一、基本信息
1.1、编译环境、作者、项目名称
1 # 编译环境:Pycharm2017、Python3.7 2 # 项目名称:词频统计——增强功能 3 # 作者:1613072038:夏文杰 4 # 1613072040:高昶
1.2、其他
二、项目分析
-
程序运行模块(方法、函数)介绍
Task 1. 接口封装 —— 将基本功能封装成(类或独立模块)
本任务代码和作业4一样,只是将分散的函数整合到一个类中,然后我们再在测试中调用我们写好的类。这里我们的文件名为:lei.py
1 import re 2 3 class workCount: 4 5 def process_file(dst): # 读取文件 6 lines = len(open(dst, 'r').readlines()) # 借助readlines可以获得文本的行数 7 with open(dst) as f: 8 bvffer = f.read() 9 f.close() 10 return bvffer 11 12 def process_buffer(bvffer): 13 if bvffer: 14 for ch in ':,.-_': 15 bvffer = bvffer.lower().replace(ch, " ") 16 bvffer = bvffer.strip().split() 17 word_re = "^[a-z]{4}(\w)*" 18 # 正则匹配至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写 19 words = [] 20 for i in range(len(bvffer)): 21 word = re.match(word_re, bvffer[i]) # 匹配list中的元素 22 if word: # 匹配成功,加入words 23 words.append(word.group()) 24 word_freq = {} 25 for word in words: # 对words进行统计 26 word_freq[word] = word_freq.get(word, 0) + 1 27 return word_freq, len(words) 28 29 def output_result(word_freq): 30 if word_freq: 31 sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True) 32 for item in sorted_word_freq[:10]: # 输出 Top 10 的单词 33 print('<' + str(item[0]) + '>:' + str(item[1])) 34 return sorted_word_freq[:10] 35 36 def print_result(dst): 37 buffer = workCount.process_file(dst) 38 word_freq, counts_words = workCount.process_buffer(buffer) 39 print('统计单词数:' + str(counts_words)) 40 print('统计最多的10个单词及其词频') 41 workCount.output_result(word_freq)
接下来我们测试中调用我们写好的类。import我们写好的:lei.py
1 import lei 2 import argparse 3 if __name__ == '__main__': 4 parser = argparse.ArgumentParser(description="your script description") # description参数可以用于插入描述脚本用途的信息,可以为空 5 parser.add_argument('--file', '-file', type=str, default='src/test.txt', help="读取文件路径") 6 args = parser.parse_args() # 将变量以标签-值的字典形式存入args字典 7 dst = args.file 8 lei.workCount.print_result(dst) #此处为类的调用
