一. 前言
上一篇Redis 之深入江湖-复制原理中说了复制的原理,那么在理解复制原理之后,还要知道在这复制功能的背后,还有哪些坑要注意一下,毕竟坑是要跳过去的,而不是跳进去的。
二. 读写分离的一些问题
对于读占比较高的场景,可以通过把部分的读流量分摊到slave节点来减轻master节点的压力,同时需要注意master节点永远只执行写操作。如图:
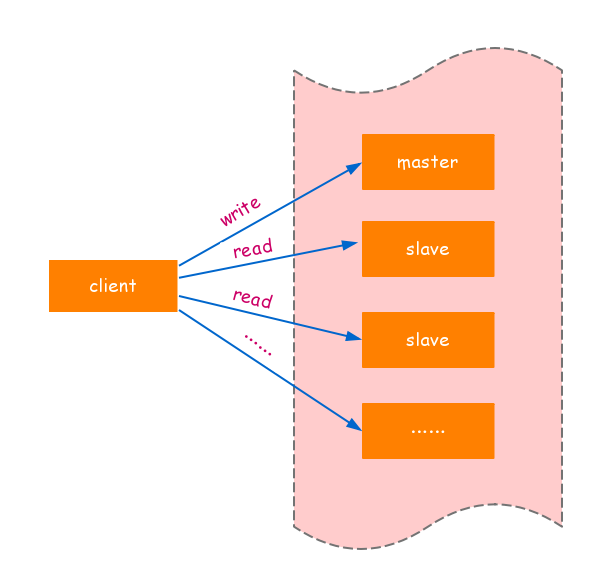
在使用slave节点响应读请求时,业务端可能会遇到一些问题,如:复制数据延迟、读到过期数据、slave节点故障。
1).数据延迟
Redis复制数据的延迟,是由于复制的一部特性导致的,因此无法避免。但是延迟主要是取决于网络带宽和命令阻塞的情况而定,比如master节点刚写入数据,在slave节点上是可能读取不到数据的。在大量延迟的场景下,可以编写外部程序监听主从节点的复制偏移量,延迟较大时发出报警或通知,实现方式如下:
- 对于具体延迟,监控程序可通过检查 info replication 的 offset 指标记录,从节点的偏移量可以查询主节点的offset指标,它们的差值就是主从延迟的字节量。
- 如果字节量过高,可以采用zookeeper的监听回调机制实现客户端通知。
- 客户端接收通知后,修改读命令路由到主节点或其他从节点上,当延迟恢复后,再通知客户端。
2).读到过期数据
当master节点存储大量超时的数据,譬如缓存数据,Redis内部需要韵味过期数据的删除策略。删除策略主要有两种:惰性删除和定时删除。
- 惰性删除:master节点每次读取命令时都会检查键是否超时,如果超时则执行del命令删除键对象,之后异步把del命令slave节点,这样可以保证数据复制的一致性,slave节点是永远不会主动去删除超时数据的。
- 定时删除:Redis的master节点在内部定时任务,会循环采样一定数量的键,当发现采样的键过期时,会执行del命令,之后再同步个slave节点。
注:如果数据大量超时,master节点采样速度跟不上过期的速度,而且master节点没有读取过期键的操作,那slave节点时无法收到del命令的,这时从节点上读取的数据已经时超时的了。但是Redis3.2版本中已经解决了这个问题,在此版本中slave节点读取数据之前会检查键过期时间来决定是否返回数据的。
3).从节点故障问题
对于slave节点故障问题,是需要在客户端维护可用的slave节点列表,当slave节点故障时,需立刻切换到其他从节点或主节点上。也可以通过 zookeeper 等协调者解决。
三.规避全量复制
全量复制时一个非常消耗资源的操作,因此避免全量复制是一个重要的关注点。全量复制通常有 3 种情况:第一次全量复制、节点运行 ID 不匹配、复制积压缓冲区不足。
1). 第一次全量复制
由于时第一次建立复制,从节点没有任何主节点的数据,因此必须进行全量复制才可以完成数据同步,对于这种情况的全量复制自然是无法避免的。当对数据量较大且流量较高的主节点从节点时,建议在低峰时操作,或者尽量规避使用大数据量的Redis节点。
2). 节点运行ID不匹配
当主从复制关系建立后,从节点会保存主节点的运行ID,如果此时主节点出现故障重启,那么它的运行ID会改变。从节点发现运行ID不匹配后,会认为自己复制的是一个新的主节点,进而就回进行全量复制。对于这类情况,应该要从架构去规避,譬如提供故障转移功能。当主节点发生故障后,手动提升从节点为主节点或者采用支持故障转移的哨兵或集群来解决。
3). 复制积压缓冲区不足
在主从节点网络中断时后,当从节点再次连上主节点时,会发送psync {offset} {runId} 命令请求部分复制,如果请求的偏移量不在主节点积压缓冲区内,则无法提供给从节点数据,此时会使部分复制转变为全量复制。针对此类情况,需根据网络中断的时长,写命令数据量分析出合理的积压缓冲区的大小。写命令的数据量会根据主节点每秒的info replication的master_repl_offset差值获取(write_size_per_minute)。积压缓冲区的默认大小为1MB,在大流量的场景显然是不够的,这时需要修改 repl_backlog_size 配置,从而避免因复制积压缓冲区不足造成的全量复制。
四.规避复制风暴
复制风暴是指大量从节点对同一主节点或者同一台机器的多个主节点,在短时间内发起全量复制的过程。此时将导致被发起的主节点或机器产生大量开销,如 :CPU、内存、硬盘、带宽等。我们可以通过分析这样的复制场景,然后采用合理的方式进行规避。规避方式如下:
1).单节点复制风暴
但节点复制风暴,一般是发生在主节点挂在多个从节点的场景下。当主节点重启恢复后,从节点发起全量复制流程,此时主节点会为从节点创建RDB快照,如果在快照创建完毕之前,有多个从节点尝试与主节点进行全量同步,那么其他的从节点将共享这份RDB快照。这方面Redis做了相关优化,有效的避免了创建多个快照。但是同时像多个从节点发送快照,可能会使主节点的网络带宽消耗严重,造成主节点延迟变大,极端情况会出现主从断开,导致复制失败。
解决方案:首先减少主节点挂在从节点的数量,或者采用树桩复制结构。
2). 单机复制风暴
由于 Redis 的单线程架构,通常会在一台物理机上部署多个Redis实例。如果这台机器出现故障或网络长时间中断,当他重启恢复后,会有大量从节点针对这台机器的主节点进行全量复制,会造成当前机器带宽耗尽。
解决方案:(1). 应当把主节点尽量分散在多台机器上,避免在单台机器上部署过多的主节点。(2). 当主节点所在机器故障后提供故障恢复转移机制,避免机器恢复后进行密集的全量复制。
五. 主从配置不一致
主从复制不一致是一个容易忽视的问题,对于有些配置可以不一样,比如:主节点关闭 AOF而从节点开启。但对于内存方面的配置必须要一致,例如: maxmemory、hash-max-ziplist-entries 等参数,当配置的maxmemory从节点的内存小于主节点,如果复制的数据量超过了从节点的 maxmemory,他会根据淘汰策略(maxmemory-policy)进行内存溢出控制,此时从节点数据已经丢失,但主从复制流程依然正常进行,复制偏移量也正常,但主从数据已经不一致。修复这类问题,也只能手动进行全量复制。
六. 回归
本文主要讲了复制运维的一些问题及优化,例如读写分离的一些问题、规避全量复制、规避全量复制、主从配置不一致。
参考:《Redis开发与运维》
版权声明:尊重博主原创文章,转载请注明出处 https://www.cnblogs.com/hsdy