一、场景引入
本人所在的项目由于直接面向消费者,迭代周期迅速,所以服务端框架一直采用Springboot+dubbo的组合模式,每个服务由service模块+web模块构成,service模块通过公司API网关向安卓端暴
露restful接口,web模块通过dubbo服务向service模块获取数据渲染页面。测试环境dubbo的注册中心采用的单实例的zookeeper,随着时间的发现注册在zookeeper上的生产者和消费者越来越多,测试
人员经常在大规模的压测后发现zookeeper挂掉的现象。因为自己用过springcloud,所以想由此谈一下springcloud是如何对注册中心集群化以及如何应对高并发场景的。
二、Spring Cloud的注册中心 Eureka
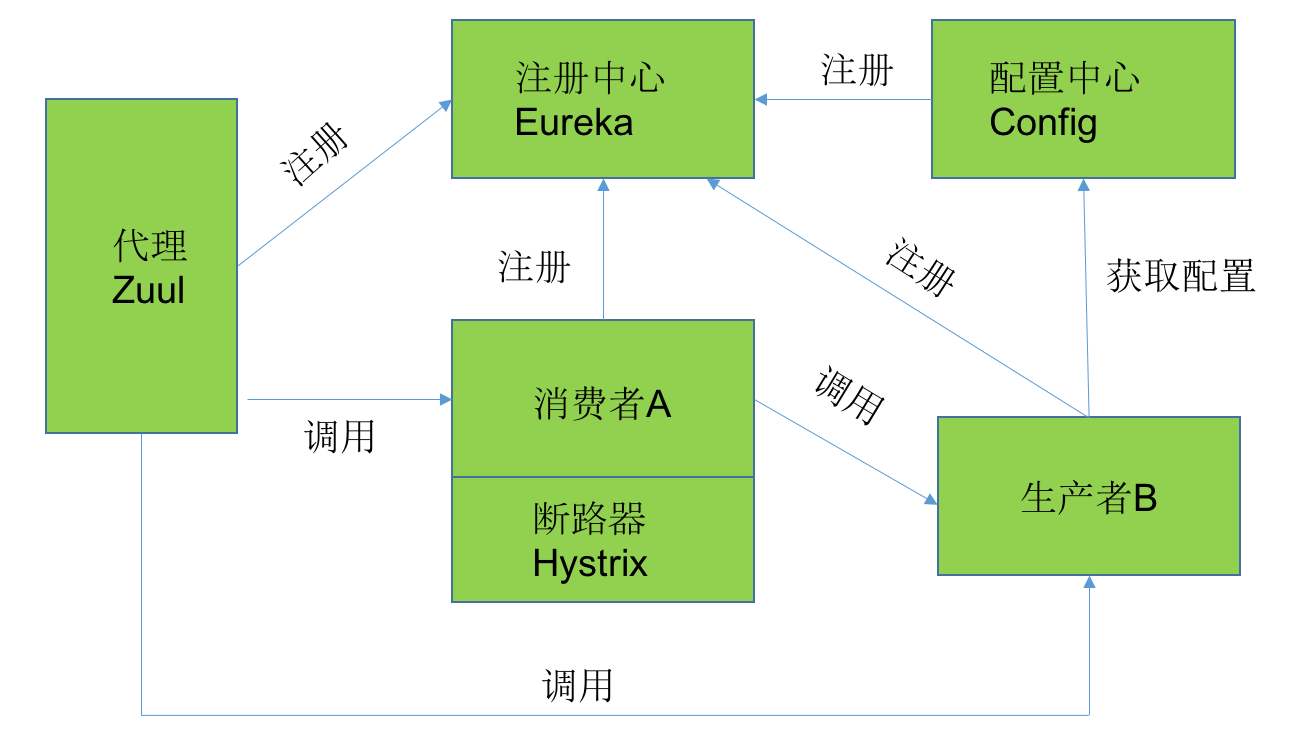
首先看一下Spring Cloud的架构,整个架构图在抽象之后大概就是这个样子。Spring cloud Eureka是Spring Cloud Netflix 微服务套件中的一部分,它基于 Netflix做了二次封装,主要负责完成
微服务架构中的服务治理功能。不同于dubbo注册中心的是:dubbo的注册中心是第三方组件,可以是zookeeper、可以是Redis。而Spring Cloud的注册中心不是第三方组件,而是自身二次封装专门用于服
务注册与服务发现的注册中心,在使用时只需要依赖相应的jar包即可。
三、注册中心集群化
在微服务这样的分布式架构中,我们要考虑故障发生的场景,所以在生产环境中要对各组件进行高可用部署,即集群化。故springcloug的注册中心也一样,生产环境中单节点的注册中心显然是十
分不安全的,我们需要构建高可用的服务注册中心以增强系统的可用性。
EurekaServer在设计之初就考虑到了高可用问题,在Eureka的服务治理设计中,所有节点既是服务提供者同时也是服务消费者。Eureka Server的高可用实际上就是将自己作为服务向其他服务注
册中心注册自己,从而形成一组互相注册的服务注册中心,因此能够实现服务清单的互相同步,达到服务高可用的效果,例如构建一个双节点的注册中心:
• 创建application-dev1.properties作为注册中心1的配置,并将serviceUrl指向注册中心2(dev2):
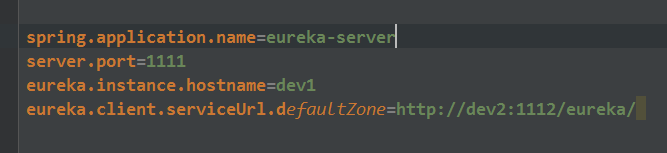
• 创建application-dev2.properties作为注册中心2的配置,并将serviceUrl指向注册中心1(dev1):

然后分别启动两个服务即可组成双节点的注册中心,若集群不止两个实例,只需要在eureka.client.serviceUrl.defaultZone配置项后面用","隔开然后启动项目即可。此时启动服务提供者与服务消费