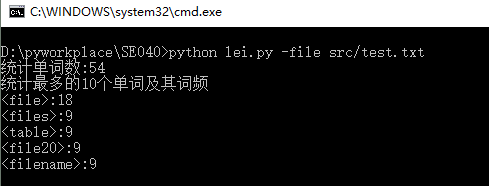
然后我们直接来看一下效果:如图2.1、2.2
先看一下src/test.txt里面写的啥:
接着看一下测试函数的效果:
2.1 测试函数在IDE中运行截图

2.2 测试函数在CMD中运行截图
Task 2. 增加新功能
本任务就是在任务一的基础上增加了新的功能,我们增加参数的数量,便可以实现。
看一下workCount类里面的代码。
1 import re 2 3 class workCount: 4 def __init__(self, dst, m, n, o): # dst:打开文件路径;m:词组长度;n:输出的单词数量;o表示输出文件的存储路径 5 self.dst = dst 6 self.m = m 7 self.n = n 8 self.o = o 9 10 def process_file(self): # 读取文件 11 lines = len(open(self.dst, 'r+').readlines()) # 借助readlines可以获得文本的行数 12 with open(self.dst) as f: 13 bvffer = f.read() 14 f.close() 15 return bvffer, lines 16 17 def process_buffer(self, bvffer): 18 if bvffer: 19 for ch in ':,.-_': 20 bvffer = bvffer.lower().replace(ch, " ") 21 counts = bvffer.strip().split() 22 regex = '' 23 for i in range(self.m): 24 regex += '[a-z]+' 25 if i < self.m - 1: 26 regex += '\s' 27 result = re.findall(regex, bvffer) # 正则查找词组 28 word_freq = {} 29 for word in result: # 将正则匹配的结果进行统计 30 word_freq[word] = word_freq.get(word, 0) + 1 31 return word_freq, len(counts) 32 33 def output_result(self, word_freq): 34 if word_freq: 35 sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True) 36 for item in sorted_word_freq[:self.n]: # 输出 Top 10 的单词 37 print('<' + str(item[0]) + '>:' + str(item[1])) 38 return sorted_word_freq[:self.n] 39 40 def print_result(self): # 输出结果 41 print('查询路径为:' + str(self.dst) + '的文本') 42 print('统计词组长度为:' + str(self.m) + '且词频前' + str(self.n) + '的单词') 43 buffer, lines = workCount.process_file(self) 44 word_freq, counts_words = workCount.process_buffer(self, buffer) 45 lines = 'lines:' + str(lines) 46 words = 'words:' + str(counts_words) 47 print(words) 48 print(lines) 49 items = workCount.output_result(self, word_freq) 50 with open(self.o, 'w+') as w: 51 w.write(lines+'\n') 52 w.write(words+'\n') 53 for item in items: # 格式化 54 item = '<' + str(item[0]) + '>:' + str(item[1]) + '\n' 55 w.write(item) 56 print('写入'+self.o+'文件已完成!') 57 w.close()
