在遇到线程安全问题的时候,我们一般都是使用同步来解决,比如内置锁、显示锁等等。线程安全的主要起因是因为多个线程同时操作一个共享变量,如果我们换种思路,在某些场景下,我们为这些线程提供共享变量的副本,让他们在自己的私有域中去操作这些变量,线程之间互不影响,那是不是就不会产生线程安全问题了?ThreadLocal提供了这样的一种实现。
ThreadLocal内部封装了ThreadLocalMap结构来为线程提供存储数据的私有域空间,而Thread类提供了成员变量threadLocals来ThreadLocalMap,这样ThreadLocal、TreadLocalMap、Thread就紧密联系起来了。ThreadLocal对外提供了get、set、remove等方法来供我们操作Thread的私有域空间ThreadLocalMap。这里我们先说个大概,后面分析源码的时候再来一一解释。
接下来直接看ThreadLocal的源码。
ThreadLocal的类结构
ThreadLocal的类是java.lang包下的一个普通类,没有任何类的继承与接口实现。
public class ThreadLocal<T> {
......
}ThreadLocal的成员变量
private final int threadLocalHashCode = nextHashCode();
private static AtomicInteger nextHashCode = new AtomicInteger();
private static final int HASH_INCREMENT = 0x61c88647;ThreadLocal的构造方法
public ThreadLocal() {} ThreadLocal的内部类
ThreadLocalMap:
我们第一眼就看到ThreadLocalMap中又有一个内部类Entry,好,我们一个一个看。
Entry:
Entry就是ThreadLocalMap中实际存放数据的单个节点,为了便于理解,我们可以参照HashMap中的Node节点。Entry组成的数组就是ThreadLocalMap的底层封装数据的数据结构。
Entry继承于WeakReference(弱引用),对于弱引用,我们先做个大概的了解。
如果一个对象仅被WeakReference指向,而没有其他任何强引用指向的话,在下一次GC的时候,弱引用指向的对象就会被回收。
//ThreadLocalMap的map中定义内部类Entry,Entry就是具体存储数据的结构
//Entry继承了弱引用
//Entry的key是啥?是ThreadLocal的弱引用
static class Entry extends WeakReference<ThreadLocal<?>> {
//存放的数据
Object value;
//Entry的构造方法
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}Entry中有两个成员变量,一个是Ojbect类型的value,还有一个是继承于WeakReference的类型为ThreadLocal的reference。我们可以把reference看做是key。
接着继续看ThreadLocalMap中的成员变量和构造方法。
static class ThreadLocalMap {
//节点数组的初始化容量值
private static final int INITIAL_CAPACITY = 16;
//Entry节点数组,存放数据的数组
private Entry[] table;
//Entry数组中实际存储数据的数目,初始为0
private int size = 0;
//Entry数组扩容的阈值
private int threshold;
//ThreadLocalMap的构造方法
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
//初始化Entry数组,容量为默认的初始值16
table = new Entry[INITIAL_CAPACITY];
//threadLocalHashCode = nextHashCode(),
//INITIAL_CAPACITY为16,所以(INITIAL_CAPACITY - 1)的二进制形式为1111,
//与(INITIAL_CAPACITY - 1)进行位与运算就是相当于threadLocalHashCode对16取模
//这是因为Entry数组是一个长度为16的数组圆环,而key的落脚点即是在这个HashCode对16取模的值
//i就是当前这个key在Entry环形数组的索引值
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
//将ThreadLocal和value值构建成一个Entry,放置在ENtry数组中,
table[i] = new Entry(firstKey, firstValue);
//因为是构造方法,这里肯定是第一次存入数据,所以size为1
size = 1;
//设置entry数组的阈值,阈值为当前Entry数组长度的三分之二
setThreshold(INITIAL_CAPACITY);
}
//这个方法是ThreadLocal的方法
private static int nextHashCode() {
//nextHashCode为AtomicInteger类型
