1.程序的装入和链接
程序进内存的一般过程:
编译compiler:编译程序:将用户源代码编译成若干个目标模块。
链接link:链接程序:将形成的一组目标模块,及它们需要的库函数链接在一起,形成一个完整的装入模块。
装入load:由装入程序将装入模块装入内存,构造PCB,形成进程,开始运行(使用物理地址)。
逻辑地址 ====== 物理地址:
绝对装入方式(absolute loading)
逻辑地址 重定位 物理地址:
静态可重定位装入方式(relocatable loading mode)
动态运行时(重定位)装入方式(dynamic run-time loading)
① 绝对装入方式
编译程序生成的“目标代码”就是”装入模块” ,逻辑地址直接从某个地址R处增长,装入模块直接装入内存地址R处。
物理地址由谁生成?
一般由编译或汇编程序给出;
或由程序员赋予(要求程序员熟悉内存使用情况)
优点:装入过程简单。不需任何地址变换,程序中的逻辑地址与实际内存物理地址完全相同。
缺点:过于依赖硬件结构, 只适用早期针对硬件直接编程、单道环境下。
静态可重定位装入方式
地址映射在程序执行之前进行,重定位后物理地址不再改变。
可由专门设计的重定位装配程序完成(软):装入时根据所定位的内存地址去修改每个逻辑地址,添加相应偏移量,重定位为物理地址。
优点:不需硬件支持,可以装入有限的多道程序
缺点:软件装入一次完成,一个程序通常需要占用连续的内存空间,程序装入内存后不能移动。也不易实现共享。
动态运行时(重定位)装入方式(dynamic run-time loading)
实际运行中往往会需要程序在内存中的各位置移动,即经常需要重定位到不同的物理地址上。这种运行时移动程序要求地址变换要快速,实现时一般依靠硬件地址变换机构——一个重定位寄存器。
程序装入内存时,可多次重定位到不同位置。且可以不立即把装入模块中的相对地址转换为绝对地址,而是把这种地址转换推迟到程序真正要执行时才进行。
更适用于部分装入
② 装入时动态链接
由一个目标模块开始装入,若又涉及外部模块调用事件,装入程序再找出相应的外部目标模块,并将它装入内存,还要修改目标模块中的相对地址。
比静态链接好在哪里?
(1) 静态链接好的程序,修改部分模块后,需重新链接成可装入程序。动态方式则便于修改和更新。
(2) 便于实现共享。静态的N个程序都需要一个模块时,需要进行N次拷贝。
③ 运行时动态链接:
装入时动态链接的问题
许多情况下,事先不知道某应用程序本次运行需要哪些模块,只能全部装入,装入时全部链接在一起,效率低。
办法:有的模块不经常使用就暂时不装入,运行时用到了再装入。(如程序总不出错,就不会用到错误处理模块。)即运行时动态链接:运行时,将对某些模块的链接推迟到执行时才链接装入。
优点:程序运行装入的内容少了,加快了装入过程,而且节省大量的内存空间。
2.连续分配方式
(1)单一连续分配方式
内存分为系统区和用户区两部分:
系统区:仅提供给OS使用,通常放在内存低址部分
用户区:除系统区以外的全部内存空间,提供给用户使用。
最简单的一种存储管理方式,只能用于单用户、单任务的操作系统中。
优点:易于管理。
缺点:对要求内存空间少的程序,造成内存浪费;程序全部装入,很少使用的程序部分也占用内存。
(2)固定分区分配
