版权声明:本文为博主原创文章,转载时请注明出处!谢谢 https://blog.csdn.net/qq_34783311/article/details/84646925
双向LSTM
我们为什么要用双向LSTM?
双向卷积神经网络的隐藏层要保存两个值, A 参与正向计算, A’ 参与反向计算。最终的输出值 y 取决于 A 和 A’:

即正向计算时,隐藏层的 s_t 与 s_t-1 有关;反向计算时,隐藏层的 s_t 与 s_t+1 有关
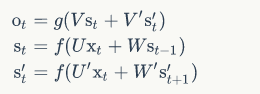
现在们利用tensorflow提供双向LSTM函数来进行手写识别的分类案例,时间序列数据数据的预测也可以通过修改数据集来实现
加载数据
mnist=input_data.read_data_sets("MNIST/",one_hot=True)
定义一个参数的配置类
class Config():
"""
配置文件的类
"""
def __init__(self,input,timestep,batchsize,hidden_unit,hidden_unit1,learning_rate,epoch,num_class):
self.TimeStep=timestep
self.input=input
self.batchsize=batchsize
self.hidden_unit=hidden_unit
self.hidden_unit1=hidden_unit1
self.learning_rate=learning_rate
self.epoch=epoch
self.num_class=num_class
self.weight ={
'in':tf.Variable(tf.random_normal([2 * self.hidden_unit1, self.hidden_unit])),
'out':tf.Variable(tf.random_normal([2*self.hidden_unit,self.num_class]))
}
self.bias = {
'in':tf.Variable(tf.random_normal([self.hidden_unit])),
'out':tf.Variable(tf.random_normal([self.num_class]))
}
self.max_samples=400000
定义双向LSTM模型
def BiLSTM_Model(x,config):
"""
双向LSTM模型来对图像进行分类
:return:
"""
'''
LSTM在进行对序列数据进行处理的时候,需要先将其转化为满足网络的格式[batch,timestep,features]
'''
x=tf.transpose(x,[1,0,2])
x=tf.reshape(x,[-1,config.input])
x=tf.split(x,config.TimeStep,0)
#进行的多层双向神经网络
fw_lstm_cell_1=tf.nn.rnn_cell.BasicLSTMCell(num_units=config.hidden_unit1)
bw_lstm_cell_1=tf.nn.rnn_cell.BasicLSTMCell(num_units=config.hidden_unit1)
fw_lstm_cell_2=tf.nn.rnn_cell.BasicLSTMCell(num_units=config.hidden_unit)
bw_lstm_cell_2=tf.nn.rnn_cell.BasicLSTMCell(num_units=config.hidden_unit)
stack_lstm_fw=tf.nn.rnn_cell.MultiRNNCell(cells=[fw_lstm_cell_1,fw_lstm_cell_2])
stack_lstm_bw=tf.nn.rnn_cell.MultiRNNCell(cells=[bw_lstm_cell_1,bw_lstm_cell_2])
outputs,_,_=tf.nn.static_bidirectional_rnn(cell_fw=stack_lstm_fw,cell_bw=stack_lstm_bw,inputs=x,dtype=tf.float32)
return tf.add(tf.matmul(outputs[-1],config.weight['out']),config.bias['out']) #全连接层进行输出
主函数运行
if __name__=="__main__":
#定义一个配置类的对象
config=Config(learning_rate=0.01,batchsize=128,input=28,timestep=28,hidden_unit1=256,num_class=10,epoch=None,hidden_unit=128)
#定义变量和占位符
#None 表示不确定一次输入多少条数据
X=tf.placeholder(dtype=tf.float32,shape=[None,config.TimeStep,config.input])
Y=tf.placeholder(dtype=tf.float32,shape=[None,config.num_class])
#预测结果的输出
pred=BiLSTM_Model(X,config)
pre_=tf.nn.softmax(pred)
'''取到了前5个概率较大的值以及对应的索引'''
top_k_values,top_k_index=tf.nn.top_k(pre_,5) #获取索引也就表示找到了预测的这个值,然后再进行计算
'''在数据集的one-hot编码索引上进行预测模型的计算,然后统计发生的数量'''
prediction_indices=tf.gather(Y,top_k_index)
count_predictions=tf.reduce_sum(prediction_indices,reduction_indices=1) #这个表示有多少个预测是准确的
prediction=tf.argmax(count_predictions,dimension=1)
#计算交叉熵损失,如果是计算交叉熵,则需要使用tf.reduce_sum()
cost=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=Y,logits=pred))
optimizer=tf.train.AdamOptimizer(learning_rate=config.learning_rate).minimize(cost)
#计算预测的准确性
correct_pred=tf.equal(tf.argmax(pred,1),tf.argmax(Y,1))
accuracy=tf.reduce_sum(tf.cast(correct_pred,tf.float32))
#接下来开始对变量进行初始化
init=tf.global_variables_initializer()
pred_result=[]
with tf.Session() as sess:
sess.run(init)
step = 1
while step * config.batchsize <config.max_samples:
batch_x, batch_y = mnist.train.next_batch(config.batchsize)
batch_x = batch_x.reshape((config.batchsize, config.TimeStep, config.input))
sess.run(optimizer, feed_dict={X: batch_x, Y: batch_y})
if step%20==0:
acc,loss,pred_,pre_soft,ab,predict= sess.run([accuracy/config.batchsize,cost,tf.shape(pred),pre_,top_k_index,prediction], feed_dict={X: batch_x, Y: batch_y})
# pred_result.append(sess.run(tf.argmax(pred_,1))) #将预测的结果
print("pre_soft:{},a:{},predict:{}".format(np.shape(pre_soft),ab,len(predict)))
# print("acc={:.5f},loss={:.9f}".format(acc, loss)
step+=1
print("Optimizer Finished!!d!")
test_len=10000
test_data=mnist.test.images[:test_len].reshape((-1,config.TimeStep,config.input))
test_label=mnist.test.labels[:test_len]
print("Testing Accuracy:{:.5f}".format(sess.run(accuracy/test_len,feed_dict={X:test_data,Y:test_label})))
结果:acc:0.984
参考资料:
https://www.jianshu.com/p/471bdbd0170d
https://maxwell.ict.griffith.edu.au/spl/publications/papers/ieeesp97_schuster.pdf