的搜索关键字了解用户真实需求的。通过对用户搜索的关键字的关联分析,可以得到类似于搜索了iPhone又搜索了三星,这种关联可以用于搜索推荐、搜索关联等场景,有助于改善搜索体验,提高客户的目标转化率。
- 不同场景发生,这种模式可以广泛用于分析运营中关注的要素,例如用户浏览商品和购买商品的关联,关注产品价格和购买产品价格的关联,加入购物车与购买的关联。这种关联可以找到用户在一个事件中不同行为之间的关联,可以用来挖掘用户的真实需求,有针对性的对当前用户进行个性化推荐,同时也对定价策略有参考价值。
- 相同场景发生,用户在同一个页面中点击不同功能、选择不同的应用。这种关联可以用于分析用户使用功能的先后顺序,有利于做产品优化和用户体验提升;对于不同产品功能组合、开发和升级有了更加明确地参考方向,便于针对永辉习惯性操作模式做功能迭代;同时针对用户频繁查看和点击的内容,可以采用打包、组合、轮转等策略,帮助客户查找,同时增加内容曝光度和用户体验。
python代码实现
apriori模块:
# -*- coding: utf-8 -*-
from numpy import *
import re
def createData(fileName):
mat = []
req = re.compile(r',')
fr = open(fileName)
content = fr.readlines()
for line in content:
tem = line.replace('\n','').split(',')
mat.append(tem)
return mat
def loadDataSet():
return [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]
# C1 是大小为1的所有候选项集的集合
def createC1(dataSet):
C1 = []
for transaction in dataSet:
for item in transaction:
if not [item] in C1:
C1.append([item]) #store all the item unrepeatly
C1.sort()
#return map(frozenset, C1)#frozen set, user can't change it.
return list(map(frozenset, C1))
def scanD(D,Ck,minSupport):
ssCnt={}
for tid in D:
for can in Ck:
if can.issubset(tid):
#if not ssCnt.has_key(can):
if not can in ssCnt:
ssCnt[can]=1
else: ssCnt[can]+=1
numItems=float(len(D))
retList = []
supportData = {}
for key in ssCnt:
support = ssCnt[key]/numItems #compute support
if support >= minSupport:
retList.insert(0,key)
supportData[key] = support
return retList, supportData
#total apriori
def aprioriGen(Lk, k): #组合,向上合并
#creates Ck 参数:频繁项集列表 Lk 与项集元素个数 k
retList = []
lenLk = len(Lk)
for i in range(lenLk):
for j in range(i+1, lenLk): #两两组合遍历
L1 = list(Lk[i])[:k-2]; L2 = list(Lk[j])[:k-2]
L1.sort(); L2.sort()
if L1==L2: #若两个集合的前k-2个项相同时,则将两个集合合并
retList.append(Lk[i] | Lk[j]) #set union
return retList
#apriori
def apriori(dataSet, minSupport = 0.5):
C1 = createC1(dataSet)
D = list(map(set, dataSet)) #python3
L1, supportData = scanD(D, C1, minSupport)#单项最小支持度判断 0.5,生成L1
L = [L1]
k = 2
while (len(L[k-2]) > 0):#创建包含更大项集的更大列表,直到下一个大的项集为空
Ck = aprioriGen(L[k-2], k)#Ck
Lk, supK = scanD(D, Ck, minSupport)#get Lk
supportData.update(supK)
L.append(Lk)
k += 1 #继续向上合并 生成项集个数更多的
return L, supportData
#生成关联规则
# 创建关联规则
def generateRules(fileName, L, supportData, minConf=0.7): # supportData是从scanD获得的字段
bigRuleList = []
for i in range(1, len(L)): # 只获得又有2个或以上的项目的集合
for freqSet in L[i]:
H1 = [frozenset([item]) for item in freqSet]
if (i > 1):
rulesFromConseq(fileName, freqSet, H1, supportData, bigRuleList, minConf)
else:
calcConf(fileName, freqSet, H1, supportData, bigRuleList, minConf)
return bigRuleList
# 实例数、支持度、置信度和提升度评估
def calcConf(fileName, freqSet, H, supportData, brl, minConf=0.7):
prunedH = []
D = fileName
numItems = float(len(D))
for conseq in H:
conf = supportData[freqSet] / supportData[freqSet - conseq] # 计算置信度
if conf >= minConf:
instances = numItems * supportData[freqSet] # 计算实例数
liftvalue = conf / supportData[conseq] # 计算提升度
brl.append((freqSet - conseq, conseq, int(instances), round(supportData[freqSet], 4), round(conf, 4),
round(liftvalue, 4))) # 支持度已经在SCAND中计算得出
prunedH.append(conseq)
return prunedH