接下来我们看一下测试的代码。
1 import lei 2 import argparse 3 4 if __name__ == '__main__': 5 parser = argparse.ArgumentParser(description="your script description") # description参数可以用于插入描述脚本用途的信息,可以为空 6 parser.add_argument('--i', '-i', type=str, default='src/test.txt', help="读取文件路径") 7 parser.add_argument('--m', '-m', type=int, default=2, help="输出的单词数量") 8 parser.add_argument('--n', '-n', type=int, default=5, help="输出的单词个数") 9 parser.add_argument('--o', '-o', type=str, default='src/result.txt', help="写入文件路径") 10 args = parser.parse_args() # 将变量以标签-值的字典形式存入args字典 11 dst = args.i 12 m = args.m 13 n = args.n 14 o = args.o 15 obj = lei.workCount(dst, m, n, o) # 将参数传给类 16 obj.print_result() # 调用类里面的自定义的输出函数,将数据呈现出来
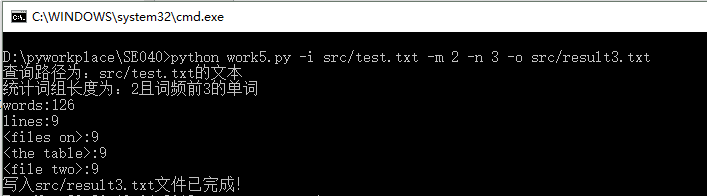
来看一下成果图吧!(就不一项项功能截图了,直接附上成果图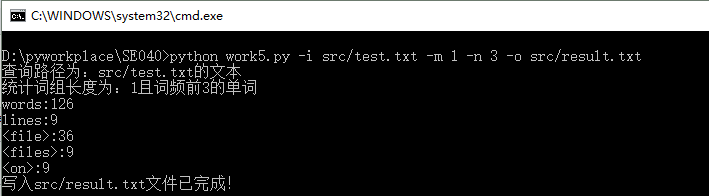
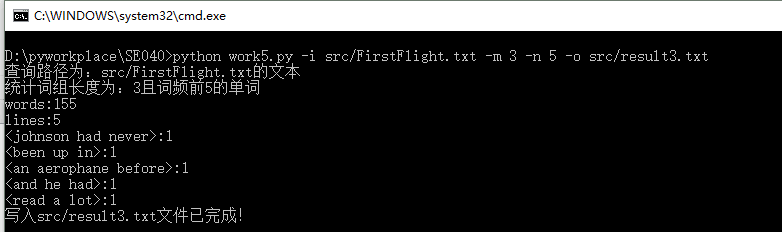
三、性能分析
因为本次代码基本都是用的作业四的,而且作业四代码性能都是之前调整到‘’我们觉得最佳‘’的,所以本次就没进行性能优化。因为文本的内容也很少所以程序运行还是很快的。

性能图表如下:
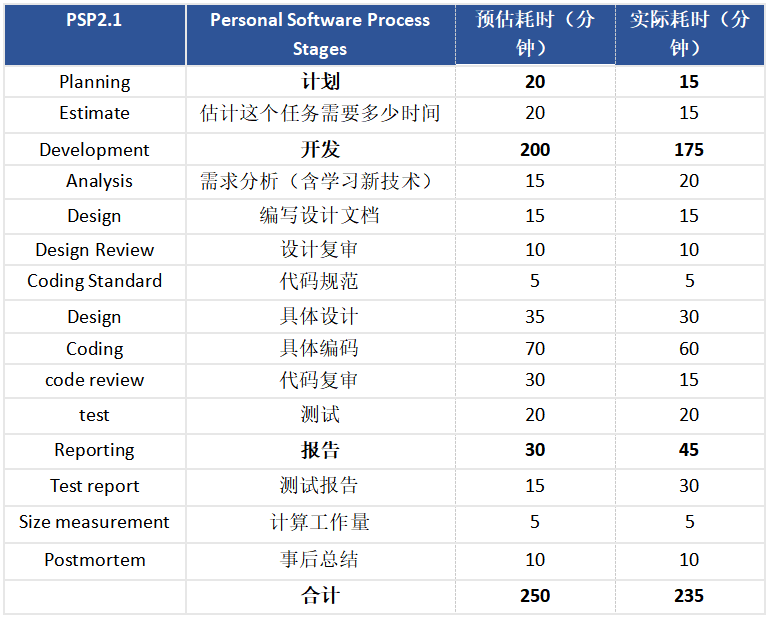
四、PSP 表格
仅根据实际估算,不一定很准确。
五、事后分析与总结
-
简述结对编程时,针对某个问题的讨论决策过程。
就cmd运行py脚本传参的问题,我们通过查询,找到了二种方法,1、sys.argv;2、 argparse模块。通过比较我们发现argparse模块对于传多个参数而且argparse模块还包含位置参数,这样让处理命令行参数很快捷和方便。
-
评价对方:请评价一下你的合作伙伴,又哪些具体的优点和需要改进的地方。 这个部分两人都要提供自己的看法。
高昶评价夏文杰:夏文杰本次相较于上次对python有了跟多的了解,就封装和传参提供了很不错的点子,所以我们这次作业花费的时间也比上次少了很多。需要改进的地方:还是和上次一样,多阅读、了解计算机相关的知识。
夏文杰评价高昶:高昶可以很快的将想法变成代码。需要改进的地方:基础需要巩固加强,且能够多变通。
-
评价整个过程:关于结对过程的建议
结对编程是一个相互学习、相互磨合的渐进过程,因为二人平时关系就很不错,二人都很认真的完成本次任务,所以本次的结对编程是很愉快的。通过本次结对编程我们也充分的认识到了合作的重要性,一个人编程不免要犯这样那样的错误,结对编程就很好的避免了这样的问题,而且二人会碰撞出更多的想法和灵感,二人相互学习,相互补充。而且结对编程能提供更好的设计质量和代码质量,两人合作能有更强的解决问题的能力。还有就是,结对编程让有些许枯燥的编程,变得有趣。
建议:结对编程是一件很不错的事情,但是结对编程的过程中难免发生争执,所以妥善处理好争议才能更好的将结对编程做好。
-
其它
经过2次的结对练习,我们的编程能力都有了些许提升,而且更加懂得了什么是合作!