者,客户端是分别注册到每一个注册中心的实例上的,若此时断开一个或者几个注册中心实例,只要集群中还有实例存活就依然可以提供正常服务,从而实现了服务注册中心的高可用。
四、注册中心与高并发
Spring Cloud的架构体系中,Eureka扮演着一个至关重要的角色,所有的服务注册与服务发现都是依赖着Eureka。上面介绍了注册中心的集群化,那真正的生产环境中注册中心到底要部署多少台?Eureka能不能抗住系统中大量的并发访问?想要弄清楚这个,先从注册中心与客户端的工作原理说起。
首先,各个服务内的Eureka Client在默认情况下每隔30s发送一个请求到Eureka Server来拉取最近有变化的服务信息。
举个栗子~
电商的支付模块原本是部署在1台机器上,现在增加部署实例,部署到3台机器上,并且都已经注册到Eureka Server上,然后Eureka Client会每隔30s去Eureka Server拉取注册表信息的变化,看
服务的地址有没有变化。
其次,Eureka有一个心跳机制,各个Eureka Client每隔30s会发送一次心跳数据到Eureka Server,告诉注册中心自己还活着。如果某个Eureka Client很长时间没有发送心跳数据给Eureka
Server,那么就说明这个实例已经挂了!
在另一方面,服务注册中心这种组件在一开始设计的时候,它的拉取频率及心跳发送机制就已经兼顾到了一个大型系统的各个服务请求的压力,每秒能够承受多大的请求量。默认的30s时间间隔
其实是经过理论上研究后得出的。一个上百个服务,几千台机器的服务系统,按照这个体量请求Eureka Server,日请求量大概在千万级,每秒的访问量大概在160次左右,再加上一些其他的请求操
作,每秒在200次左右。所以通过设置一个拉取注册表及心跳发送机制来保证高并发下场景下Eureka Server的压力不会太大。
那么问题来了,Eureka Server是如何抗住每秒200次的请求的呢?
这个问题其实看源码即可一目了然,Eureka Server注册表的核心是一个CocurrentHashMap,也就是说整个注册表的数据时完全存储在内存里的,各个服务的注册、下线、故障、全部会在内存中维护
和更新。也就是说,Eureka Client每隔30s拉取注册信息和发送心跳数据也是完全基于内存,这个是能抗住每秒200次并发重要原因之一!
通过以上分析,Eureka通过设置适当的请求频率(拉取注册信息30s间隔,发送心跳数据30s间隔)可以保证一个大规模的系统每秒的请求在200次左右,同时通过内存维护注册表信息,保证了所
有的请求都在内存中处理,确保了性能。所以在生产环境中到底需要部署多少台注册中心的实例,还是要根据自身系统的访问体量大小决定。