# 生成候选规则集
def rulesFromConseq(fileName, freqSet, H, supportData, brl, minConf=0.7):
m = len(H[0])
if (len(freqSet) > (m + 1)):
Hmp1 = aprioriGen(H, m + 1)
Hmp1 = calcConf(fileName, freqSet, Hmp1, supportData, brl, minConf)
if (len(Hmp1) > 1):
rulesFromConseq(fileName, freqSet, Hmp1, supportData, brl, minConf)
apriori算法实现:
import apriori
import pandas as pd
from graphviz import Digraph
# 设置最小支持度阈值
minS = 0.5
# 设置最小置信度阈值
minC = 0.7
data = apriori.loadDataSet()
# 计算符合最小支持度的规则
L, suppdata = apriori.apriori(data, minSupport=minS)
# 计算满足最小置信度规则
rules = apriori.generateRules(data, L, suppdata, minConf=minC)
### 关联结果评估###
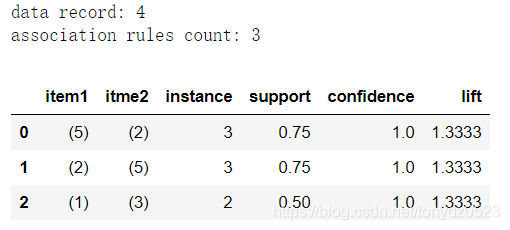
model_summary = 'data record: {1} \nassociation rules count: {0}' # 展示数据集记录数和满足阈值定义的规则数量
print (model_summary.format(len(rules), len(data))) # 使用str.format做格式化输出
df = pd.DataFrame(rules, columns=['item1', 'itme2', 'instance', 'support',
'confidence', 'lift']) # 创建频繁规则数据框
df_lift = df[df['lift'] > 1.0] # 只选择提升度>1的规则
df_lift.sort_values('instance', ascending=False)
# 关联结果图形展示
dot = Digraph() # 创建有向图
graph_data = df_lift[['item1', 'itme2', 'instance']] # 切分画图用的前项、后项和实例数数据
for each_data in graph_data.values: # 循环读出每条规则
node1, node2, weight = each_data # 分割每条数据画图用的前项、后项和实例数
node1 = str(node1).strip('frozenset({})') # 转化为字符串
node2 = str(node2).strip('frozenset({})') # 转化为字符串
label = '%s' % weight # 创建一个标签用于展示实例数
dot.node(node1, node1, shape='record') # 增加节点(规则中的前项)
dot.edge(node1, node2, label=label, constraint='true') # 增加有向边
dot.render('apriori', view=True) # 保存规则为pdf文件

使用pyfpgrowth模块实现FP-Growth:
import pyfpgrowth
# 数据
data = [[1, 2, 5],
[2, 4],
[2, 3],
[1, 2, 4],
[1, 3],
[2, 3],
[1, 3],
[1, 2, 3, 5],
[1, 2, 3]]
# 设置支持度和置信度
minS = 0.2
minC = 0.7
# 计算支持值
support = minS*len(data)
# 获取符合支持度规则数据
patterns = pyfpgrowth.find_frequent_patterns(data, support)
# 获取符合置信度规则数据
rules = pyfpgrowth.generate_association_rules(patterns, minC)
rules
结果如下:
{(5,): ((1, 2), 1.0),
(1, 5): ((2,), 1.0),
(2, 5): ((1,), 1.0),
(4,): ((2,), 1.0)}
补充
除了打包组合的思维方式之外,还可以这样考虑应用:既然用户具有较强的发生关联事件关系(例如购买、查看等)的可能性,那么可以基于用户的这种习惯,将前后项内容故意分离开,利用用户主动查找的时机来产生更多价值或完成特定转化目标。
例如:用户经常一起购买啤酒和尿布,我们可以分别将啤酒和尿布陈列在展柜的两端(或者隔开一段距离),然后在用户购买啤酒又去购买尿布的途中,也许会发现别的商品进而产生兴趣,从而实现更多的销售。但是需要注意这种关联需求的效用能否支撑这种搜索过程,则刚需最好,强有效规则其次,不可过多降低用户体验。
序列模式的关联规则:
序列模式相较于普通关联模式最大的区别是不同的事件之间具有明显的时间区隔,以及先后的序列发生关系,能得到类似于“完成某个事件之后会在特定的时间周期内完成其他事件”的结论,例如购买了冰箱的客户会在3个月内购买洗衣机的结论。这是一种预测性分析的模式,能够将事件发生的时间和对象提取出来,使用与基于时间序列的数据化运营需求。
应用场景:
- 基于用户上一次购买时间和商品信息,推断用户下一次购物时间和购买的商品,如果用户脱离周期过久需要实施挽留措施
- 基于用户上一次浏览页面的时间和页面信息,推断用户下一次可能浏览的页面
- 通过上衣此关键字的搜索预测下一次最可能搜索的关键字
能实现序列模式的关联算法包括:
- AprioriAll:基于哈希树的序列关联算法,它与Apriori算法的执行过程是一样的,不同点在于候选集的产生,需要区分最后两个元素的前后顺序。
- AprioriSome:该算法是对AprioriAll算法的改进。
- CARMA(Continuous Association Rule Mining Algorithm):CARMA是一种比较新的关联规则算法,能够处理在线连续交易流数据。
- GSP(Generalized Sequential Patterns):基于水平存储结构和哈希树遍历操作的序列关联算法,它具有类似于Apriori算法的实现步骤,主要区别在于产生候选序列模式。
- SPADE(Sequential PAttern Discovery using Equivalence classes):基于垂直存储结构和格理论连接操作的序列关联算法,它是一种改进的GSP算法。
- FreeSpan:频繁模式投影的序列关联算法,利用频繁项递归地将序列数据库投影到更小的投影数据库集中,在每个投影数据库中生成子序列片断,是一种分治思想的算法。
- PrefixSpan(Prefix-Projected Pattern Growth):基于前缀树的序列关联算法,从Free-Span中推导演化而来
参考:
《python数据分析与数据化运营》 宋天龙