环境:
CPU: I7
GPU: GTX1070 计算能力: 6.1 设备ID: 0
参考:
https://blog.csdn.net/hitzijiyingcai/article/details/81914200
特别谢谢这篇作者大大。谢谢
代码的话还是推荐下载这个版本的,不是论文上的那个,论文的可能太老了。
https://github.com/saizhang12/Faster-RCNN_TF
一、运行demo
1.下载代码
这里的代码是Python2.7,TensorFlow1.8.1的才能跑
git clone --recursive https://github.com/smallcorgi/Faster-RCNN_TF.git这里的代码是Python2.7,TensorFlow1.10.1的实测能跑(我就是用这个代码)
git clone --recursive https://github.com/saizhang12/Faster-RCNN_TF电脑手动下载,上传到服务器-----具体教程:https://blog.csdn.net/a1103688841/article/details/84113046
我使用的是WinSCP进行上传:

结果:

2.进入根目录创建两个文件夹放文件
cd Faster-RCNN_TF-master/
在下载了整个文件夹之后,要自己手动新建几个文件夹,否则后面会报错,一个是在根目录下新建一个output文件夹,另一个是在experiments文件夹下新建一个logs文件夹。
mkdir output
cd experiments/
mkdir logs
cd ..3.建立cyphon模块
在下载的Faster RCNN的lib目录下make
1.先查看当前根路径
pwd结果如下图:
![]()
2.接下来进行在lib目录下的make
FRCN_ROOT=/root/faster_rcnn/Faster-RCNN_TF-master/
cd $FRCN_ROOT/lib
make4.下载预训练模型
在这里提供一个百度云下载地址: 链接:https://pan.baidu.com/s/1zNWzMxBwQ6qVoXXvN89Peg 密码:0rtb
下载完成之后,在tools文件夹下新建一个名称为model的文件夹,把下载好的模型放进去
cd $FRCN_ROOT/tools/
mkdir model
使用的是WinSCP上传 VGGnet_fast_rcnn_iter_70000.ckpt 文件
cd $FRCN_ROOT/
5.运行demo
这边有几个错误必须先改否者会报错。
1、g++: error: roi_pooling_op.cu.o: No such file or directory 需要(1)(2)小点
5.make.sh: line 14: nvcc: command not found 只需要(1)小点
解决:Setting the following should make it work (it worked at least for me)
(1) export PATH=$PATH:/usr/local/cuda-8.0/bin/ (or your corresponding cuda path) for your terminal
这里有一个小坑就是我的cuda的版本是9.0所以使cuda-9.0
所以应该写:export PATH=$PATH:/usr/local/cuda-9.0/bin/
(2) In make.sh file inside lib directory, do CXXFLAGS='-D_MWAITXINTRIN_H_INCLUDED' (改lib下的make.sh)
3、ensorflow.python.framework.errors.NotFoundError: /home/Projects/Faster-RCNN_TF/tools/../lib/roi_pooling_layer/roi_pooling.so: undefined symbol: _ZN10tensorflow7strings6StrCatB5cxx11ERKNS0_8AlphaNumE
解决: revise the CUDA_PATH and add -D_GLIBCXX_USE_CXX11_ABI=0 in /lib/make.sh
update as:
g++ -std=c++11 -shared -o roi_pooling.so roi_pooling_op.cc -D_GLIBCXX_USE_CXX11_ABI=0 \
roi_pooling_op.cu.o -I $TF_INC -D GOOGLE_CUDA=1 -fPIC $CXXFLAGS \
-lcudart -L $CUDA_PATH/lib64 2.这里还会报错no display name and no $DISPLAY environment variable
参考:https://blog.csdn.net/a1103688841/article/details/84113062

4.TensorFlow的版本错误。这时候要返回第一步看一下是不是下载错误了
错误参考
https://github.com/smallcorgi/Faster-RCNN_TF/issues/316
I have encountered the Nontype error when I run demo and train. I do exactly the same thing in Readme. Can anybody help me solve this problem?
Tensor("data:0", shape=(?, ?, ?, 3), dtype=float32)
Tensor("conv5_3/Relu:0", shape=(?, ?, ?, 512), dtype=float32)
Tensor("rpn_conv/3x3/Relu:0", shape=(?, ?, ?, 512), dtype=float32)
Tensor("rpn_conv/3x3/Relu:0", shape=(?, ?, ?, 512), dtype=float32)
Tensor("rpn_cls_score/BiasAdd:0", shape=(?, ?, ?, 18), dtype=float32)
Tensor("gt_boxes:0", shape=(?, 5), dtype=float32)
Tensor("gt_ishard:0", shape=(?,), dtype=int32)
Tensor("dontcare_areas:0", shape=(?, 4), dtype=float32)
Tensor("im_info:0", shape=(?, 3), dtype=float32)
Tensor("rpn_cls_score/BiasAdd:0", shape=(?, ?, ?, 18), dtype=float32)
Tensor("rpn_cls_prob:0", shape=(?, ?, ?, ?), dtype=float32)
Tensor("Reshape_2:0", shape=(?, ?, ?, 18), dtype=float32)
Tensor("rpn_bbox_pred/BiasAdd:0", shape=(?, ?, ?, 36), dtype=float32)
Tensor("im_info:0", shape=(?, 3), dtype=float32)
Tensor("rpn_rois:0", shape=(?, 5), dtype=float32)
Tensor("gt_boxes:0", shape=(?, 5), dtype=float32)
Tensor("gt_ishard:0", shape=(?,), dtype=int32)
Tensor("dontcare_areas:0", shape=(?, 4), dtype=float32)
Tensor("conv5_3/Relu:0", shape=(?, ?, ?, 512), dtype=float32)
Tensor("roi-data/rois:0", shape=(?, 5), dtype=float32)
[<tf.Tensor 'conv5_3/Relu:0' shape=(?, ?, ?, 512) dtype=float32>, <tf.Tensor 'roi-data/rois:0' shape=(?, 5) dtype=float32>]
Traceback (most recent call last):
File "./faster_rcnn/train_net.py", line 101, in
network = get_network(args.network_name)
File "./faster_rcnn/../lib/networks/factory.py", line 29, in get_network
return VGGnet_train()
File "./faster_rcnn/../lib/networks/VGGnet_train.py", line 17, in init
self.setup()
File "./faster_rcnn/../lib/networks/VGGnet_train.py", line 85, in setup
.fc(4096, name='fc6')
File "./faster_rcnn/../lib/networks/network.py", line 36, in layer_decorated
layer_output = op(self, layer_input, *args, **kwargs)
File "./faster_rcnn/../lib/networks/network.py", line 377, in fc
feed_in, dim = (input, int(input_shape[-1]))
TypeError: int returned non-int (type NoneType)这边有一个巨坑.......就是在生产神经网络的的fc层的前一个roi poo
ling层出错,原因是TensorFlow的版本问题,听说别人用1.8.1的版本成功了,我的是1.10.1的版本失败了。
6.还有什么错误??不记得了,可以留言补充看我还记得不.
最后在Faster RCNN根目录下执行:
python ./tools/demo.py --model $FRCN_ROOT/tools/model/VGGnet_fast_rcnn_iter_70000.ckpt=======================================================================================
二、下载数据并预训练
下面大部分参考:https://blog.csdn.net/hitzijiyingcai/article/details/81914200 特别感谢博主,经常回我,指点迷津
1、下载 VOCdevkit的训练验证和测试集
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCdevkit_08-Jun-2007.tar
2、解压上面下载的三个压缩包
tar xvf VOCtrainval_06-Nov-2007.tar
tar xvf VOCtest_06-Nov-2007.tar
tar xvf VOCdevkit_08-Jun-2007.tar
严格按照命令解压,这样解压后的文件嵌套形式不会变。
三个压缩文件解压后文件存储在一个文件夹VOCdekit下,这个文件夹下包含VOCcode和VOC2007等文件夹,结构如下:
$VOCdevkit/ # development kit
$VOCdevkit/VOCcode/ # VOC utility code
$VOCdevkit/VOC2007 # image sets, annotations, etc.
# ... and several other directories ...
3、重命名
将下载的数据集文件夹VOCdevkit修改名字为VOCdevkit2007放入faster rcnn目录下的Data文件夹里。
cd $FRCN_ROOT/data
mv VOCdevkit VOCdevkit2007 也可以通过以下代码实现,改名字是因为代码中是VOCdevkit2007
cd $FRCN_ROOT/data
ln -s $VOCdevkit VOCdevkit2007
4、下载预训练模型
此处下载的目的是将其参数作为我们训练模型的初始化参数:
下载地址:https://download.csdn.net/download/a1103688841/10798076
此处为下载VGG_imagenet.npy,下载完成之后在faster rcnn目录下的data文件夹下新建文件夹pretrain_model,将下载好的预训练模型VGG_imagenet.npy放进去。
5、训练模型
在根目录下:
./experiments/scripts/faster_rcnn_end2end.sh gpu 0 VGG16 pascal_voc
在这里要注意,源码中的迭代次数为70000次,为了节约时间完成对源码的运行测试,可将experiments/scripts/faster_rcnn_end2end.sh文件、lib/fast_rcnn/config.py文件中的迭代次数此改为小一点数(具体格式可参看后文)。本人将其修改为了200。(200是重点,下面生成的权重名的结尾就是200)
NB:训练和测试模型中遇到的错误:
(1)训练完模型后会出现如下错误

