版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/mr_muli/article/details/84590840
- 机器学习之agglomerative_clustering-层次聚类
# -*- coding: utf-8 -*-
"""
Created on Wed Nov 28 19:07:54 2018
@author: muli
"""
import numpy as np
from sklearn.datasets.samples_generator import make_blobs
from sklearn import cluster
from sklearn.metrics import adjusted_rand_score
import matplotlib.pyplot as plt
def create_data(centers,num=100,std=0.7):
'''
生成用于聚类的数据集
:param centers: 聚类的中心点组成的数组。如果中心点是二维的,则产生的每个样本都是二维的。
:param num: 样本数
:param std: 每个簇中样本的标准差
:return: 用于聚类的数据集。是一个元组,第一个元素为样本集,第二个元素为样本集的真实簇分类标记
'''
X, labels_true = make_blobs(n_samples=num, centers=centers, cluster_std=std)
return X,labels_true
def test_AgglomerativeClustering(*data):
'''
测试 AgglomerativeClustering 的用法
:param data: 可变参数。
它是一个元组。元组元素依次为:第一个元素为样本集,第二个元素为样本集的真实簇分类标记
:return: None
'''
X,labels_true=data
clst=cluster.AgglomerativeClustering()
predicted_labels=clst.fit_predict(X)
print("ARI:%s"% adjusted_rand_score(labels_true,predicted_labels))
def test_AgglomerativeClustering_nclusters(*data):
'''
测试 AgglomerativeClustering 的聚类结果随 n_clusters 参数的影响
:param data: 可变参数。它是一个元组。元组元素依次为:第一个元素为样本集,第二个元素为样本集的真实簇分类标记
:return: None
'''
X,labels_true=data
nums=range(1,50)
ARIs=[]
for num in nums:
clst=cluster.AgglomerativeClustering(n_clusters=num)
predicted_labels=clst.fit_predict(X)
ARIs.append(adjusted_rand_score(labels_true,predicted_labels))
## 绘图
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
ax.plot(nums,ARIs,marker="+")
ax.set_xlabel("n_clusters")
ax.set_ylabel("ARI")
fig.suptitle("AgglomerativeClustering")
plt.show()
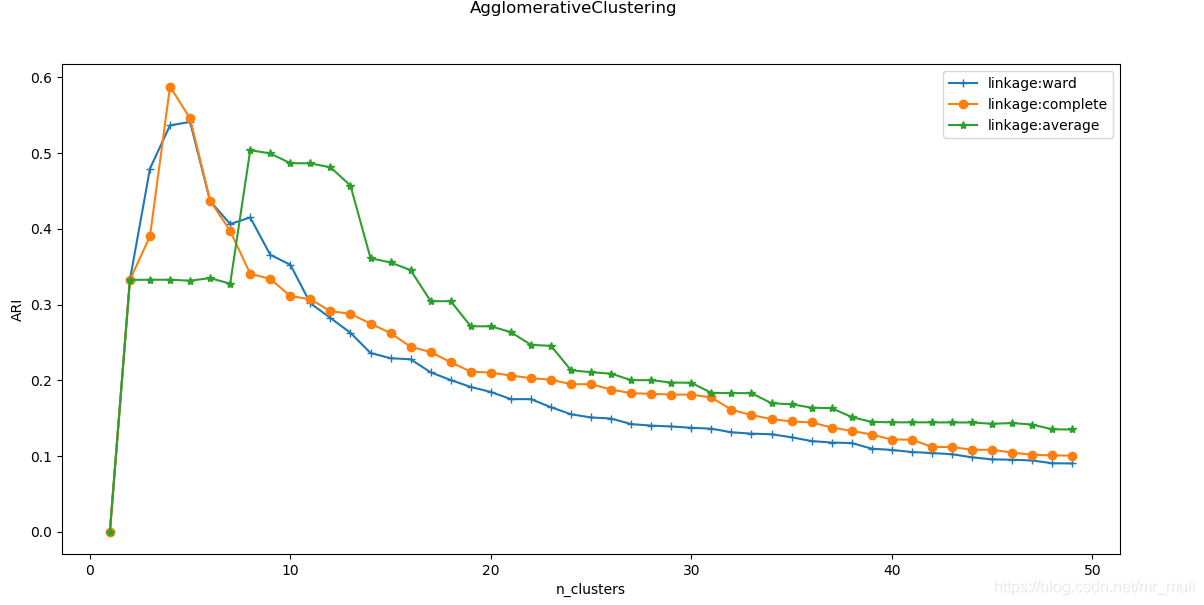
def test_AgglomerativeClustering_linkage(*data):
'''
测试 AgglomerativeClustering 的聚类结果随链接方式的影响
:param data: 可变参数。它是一个元组。元组元素依次为:第一个元素为样本集,第二个元素为样本集的真实簇分类标记
:return: None
'''
X,labels_true=data
nums=range(1,50)
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
# 链接方式的影响
linkages=['ward','complete','average']
markers="+o*"
for i, linkage in enumerate(linkages):
ARIs=[]
for num in nums:
clst=cluster.AgglomerativeClustering(n_clusters=num,linkage=linkage)
# 预测
predicted_labels=clst.fit_predict(X)
# ARI指数
ARIs.append(adjusted_rand_score(labels_true,predicted_labels))
ax.plot(nums,ARIs,marker=markers[i],label="linkage:%s"%linkage)
ax.set_xlabel("n_clusters")
ax.set_ylabel("ARI")
ax.legend(loc="best")
fig.suptitle("AgglomerativeClustering")
plt.show()
if __name__=='__main__':
centers=[[1,1],[2,2],[1,2],[10,20]] # 用于产生聚类的中心点
X,labels_true=create_data(centers,1000,0.5) # 产生用于聚类的数据集
# test_AgglomerativeClustering(X,labels_true) # 调用 test_AgglomerativeClustering 函数
# test_AgglomerativeClustering_nclusters(X,labels_true) # 调用 test_AgglomerativeClustering_nclusters 函数
test_AgglomerativeClustering_linkage(X,labels_true) # 调用 test_AgglomerativeClustering_linkage 函数
- 如图所示: