Gan的优化目标是达到纳什均衡(为了使损失函数达到最优,生成器与判别器均不会单独改变而是互相对抗),从而尽可能准确的恢复P(data), variational autoEncoder方法通常能够获得很好的似然,但生成低质量的样本。GAN能生成更好的样本,但跟FVBNs,VAEs比起来,更难优化。 GAN能生成更真实的样本是因为GAN最小化Jensen-Shannon divergence, 而VAEs生成模糊样本是因为VAEs最小化数据和模型之间的KL 散度。KL散度是非对称的。

左边为VAEs用的KL散度,右边为GAN用的KL散度
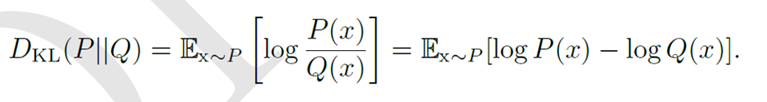
后者(Jensen-Shannon)能生成更真实的样本,是因为根据这种散度训练出来的模型更倾向于生成训练分布中的模式,虽然有些模式会被忽略,但不会生成训练模式中没有的样本。
GAN不容易overfitting,因为生成器没机会直接照抄样本。