这是因为tensorflow问题并没有在/output/faster_rcnn_end2end/voc_2007_trainval 中生成VGGnet_fast_rcnn_iter_70000.ckpt文件。
解决方法:
在FASTER-RCNN_TF/lib/fast_rcnn/train.py 文件中:
将saver = tf.train.Saver(max_to_keep=100)改为:
saver = tf.train.Saver(max_to_keep=100,write_version=saver_pb2.SaverDef.V1)
同时,在文件开头加上:from tensorflow.core.protobuf import saver_pb2
在这里要注意,上述修改后,再次训练时,会出现如下提示:

这是在保存迭代文件时提示V1版本过低建议使用V2,此时千万不要改为V2,否则在修改完之后会持续提示:
Waiting for ../output/faster_rcnn_end2end/voc_2007_trainval/VGGnet_fast_rcnn_iter_200.ckpt to exist...
这是没法生成ckpt文件,即使在output文件夹下可以看到生成了一些结果文件,但是没法生成ckpt文件,因此上述不要改成V2。
6、测试模型
在修改完上述错误之后,运行如下代码进行测试:
python ./tools/test_net.py --device gpu --device_id 0 --weights output/faster_rcnn_end2end/voc_2007_trainval/VGGnet_fast_rcnn_iter_200.ckpt --imdb voc_2007_test --cfg experiments/cfgs/faster_rcnn_end2end.yml --network VGGnet_test
测试结果:
可以看到在测试结果中出现了负值,这是完全不对的,这是由于迭代次太少的原因,因此又将迭代次数进行了修改,改为了2000,得到了如下结果:
可以看出,AP仍然非常小,但是作为测试运行代码来说,是正确的结果就可以了。
三、用自己的数据集进行训练、测试
1、制作数据集
这边新开一个帖子将我自己的制作
2.修改代码
(1)lib/datatsets/pascal_voc.py

修改为自己的类别。
(2)lib/datasets/imdb.py

这里将num_classes改为自己的类别数+1,本人定义了1类,因此是2。
(3)lib/networks/VGGnet_train.py

将类别数改为2。同理,VGGnet_test.py修改同上

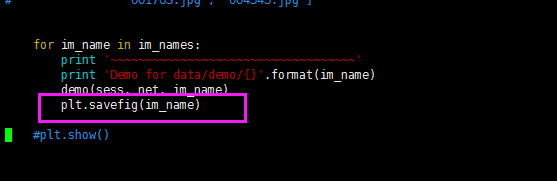
(4)tools/demo.py
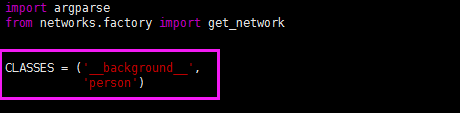
为了测试demo.py的方便,所以也把tools/demo.py中的类别改成自己的类别。
(5)修改迭代次数等参数
首先在experiments/scripts/faster_rcnn_end2end.sh文件中修改迭代次数:
(在ITERS中修改成自己想要的参数)

然后,我们进入lib/fast_rcnn/config.py,对config.py进行修改:
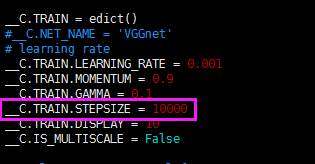
其中,第一项,就是学习率。
关于模型保存问题:
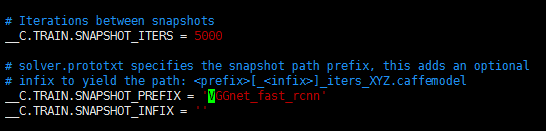
第一个参数是训练时,每迭代多少次保存一次模型;
第二个参数是保存时模型的名字。
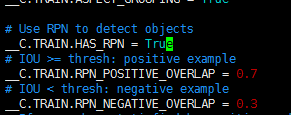
将rpn检测目标设置为True:
3、训练数据
进入你的Faster-rcnn文件夹根目录,然后直接输入:
./experiments/scripts/faster_rcnn_end2end.sh gpu 0 VGG16 pascal_voc这边训练的时候会报一个警告:RuntimeWarning: invalid value encountered in log

参考:https://www.jianshu.com/p/1168fe20cc23
这是你数据集的边界问题 ,计算的时候出现的负数,添加这些语句来改错误。


def _get_height(self):
return [PIL.Image.open(self.image_path_at(i)).size[1]
for i in xrange(self.num_images)]
...........................................................
assert (boxes[:,0]!=65535).all()
assert (boxes[:,1]!=65535).all()
assert (boxes[:,2]!=65535).all()
assert (boxes[:,3]!=65535).all()
assert (boxes[:,1]>=0).all()
assert (boxes[:,3]<heights[i]).all()
assert (boxes[:,3]>=boxes[:,1]).all()
assert (oldx1>=0).all()
assert (oldx2<widths[i]).all()
assert (boxes[:, 2] >= boxes[:, 0]).all()
4、测试数据
这边测试我没做
5.运行
最后,可以运行demo看看实际框出的效果图:
python ./tools/demo.py --model output/faster_rcnn_end2end/voc_2007_trainval/VGGnet_fas最后插一张人模狗样的效果图和一张漂亮小姐姐:

