版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_22830285/article/details/84347646
通过构建一个简单的项目工程,围绕对实现分布式文件系统HDFS 的操作展开学习。
参考资料:华为大数据 模块2 HDFS的应用开发。
hadoop 集群的搭建可参考:
https://mp.csdn.net/mdeditor/84288315
jdk 版本:1.8
一、使用maven 创建一个简单的 maven project,
至于maven 项目怎么搭建,网上有很多资料,自行查看。我这里贴上我使用的pom.xml 配置。
<repositories>
<repository>
<id>nexus</id>
<name>nexus</name>
<url>http://central.maven.org/maven2/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>2.1.1</version>
<exclusions>
<exclusion>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-cli</artifactId>
<version>2.1.1</version>
<exclusions>
<exclusion>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.4</version>
<exclusions>
<exclusion>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>dom4j</groupId>
<artifactId>dom4j</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz</artifactId>
<version>1.8.6</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.7</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>0.10.2.0</version>
<exclusions>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.10.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>1.1.1</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka</artifactId>
<version>1.1.1</version>
</dependency>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.8</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
</dependencies>
三、创建一个类,
public class HDFSUtil {
private static Configuration conf = null;// 申明配置属性值对象
static {
conf = new Configuration();
// 指定hdfs的nameservice为cluster1,是NameNode的URI
conf.set("fs.defaultFS", "hdfs://cluster1");