把内存分为一些大小相等或不等的分区(partition),每个应用进程占用一个分区。操作系统占用其中一个分区。
提高:支持多个程序并发执行,适用于多道程序系统和分时系统。最早的多道程序存储管理方式。
划分为几个分区,便只允许几道作业并发
(3)动态分区分配
分区的大小不固定:在装入程序时根据进程实际需要,动态分配内存空间,即——需要多少划分多少。
空闲分区表项:从1项到n项:
内存会从初始的一个大分区不断被划分、回收从而形成内存中的多个分区。
动态分区分配
优点:并发进程数没有固定数的限制,不产生内碎片。
缺点:有外碎片(分区间无法利用的空间)
(1)数据结构
空闲分区表:
记录每个空闲分区的情况。
每个空闲分区对应一个表目,包括分区序号、分区始址及分区的大小等数据项。
空闲分区链:
每个分区的起始部分,设置用于控制分区分配的信息,及用于链接各分区的前向指针;
分区尾部则设置一后向指针,在分区末尾重复设置状态位和分区大小表目方便检索。
(2)分区算法
动态分区方式,分区多、大小差异各不相同,此时把一个新作业装入内存,更需选择一个合适的分配算法,从空闲分区表/链中选出一合适分区
首次适应算法FF
循环首次适应算法
最佳适应算法
最差适应算法
快速适应算法
(3)分区分配操作
分配内存
找到满足需要的合适分区,划出进程需要的空间
if s<=size,将整个分区分配给请求者
if s> size,按请求的大小划出一块内存空间分配出去,余下部分留在空闲链中,将分配区首址返回给调用者。
回收内存
进程运行完毕释放内存时,系统根据回收区首址a,在空闲分区链(表)中找到相应插入点,根据情况修改空闲分区信息,可能会进行空闲分区的合并:
(4)动态重定位分区分配
用户程序在内存中移动,将空闲空间紧凑起来提高空间利用率。但必然需要地址变化,增加“重定位”工作。
(5)内存空间管理之对换
当内存空间还是满足不了需求时,引入“对换”思想:
把内存中暂时不能运行、或暂时不用的程序和数据调到外存上,以腾出足够的内存;把已具备运行条件的进程和进程所需要的程序和数据,调入内存。
按对换单位分类:
整体对换(或进程对换):以整个进程为单位(连续分配)
页面对换或分段对换:以页或段为单位(离散分配)
3.内存离散分配分页分段
连续分配方式:一个进程连续的装进内存一个大小合适的区。
“碎片” “紧凑” 增大开销
如果允许一个进程直接分散装入多个不相邻分区中,则无需“紧凑”
产生存储管理的离散分配方式。
基本分页储存管理方式
本部分讨论不具备对换功能的纯分页模式,作业运行需要全部装入内存。
比较连续分配方式
作业逻辑地址空间有M大,就需要向内存申请一个M大的连续区域。
分页的目的是更细粒度的处理空间,减少粗放管理的浪费或开销问题。
1)页面的概念
内存划分成多个小单元,每个单元K大小,称(物理)块。作业也按K单位大小划分成片,称为页面。
2)页表的概念
为了找到被离散分配到内存中的作业,记录每个作业各页映射到哪个物理块,形成的页面映射表,简称页表。
每个作业有自己的页表
页表的作用:
页号到物理块号的地址映射
要找到作业A
关键是找到页表(PCB)
根据页表找物理块
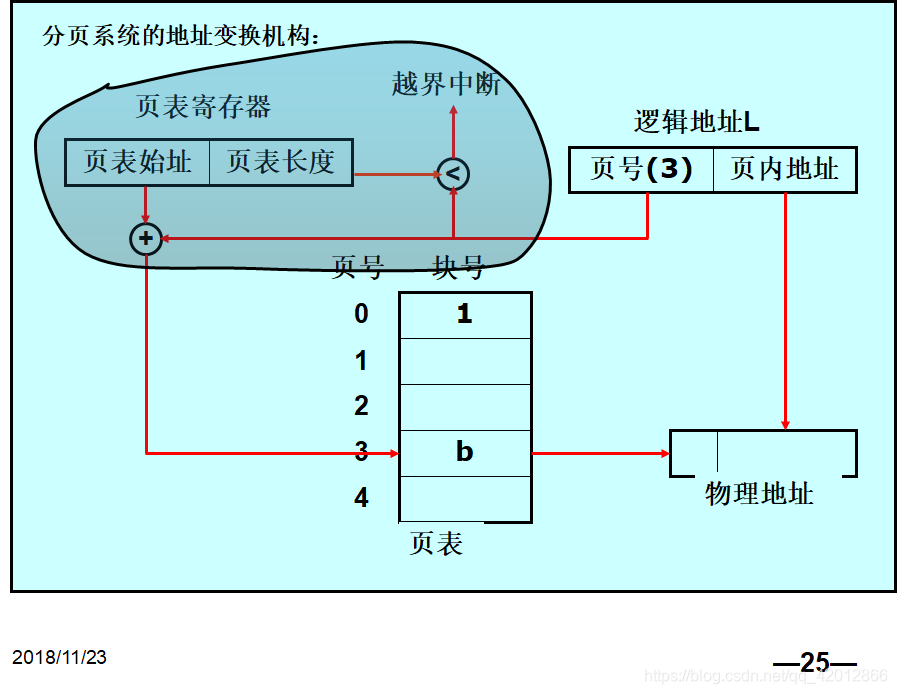
3)地址的处理
连续方式下,每条指令用基地址+偏移量即可找到其物理存放的地址。
分页方式下详细的地址处理会如何呢?
作业相对地址在分页下不同位置的数有一定的意义结构:
页号+页内地址(即页内偏移)
关键的计算是:根据系统页面大小找到不同意义二进制位的分界线。
从地址中分析出页号后,地址映射只需要把页号改为对应物理块号,偏移不变,即可找到内存中实际位置。
4)地址变换机构
访问内存时间
设访问一次内存时间为t,则基本分页机制下EAT=2t
5)快表
问题:基本分页机制下,一次指令需两次内存访问,处理机速度降低1/2,分页空间效率的提高以如此的速度为代价,得不偿失。
改进:减少第1步访问内存的时间。增设一个具有“并行查询”能力的高速缓冲寄存器,称为“快表”,也称“联想寄存器”(Associative memory),IBM系统称为TLB(Translation Look aside Buffer)。
快表放什么?:
正在执行进程的页表的数据项。
引入快表后的内存访问时间如何?
快表的寄存器单元数量是有限的,不能装下一个进程的所有页表项。虽不能完全避免两次访问内存,但如果命中率a高还是能大幅度提高速度。
设一次查找访问快表时间为t’ ,则
EAT= at’ + (1-a)(t’+t) + t
= 2t +t’ -ta
6)两级多级页表
页表大小的讨论
进程分页离散存放,但页表的数据是连续在存放内存的。而页表可能很大:
将页表分页,并离散地将页表的各个页面分别存放在不同的物理块中
为离散分配的页表再建立一张页表,称为“外层页表”,其每个表项记录了页表页面所在的物理块号。
多级页表
反置页表
每个进程一张页表
一张OS 反置页表 + 每进程一张外部页表
反置页表(Inverted Page Tale):站在物理块的角度,记录占用它的已调入内存的进程标识和页号。系统中只需一张该表即可。一个64MB内存,若页面大小4KB(64M/4K=2^16=16K个物理块),反置页表占用64KB(16K*4B)
进程外部页表(External Page Table):每个进程一张,记录进程不在内存中的那些页面所在的外存物理位置。
如何提高检索反置页表速度:内存容量大时,反置页表的页表项还是会很大,利用进程标识符和页号去检索一张大的线性表很费时,可利用hash算法提高检索速度。
4.基本分段储存方式
从提高内存利用率角度;
固定分区 动态分区 分页
从满足并方便用户(程序员)和使用上的要求角度:
分段存储管理:作业分成若干段,各段可离散放入内存,段内仍连续存放。
方便编程:如汇编中通过段:偏移确定数据位置
信息共享:同地位的数据放在一块方便进行共享设置
信息保护
动态增长:动态增长的数据段事先固定内存不方便
动态链接:往往也是以逻辑的段为单位更方便
分段系统的基本原理
程序通过分段(segmentation)划分为多个模块,每个段定义一组逻辑信息。如代码段(主程序段main,子程序段X)、数据段D、栈段S等。
谁决定一个程序分几段,每段多大?
编译程序(基于源代码)
段的特点
每段有自己的名字(一般用段号做名),都从0编址,可分别编写和编译。装入内存时,每段赋予各段一个段号。
每段占据一块连续的内存。(即有离散的分段,又有连续的内存使用)
各段大小不等。
3)分页和分段的基本区别
需求:分页是出于系统管理的需要,是一种信息的物理划分单位,分段是出于用户应用的需要,是一种逻辑单位,通常包含一组意义相对完整的信息。
一条指令或一个操作数可能会跨越两个页的分界处,而不会跨越两个段的分界处。
大小:页大小是系统固定的,而段大小则通常不固定。分段没有内碎片,但连续存放段产生外碎片,可以通过内存紧缩来消除。相对而言分页空间利用率高。
逻辑地址:
分页是一维的,各个模块在链接时必须组织成同一个地址空间;
分段是二维的,各个模块在链接时可以每个段组织成一个地址空间。
其他:通常段比页大,因而段表比页表短,可以缩短查找时间,提高访问速度。分段模式下,还可针对不同类型采取不同的保护;按段为单位来进行共享
4)信息共享
需求:分页是出于系统管理的需要,是一种信息的物理划分单位,分段是出于用户应用的需要,是一种逻辑单位,通常包含一组意义相对完整的信息。
一条指令或一个操作数可能会跨越两个页的分界处,而不会跨越两个段的分界处。
大小:页大小是系统固定的,而段大小则通常不固定。分段没有内碎片,但连续存放段产生外碎片,可以通过内存紧缩来消除。相对而言分页空间利用率高。
逻辑地址:
分页是一维的,各个模块在链接时必须组织成同一个地址空间;
分段是二维的,各个模块在链接时可以每个段组织成一个地址空间。
其他:通常段比页大,因而段表比页表短,可以缩短查找时间,提高访问速度。分段模式下,还可针对不同类型采取不同的保护;按段为单位来进行共享
5)段页式储存方式
① 基本原理
将用户程序分成若干段,并为每个段赋予一个段名。
把每个段分成若干页
地址结构包括段号、段内页号和页内地址三部分