斯坦福机器学习笔记
https://yoyoyohamapi.gitbooks.io/mit-ml/content/
在机器学习(Machine learning)领域,主要有三类不同的学习方法:监督学习(Supervised learning)、非监督学习(Unsupervised learning)、半监督学习(Semi-supervised learning)。
- 监督学习:通过已有的一部分输入数据与输出数据之间的对应关系,生成一个函数,将输入映射到合适的输出,例如回归分析和分类。如果我们想要预测的是离散值,例如“好瓜”“坏瓜”,此类学习任务称为“分类”;如果想要预测的是连续值,例如西瓜成熟度0.95、0.37,此类学习任务称为“回归”。学得模型后,使用其进行预测的过程称为“测试”,被预测的样本成为“测试样本”。例如在学得f后,对测试例x,可得到其预测标记y=f(x)。目前最广泛被使用的分类器有人工神经网络、支持向量机、最近邻居法、高斯混合模型、朴素贝叶斯方法、决策树和径向基函数分类。
- 非监督学习:直接对输入数据集进行建模,例如聚类。我们还可以对西瓜做“聚类”,即将训练集中的西瓜分为若干组,每组称为一个“簇”;这些自动形成的簇可能对应一些潜在的概念划分,例如“浅色瓜”“深色瓜”,甚至“本地瓜”“外地瓜”。这样的学习过程有助于我们了解数据内在的规律,能为更深入地分析数据简历基础。需说明的是,在聚类学习中,“浅色瓜”“本地瓜”这样的概念我们事先是不知道的,而且学习过程中使用的训练样本通常不拥有标记信息。
- 半监督学习:综合利用有类标的数据和没有类标的数据,来生成合适的分类函数。
- 区别:监督学习其实就是我们对输入样本经过模型训练后有明确的预期输出,非监督学习就是我们对输入样本经过模型训练后得到什么输出完全没有预期。
For details:https://blog.csdn.net/u011067360/article/details/24735415
线性回归
预测
首先,我们明确几个常用的数学符号:
- 特征(feature):xi, 比如,房屋的面积,卧室数量都算房屋的特征
- 特征向量(输入):x,一套房屋的信息就算一个特征向量,特征向量由特征组成,xj(i) 表示第 i 个特征向量的第 j 个特征。
- 输出向量:y,y(i) 表示了第 i 个输入所对应的输出
- 假设(hypothesis):也称为预测函数,比如一个线性预测函数是:
hθ(x)=θ0+θ1x1+θ2x2+⋯+θnxn=θTx
上面的表达式也称之为回归方程(regression equation),θ 为回归系数,它是我们预测准度的基石。
误差评估
之前我们说到,需要某个手段来评估我们的学习效果,即评估各个真实值 y(i) 与预测值 hθ(x(i)) 之间的差异。最常见的,我们通过最小均方(Least Mean Square)来描述误差:
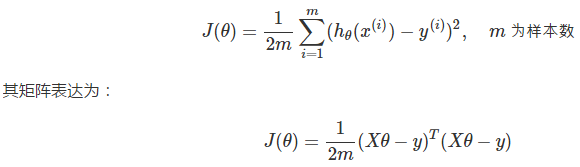
误差评估的函数在机器学习中也称为代价函数(cost function)。
例子:申请贷款时,工资和年龄为指标,即特征x1和x2。用这两个指标去预测一下银行给你贷款多少钱(回归分析)。但这两个指标的影响程度是不一样的,所以θ1和θ2为权重参数就代表了特征的影响程度,是工资大一些还是年龄大一些。hθ(x)代表银行最终会贷给你多少钱,这样hθ(x)=y,y代表额度,也就是标签值。假设X0恒等于1,这样 hθ(x)=θ0+θ1x1+θ2x2+⋯+θnxn=θTx 可以转换成hθ(x)=Σθixi = θTx 。

用最小二乘法来评估真实值 y(i) 与预测值 hθ(x(i)) 之间的差异ξ(i)。

红色的值为预测值,预测值有可能比真实值高或低,