// 指定hdfs的nameservice为cluster1
conf.set("dfs.nameservices", "cluster1");
// cluster1下面有两个NameNode,分别是nna节点和nns节点
conf.set("dfs.ha.namenodes.cluster1", "nna,nns");
// nna节点下的RPC通信地址
conf.set("dfs.namenode.rpc-address.cluster1.nna", "nna:9000");
// nns节点下的RPC通信地址
conf.set("dfs.namenode.rpc-address.cluster1.nns", "nns:9000");
// 实现故障自动转移方式
conf.set("dfs.client.failover.proxy.provider.cluster1", "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider");
}
/** 目录列表操作,展示分布式文件系统(HDFS)的目录结构 */
public static void ls(String remotePath) throws IOException {
FileSystem fs = FileSystem.get(conf); // 申明一个分布式文件系统对象
Path path = new Path(remotePath); // 得到操作分布式文件系统(HDFS)文件的路径对象
FileStatus[] status = fs.listStatus(path); // 得到文件状态数组
Path[] listPaths = FileUtil.stat2Paths(status);
for (Path p : listPaths) {
System.out.println(p); // 循环打印目录结构
}
}
//此操作只能将dfs系统上的文件添加到 hdfs,
public static void put(String repath,String localPath) throws IOException {
FileSystem fs=FileSystem.get(conf);
Path remotePath=new Path(repath);
Path local=new Path(localPath);
fs.copyFromLocalFile(remotePath, local);
fs.close();
}
//读取文件,参考 华为大数据HDFS应用开发.教程
public static void cat(String rmpath) throws IOException {
//加载配置文件
FileSystem fs=FileSystem.get(conf);
Path remotePath=new Path(rmpath);
FSDataInputStream is=null;
try{
if(fs.exists(remotePath)) {
//打开分布式操作对象
is=fs.open(remotePath);
//读取
BufferedReader br=new BufferedReader(new InputStreamReader(is));
//字符串拼接
StringBuffer sb=new StringBuffer();
String ltxt;
while((ltxt=br.readLine())!=null) {
sb.append(ltxt+"\n");
}