//AtomicInteger的getAndAdd()方法就是以用Unsafe的设置方式去更新这个AtomicInteger
//更新为当前值+HASH_INCREMENT
return nextHashCode.getAndAdd(HASH_INCREMENT);
}
//这个方法是AtomicInteger的方法
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
//var5即为当前这个AtomicInteger的值
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
//将AtomicInteger的当前值var5更新为var5+var4,而war4即为增量
return var5;
}
//这个方法是Entry本身的方法
private void setThreshold(int len) {
//阈值为当前entry数组长度的三分之二
threshold = len * 2 / 3;
}
//ThreadLocalMap的构造方法,参数为一个ThreadLocalMap
private ThreadLocalMap(ThreadLocalMap parentMap) {
//获取参数ThreadLocalMap中的Entry数组
Entry[] parentTable = parentMap.table;
//获取参数Entry数组的长度
int len = parentTable.length;
//设置阈值为数组长度的三分之二
setThreshold(len);
//创建一个新的数组,将数组赋值给当前Entry数组table
table = new Entry[len];
//循环遍历
for (int j = 0; j < len; j++) {
//获取参数entry数组的每个entry节点
Entry e = parentTable[j];
if (e != null) {
@SuppressWarnings("unchecked")
//e.get()返回引用referent,这个referent即为ThreadLocal
ThreadLocal<Object> key = (ThreadLocal<Object>) e.get();
if (key != null) {
//获取value
Object value = key.childValue(e.value);
//对key和value做完基本校验后,组建新的Entry节点
Entry c = new Entry(key, value);
//计算下角标位置
int h = key.threadLocalHashCode & (len - 1);
while (table[h] != null)
//如果该下角标位置已经有元素了,计算下个索引位置
h = nextIndex(h, len);
//直到计算出的索引位置上没有元素时,将新建的entry放到该索引位置
table[h] = c;
//entry数组的元素数量加一
size++;
}
}
}
}
//当前下角标i的下一个索引位置,如果达到entry数组的长度16的话,重新从0开始
private static int nextIndex(int i, int len) {
return ((i + 1 < len) ? i + 1 : 0);
}
}ThreadLocalMap中维护了一个初始容量为16的entry数组。这个entry数组就是存储数据的底层结构,还有一个阈值,看过HashMap底层源码的就不会对这个概念陌生,另外其实还有一个负载因子,不过这个负载因子并没有声明成员变量,而是在代码中直接使用的,这个负载因子为三分之二,我们可以看下setThreshold()这个方法,threshold = len * 2 / 3。
继续往下看,有两个方法比较重要的,是咱们理解ThreadLocalMap数据结构的重要切入点。
//根据当前索引位置和数组长度获取下一个索引值
private static int nextIndex(int i, int len) {
return ((i + 1 < len) ? i + 1 : 0);
}
//根据当前索引位置和数组长度获取上一个索引值
private static int prevIndex(int i, int len) {
return ((i - 1 >= 0) ? i - 1 : len - 1);
}我们看nextIndex()方法,当当前索引值加1,如果小于数组长度i+1,否则返回0。就是说如果当前索引值加一等于数组的长度就返回0。我们想到了啥?圆钟,23点再加一个小时等于24点,24就为一天的中时数,而24点也是零点,起点。我们会想到Entry数组是一个环形状。再看nextIndex()方法,当前索引值减1后如果小于0,返回数组的长度减1,即15,就是i等于0的时候,i减一不是等于负一,而是十五,这个时候我们可以确认entry数组就是一个环形结构。使用线性探测法来解决散列冲突的。
下图即为Entry数组的结构图
图片来源于:https://www.cnblogs.com/micrari/p/6790229.html
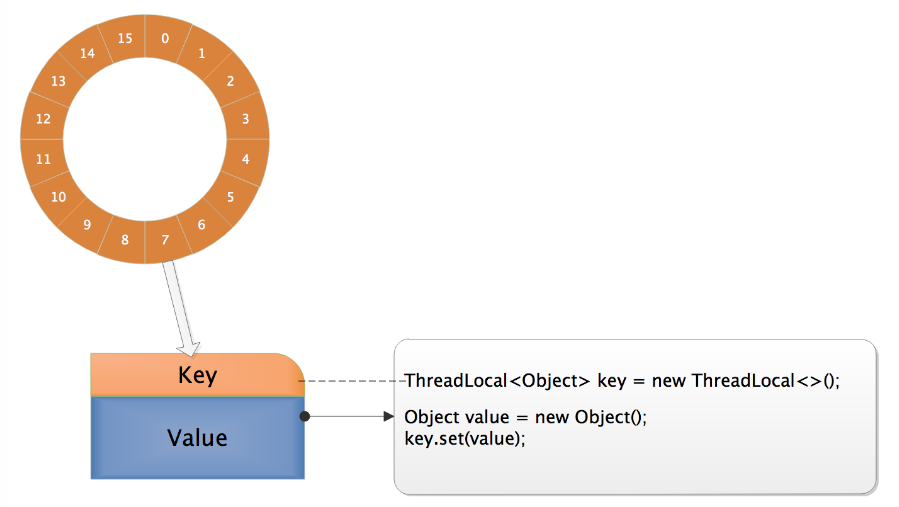
Entry数组上每个节点为一个Entry,每个Entry由一个指向ThreadLocal的的弱引用为key,value即为我们设置的变量值。
这里再想下怎么通过Key(ThreadLocal)来计算索引值?
这个计算索引值不是通过类似key.hashCode()这种方式来计算的,而是根据类型为AtomicInteger的nextHashCode成员变量和增量值HASH_INCREMENT成员变量来计算的,计算方式就是通过nextHashCode加上HASH_INCREMENT值的和与Entry数组长度的位与运算来计算的。如代码所示。
int i = key.threadLocalHashCode & (table.length - 1);
private final int threadLocalHashCode = nextHashCode();
private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}理解了Entry数组的数据结构,我们继续看ThreadLocalMap提供的主要方法。
获取:private Entry getEntry(ThreadLocal<?> key)
//根据key值获取Entry节点
private Entry getEntry(ThreadLocal<?> key) {
//根据key值计算索引位置
int i = key.threadLocalHashCode & (table.length - 1);
//获取entry数组中该索引位置的Entry节点
Entry e = table[i];
if (e != null && e.get() == key)
//如果e不为null并且e的Reference(ThreadLocal)与key相同,直接返回e节点
return e;
else
//如果根据计算出的索引值没有找到Entry节点
return getEntryAfterMiss(key, i, e);
}
private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) {
Entry[] tab = table;
int len = tab.length;
while (e != null) {
//如果e不为null
//获取entry的key,即ThreadLocal
ThreadLocal<?> k = e.get();
if (k == key)
//如果和key相等直接返回该元素
return e;
if (k == null)
//如果k为null,清理无效的entry,或者说清理ThreadLocal已经被回收的entry
expungeStaleEntry(i);
else
i = nextIndex(i, len);
e = tab[i];
}
//如果e为null,就直接返回null了
return null;
}
//该方法主要做了两件事
//第一将索引为staleSlot的节点entry的value置为null,并且将entry置为null,有利于垃圾回收
//第二从索引stateSlot的下一个索引处开始遍历判断每个entry的ThreadLocal是否为null,如果为null,将
//该entry的value和entry本身置为null,如果不为null,进行rehash重新计算索引值,判断重新计算出来的
//索引值和当前循环的索引值是否相等,如果相等,进入下一个循环,如果不等,在环形索引中寻找为节点为空的
//下角标,将e节点放置在这个索引位置
private int expungeStaleEntry(int staleSlot) {
//获取ThreadLocalMap的entry数组和数组的长度
Entry[] tab = table;
int len = tab.length;
//因为在getEntryAfterMiss方法中已经判定k==null了
//既然key为null,所以显示将key对应的value置为null
tab[staleSlot].value = null;
//显示将这个节点entry也置为null,置为null有助于垃圾回收
tab[staleSlot] = null;
//entry数组的元素个数减一
size--;
//执行Rehash直到再次遇到null值
Entry e;
int i;
//循环遍历,i的初始值为当前下角标stateSlot的下一个索引位置
for (i = nextIndex(staleSlot, len);
//将entry数组中下角标为当前遍历的角标i的节点赋值给e
(e = tab[i]) != null;
//每循环完一次去获取下一个索引位置赋值给i
i = nextIndex(i, len)) {
//获取当前遍历的entry的key值,即ThreadLocal
ThreadLocal<?> k = e.get();
if (k == null) {
//如果key(threadLocal)为null,即把key对应的value和当前这个节点都置为null
//有助于垃圾回收
e.value = null;
tab[i] = null;
size--;
} else {
//如果key不为null
//计算索引值
int h = k.threadLocalHashCode & (len - 1);
if (h != i) {
//如果新计算的索引值跟现在遍历的索引值不相等
//将当前遍历的索引值对应的节点置为null
tab[i] = null;
// Unlike Knuth 6.4 Algorithm R, we must scan until
// null because multiple entries could have been stale.
//在环形索引中寻找为节点为空的下角标,将e节点放置在这个索引位置
while (tab[h] != null)
h = nextIndex(h, len);
tab[h] = e;
}
}
}
return i;
}ThreadLocalMap通过key(ThreadLocal)来获取Entry节点,首先通过key来计算索引值,再通过索引值获取到某个Entry。如果Entry的key与参数key相同,则直接返回这个Entry节点;如果Entry为null,则直接返回null;如果Entry不为null,但是key不相同,就走getEntryAfterMiss()这个方法。这个方法里面主要是判断entry的key(ThreadLocal)。如果key既不相等也不为null,循环遍历下个索引值对应的entry。但是如果key为null,这个时候会走expungeStaleEntry()方法了,这个方法比较重要,我们单独来说说。
首先我们想象key为null代表着什么?key为threadLocal,即threadLocal为null,而threadLocal为弱引用指向的,其实这里表示为ThreadLocal被回收了,虽然ThreadLocal被回收了,但是key对应的value是跟Thread挂钩的,value可能还没被回收,所以这里我们需要显示的将value和entry置为null,以便于垃圾回收这些对象,同时防止内存泄露。不仅如此代码中还会开始遍历该entry索引后面的整个Entry数组,如果那个entry的key为null,都会显示将object和entry置为null,让其被回收,防止内存泄露。
设置值:private void set(ThreadLocal<?> key , Object value)
private void set(ThreadLocal<?> key, Object value) {
//获取entry数组和数组的长度
Entry[] tab = table;
int len = tab.length;
//计算key值对应的索引位置
int i = key.threadLocalHashCode & (len-1);
//根据计算的索引值获取对应的Entry,从该索引处开始循环向后遍历
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
//根据Entry获取ThreadLocal
ThreadLocal<?> k = e.get();
if (k == key) {
//如果key与当前entry的key相同
//直接用参数value覆盖entry中的原value
e.value = value;
return;
}
if (k == null) {
//如果k为null
//替换无效的entry
replaceStaleEntry(key, value, i);
return;
}
}
//创建一个新的Entry节点
tab[i] = new Entry(key, value);
int sz = ++size;
if (!cleanSomeSlots(i, sz) && sz >= threshold)
//如果元素个数大于或者等于阈值,扩容
rehash();
}
private void replaceStaleEntry(ThreadLocal<?> key, Object value,int staleSlot) {
Entry[] tab = table;
int len = tab.length;
Entry e;
int slotToExpunge = staleSlot;
//向索引staleSlot的前面开始循环遍历,直到tab[i]不为null
//向前遍历找到最近的一个ThreadLocal为null的entry
for (int i = prevIndex(staleSlot, len);
(e = tab[i]) != null;
i = prevIndex(i, len))
if (e.get() == null)
//如果entry的key(ThreadLocal)为null
//获取entry的索引值
slotToExpunge = i;
//向staleSlot的后面遍历
for (int i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
if (k == key) {
//如果entry的key等于参数key
//直接覆盖entry的value值
e.value = value;
//??
tab[i] = tab[staleSlot];
tab[staleSlot] = e;
if (slotToExpunge == staleSlot)
slotToExpunge = i;
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
return;
}
if (k == null && slotToExpunge == staleSlot)
slotToExpunge = i;
}
// If key not found, put new entry in stale slot
tab[staleSlot].value = null;
tab[staleSlot] = new Entry(key, value);
// If there are any other stale entries in run, expunge them
if (slotToExpunge != staleSlot)
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
}
private boolean cleanSomeSlots(int i, int n) {
boolean removed = false;
Entry[] tab = table;
int len = tab.length;
do {
i = nextIndex(i, len);
Entry e = tab[i];
if (e != null && e.get() == null) {
n = len;
removed = true;
i = expungeStaleEntry(i);
}
} while ( (n >>>= 1) != 0);
return removed;
}
private void rehash() {
expungeStaleEntries();
// Use lower threshold for doubling to avoid hysteresis
if (size >= threshold - threshold / 4)
resize();
}
private void resize() {
Entry[] oldTab = table;
int oldLen = oldTab.length;
int newLen = oldLen * 2;
Entry[] newTab = new Entry[newLen];
int count = 0;
for (int j = 0; j < oldLen; ++j) {
Entry e = oldTab[j];
if (e != null) {
ThreadLocal<?> k = e.get();
if (k == null) {
e.value = null; // Help the GC
} else {
int h = k.threadLocalHashCode & (newLen - 1);
while (newTab[h] != null)
h = nextIndex(h, newLen);
newTab[h] = e;
count++;
}
}
}
setThreshold(newLen);
size = count;
table = newTab;
}终于看完ThreadLocalMap了,我们可以接着看ThreadLocal的代码了!。
protected T initialValue() {
return null;
}
设置,void set(T value);
public void set(T value) {
//获取当前线程
Thread t = Thread.currentThread();
//获取当前线程的TreadLocalMap
ThreadLocalMap map = getMap(t);
if (map != null)
//如果ThreadLocalMap不为null,直接调用ThreadLocalMap的set方法
map.set(this, value);
else
//如果ThreadLocalMap为,以当前线程和value值创建ThreadLocalMap
createMap(t, value);
}
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
void createMap(Thread t, T firstValue) {
//创建ThreadLocalMap并用当前线程指向该map
t.threadLocals = new ThreadLocalMap(this, firstValue);
}从set()方法可以看出每个线程(Thread)有一个threadLocals变量,如代码所示:
//Thread类的成员变量
ThreadLocal.ThreadLocalMap threadLocals = null;ThreadLocal在设置值的时候,会先判断当前线程有没有初始化ThreadLocalMap,如果没有,先根据当前thredLocal(key)和value值生成ThreadLocalMap,并用该线程的成员变量threadLocals指向这个ThreadLocalMap;如果当前线程已经关联ThreadLocalMap了,则直接通过ThreadLocalMap的set方法设置值。
获取:T get();
public T get() {
//获取当前线程
Thread t = Thread.currentThread();
//获取当前线程关联的ThreadLocalMap
ThreadLocalMap map = getMap(t);
if (map != null) {
//如果ThreadLocalMap不为null,根据key(ThreadLocal)值获取entry
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
//获取entry的value值返回
return result;
}
}
//否则初始化当前线程的ThreadLocalMap,value为null
return setInitialValue();
}
private T setInitialValue() {
//value为空
T value = initialValue();
//获取当前线程
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
return value;
}
protected T initialValue() {
return null;
}到此,ThreadLocal的主要代码就介绍完了。
ThreadLocal是否存在内存泄露问题?
会,我们先来看下ThreadLocal的引用和数据结构图,图片来源于:http://www.importnew.com/22039.html,map指的ThreadLocalMap,实线代表强引用,虚线代表弱引用。
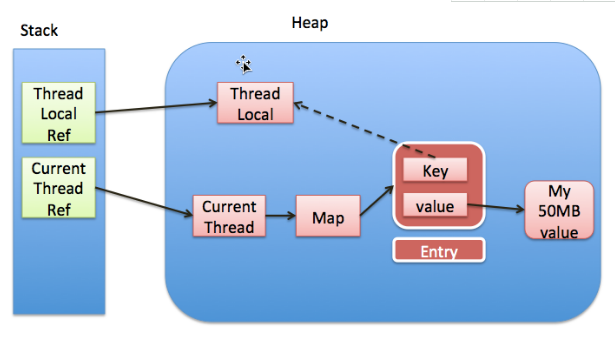
我们看到ThreadLocal有一个强引用和一个弱引用,强引用来自高层代码中的引用,比如ThreadLocal tl = new TheadLocal(),tl这就是一个强引用,而弱应用来自于ThreadLocalMap中的Entry的key的引用。当高层代码中把threadlocal实例置为null以后,就没有任何强引用指向threadlocal实例,而只有一个弱引用去指向ThreadLocal,但是我们知道弱引用指向的对象在GC时是会被回收的,所以threadlocal将会被gc回收。这也是Entry中的key使用弱应用的原因,否则TreadLoca就算在高层代码中释放引用后,因为Entry还存在,key仍然指向ThreadLocal,所以让不会被回收,容易造成内存泄露。
当ThreadLocal被回收后,我们的value还不能回收,因为存在一条从current thread连接过来的强引用.,只要thread存在,这个引用就会一直存在,只有当thread结束以后, current thread才会被销毁,强引用才会断开, 此时Current Thread, Map, value才能全部被GC回收。
所以这里存在一个风险就是,在current Thread到销毁的这段时间内,存在由于value值过多或者过大导致的内存泄露问题,我们在想下,如果我们是使用的线程池,出现什么结果,线程用完后,直接放回线程池中,不会被销毁,那么那些value就会一直存在,这样产生内存泄露的可能性大大增加。
JDK是怎么解决这个问题的呢?
我们回过头来在看看ThreadLocalMap的set和get方法,我们发现代码里都会循环遍历Entry数组,检查entey中的key(ThreadLocal)是否为null,如果为null,会显示的将entry的value和entry本身置为null,这样以便entry和entry的value能被GC回收,防止内存泄露。
既然知道了内存泄露的前因后果,我们在使用TheadLocal时候就要特别注意这方面的问题,比如我们再用完TheadLocal后记得用remove()方法去清除数据。