System.out.println(sb);
}
}catch(Exception e) {
e.printStackTrace();
}finally {
is.close();
fs.close();
}
}
//创建目录
public static boolean createPath(String path) throws IOException {
FileSystem fs=FileSystem.get(conf);
Path pa=new Path(path);
if(!fs.exists(pa)) {
fs.mkdirs(pa);
}else {
return false;
}
return true;
}
//添加文件
//fullname 文件的全称,并非是文件夹
//local 本机目录
//changeFlag 是做添加操作,还是追加内容操作,“add” 时为添加,其他为追加
public static void changeFile(String fullname,String localpath,String changeFlag) throws IOException {
FileSystem fs=FileSystem.get(conf);
Path filepath=new Path(fullname);
//初始化FSDataOutputStream对象
FSDataOutputStream is="add".equals(changeFlag)?fs.create(filepath):fs.append(filepath);
//初始化 化BufferedOutputStream 对象
BufferedOutputStream bufferOutStream=new BufferedOutputStream(is);
//获取数据源
File file=new File(localpath);
InputStream iss=new FileInputStream(file);
// bufferOutStream.write();
byte buff[]=new byte[10240];
int count;
while((count=iss.read(buff,0,10240))>0) {
//BufferedOutputStream.write写入hdfs数据
bufferOutStream.write(buff,0,count);
}
//刷新数据
iss.close();
bufferOutStream.flush();
is.hflush();
}
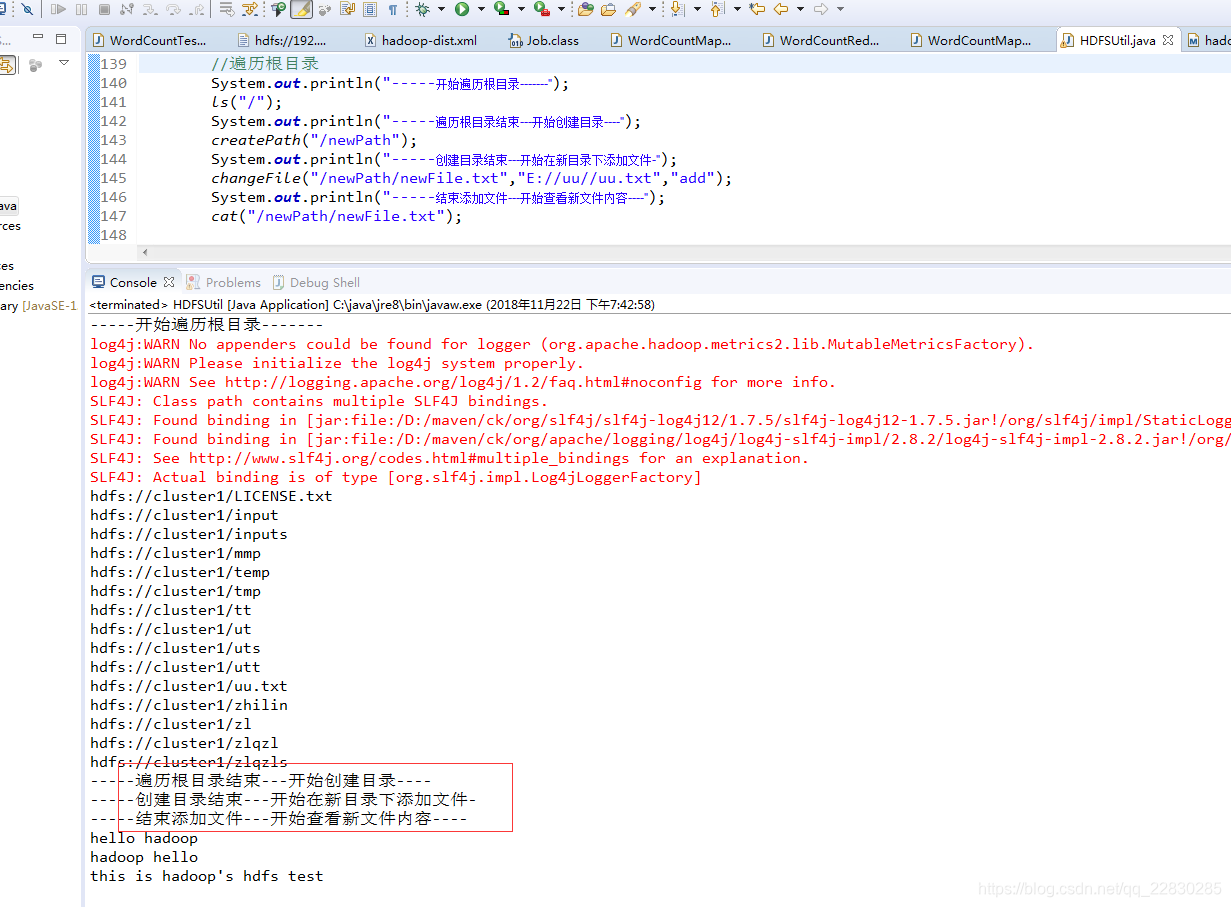
public static void main(String[] args) throws IOException {
System.out.println("-----开始遍历根目录-------");
ls("/");
System.out.println("-----遍历根目录结束---开始创建目录----");
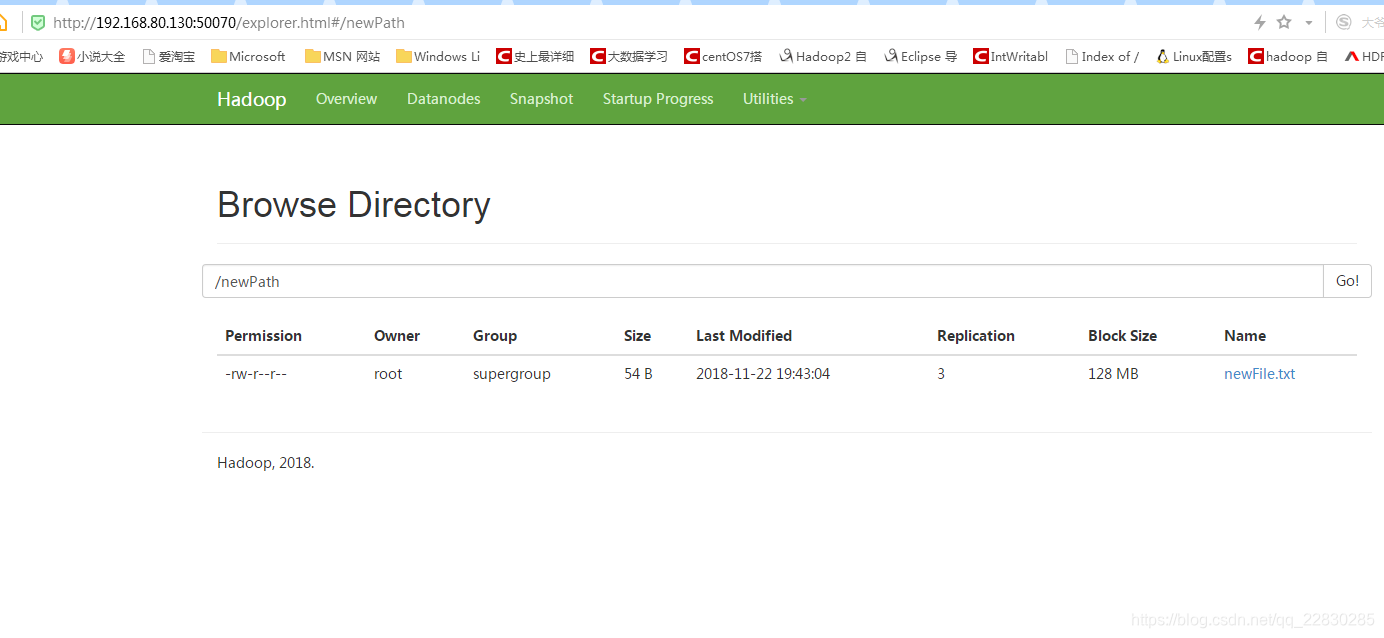
createPath("/newPath");
System.out.println("-----创建目录结束---开始在新目录下添加文件-");
changeFile("/newPath/newFile.txt","E://uu//uu.txt","add");
System.out.println("-----结束添加文件---开始查看新文件内容----");
cat("/newPath/newFile.txt");
}
}
测试结果!
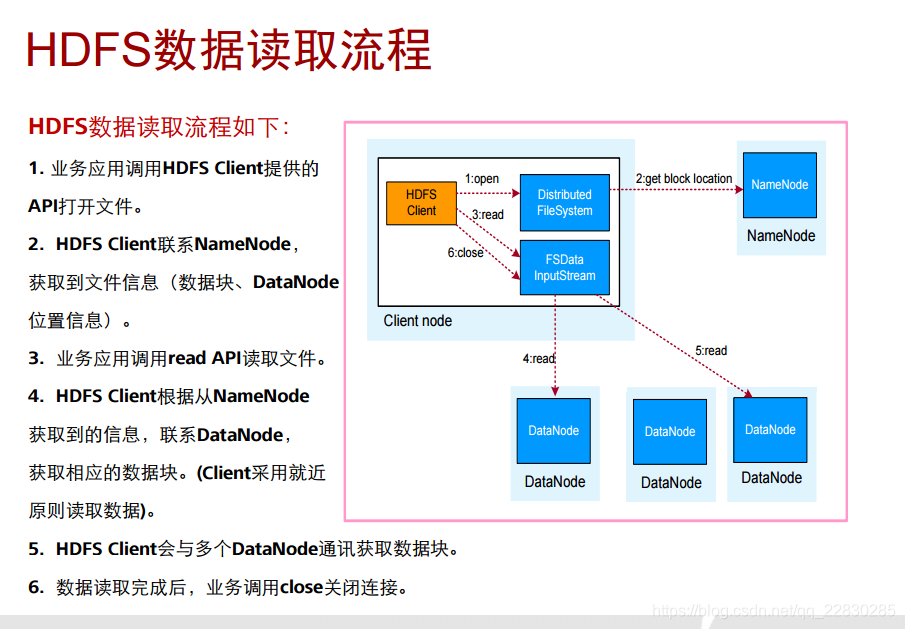
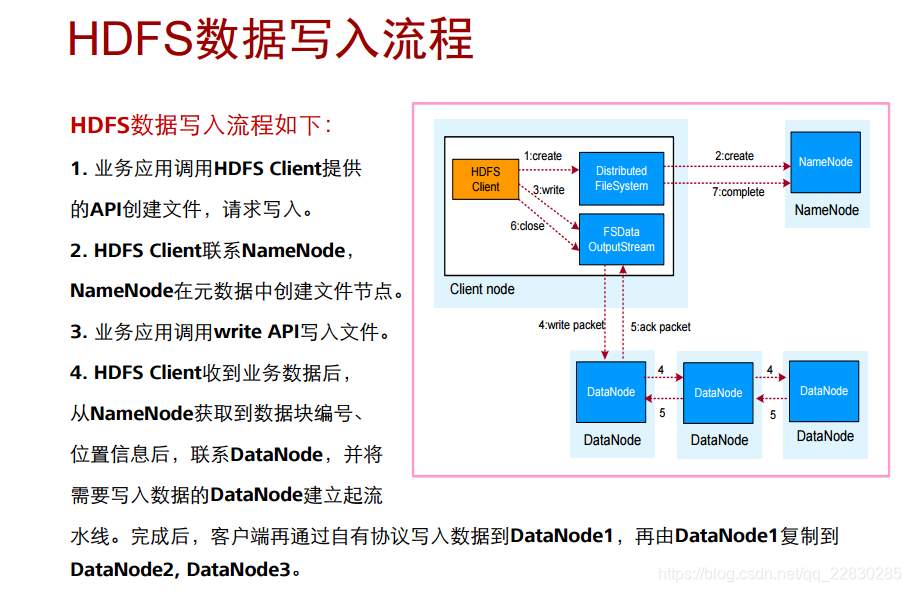
一些流程原理