HTTP协议:
HTTP是超文本传输协议的简称,他是TCP/IP协议的一个应用层协议,用于定义web浏览器与web服务器之间交互数据的过程。客户端连上web服务器后,若想获得web服务器中的某个web资源,须遵循一定的通讯格式,HTTP用于定义客户端与web服务器之间的通讯格式。
IP
ip作用:用于标识网络上某一台设备,网络上不同设备要进行通信,IP地址不同
端口
端口作用:是操作系统分配给网络应用程序的编号,当接收到数据后,操作系统会根据编号来讲数据转发到对应编号的应用程序的,用于系统区分网络程序
端口号:就是标识端口的一个编号
知名端口:80端口分配给 HTTP服务
22端口分配给SSH服务
21端口分配给FTP服务
UDP
定义:用户数据报协议,他是无连接、不可靠的网络传输协议
UDP优缺点:
优点:
1、传输速度快
2、不需要链接,资源开销小
3、由于通讯不需要链接,可以发送广播
缺点:
1、传输数据不可靠,容易丢失数据包
2、没用流量控制,当对方没有及时接收数据,发送方一直发送数据会导致缓冲区数据满了,电脑出现卡死情况,所有接受方需要及时接受数据
socket
定义:socket(套接字)是进程间通讯的一个工具,能实现把数据从一方传输到另外一方,完成不同电脑上进程之间的通信,好比数据的搬运工。
数据编码
str ==> bytes : encode 编码
bytes ==> str : decode 解码
字符串转字节串编码
字节串转字符串解码
- 其中decode()与encode()方法可以接受参数,其声明分别为:
bytes.decode(encoding="utf-8",errors="strict")
str.encode(encoding="utf-8",errors="strict")
其中encoding是解码编码过程中的使用的编码格式,errors是指错误的处理方式
TCP
tcp是传输控制协议,他是一种面向链接的、可靠地、基于字节流的传输层通信协议,用于HTTP、HTTPS、FTP等传输文件协议,
TCP优缺点
优点
TCP在传输数据时,,有确认、窗口、重传阻塞等控制机制,能保证数据正确性、较为可靠
缺点
传输速度慢
占用系统资源高
TCP安全,因为他存在三次握手四次挥手(校验数据)
通过三次握手的模式,可以是客户端和服务器端有效的保持通畅,这样就可以进行数据传输了,数据传输完成以后,通过四次挥手的模式,通过客户端和服务器端两次验证,把数据传输结束,这样保证TCP的安全性
三次握手
(客户端先发送
链接请求,服务器端响应客户端,连接上后客户端返回链接上数据(listen是让多人请求时,能进行一个请求等待,最大128连接数)握手没有完成之前的队列)
四次挥手
(客户端发起断开链接请求,服务器端返回响应,不立马断开链接,等待一段时间后断开链接,服务器发送断开链接给客户端,客户端返回断开成功)
多任务
并发:指的是任务数多于CPU核数,通过操作系统的各种任务调度算法,实现多个任务一起执行(实际上总有一些任务不在执行,以为任务切换的速度 相当快,看上去一起执行而已)
并行:指的是任务数小于等于CPU核数,即任务真的是一起执行
线程(import threading)
def test():
print("abc")
print(test) # 这是函数的引用,打印的是内存地址
test() # 这是函数的调用,打印的是值abc
线程的理解
线程就是在程序运行过程中,执行程序代码的一个分支,每个运行的程序至少都有一个线程
线程就是执行多任务的,是函数的引用,多个函数需要同时执行时使用,一个线程就是一个任务,就是一个函数,引用函数时不要加括号,就等于开多个窗口,一个窗口卡住了,其他窗口还可以运行,
程序一创建,系统会自动给我们创建一个主线程,我们用threading可以开启一个子线程,放入的函数的引用会在子线程中执行,在开一个子线程将另一个函数的引用放入执行,线程之间互不影响,一个线程阻塞,另一个线程不受影响
#先导入threading模块
# 线程中有一个线程类,线程类中有参数,类加括号调用init方法
sing_thread = threading.Thread(target=sing)
# 开启线程
sing_thread.start()
线程操作全局变量
多个线程可以操作同一个全局变量
进程的概念
#导入线程模块
import multiprocessing
进程:通俗理解一个运行的程序或者软件,进程是操作系统资源分配的基本单位
注意:一个程序至少有一个进程,一个进程至少有一个线程,多线程可以完成多任务
程序一开启就有一个主进程,主进程内有一个主线程,代码执行都是线程在执行,线程是CPU调度的单位,进程是操作系统资源分配的单位
进程之间不共享数据,子进程会复制主进程资源,进程号加ID就是唯一的编号 队列就是进程用来存储数据的,存的数量超过限制的数量,会造成阻塞,取得时候超过数量也会造成阻塞
进程、线程、协程对比
目标
知道进程和线程关系及优缺点
1. 功能对比
进程,能够完成多任务,比如 在一台电脑上能够同时运行多个QQ
线程,能够完成多任务,比如 一个QQ中的多个聊天窗口
2. 定义对比
- 进程是系统进行资源分配基本单位,每启动一个进程操作系统都需要为其分配运行资源。
- 线程是运行程序中的一个执行分支,是CPU调度基本单位。
- 总结:进程是操作系统资源分配的基本单位,线程是CPU调度的基本单位
3. 关系对比
- 线程是依附在进程里面的,没有进程就没有线程
- 一个进程默认提供一条线程,进程可以创建多个线程
- 多进程、多线程根据cpu核数不一样可能是并行的,但是协程是在一个线程中 所以是并发
- 一个线程里面可以有多个协程
4. 区别
- 进程之间不共享全局变量
- 线程之间共享全局变量,但是要注意资源竞争的问题,解决办法: 互斥锁或者线程同步
- 创建进程的资源开销要比创建线程的资源开销要大
- 进程是操作系统资源分配的基本单位,线程是CPU调度的基本单位
- 线程不能够独立执行,必须依存在进程中
- 多进程开发比单进程多线程开发稳定性要强
进程、线程、协程都是可以完成多任务的,可以根据自己实际开发的需要选择使用
由于线程、协程需要的资源很少,所以使用线程和协程的几率最大
开辟协程需要的资源最少
优缺点
多进程:
优点:可以用多核
缺点:资源开销大
多线程:
优点:资源开销小
缺点:不能使用多核
迭代器
- 迭代:
可以用for循环遍历取值的过程
- 迭代对象:
使用for循环遍历取值的对象叫做可迭代对象, 比如:列表、元组、字典、集合、range、字符串
- 装饰器:
本质上是python函数,可以让其他函数在不需要做任何代码变动的前提下增加额外功能,装饰器的返回值也是一个函数对象
- 闭包:
在函数内部在定义一个函数,并且这个函数用到了外边函数的变量,那么将这个函数以及用到的一些变量称之为闭包
迭代器必须是可迭代对象
for value in [2, 3, 4]:
print(value)
可迭代对象
使用for循环遍历取值的对象叫做可迭代对象, 比如:列表、元组、字典、集合、range、字符串
def __iter__(self):
# 可迭代对象的本质:遍历可迭代对象的时候其实获取的是可迭代对象的迭代器, 然后通过迭代器获取对象中的数据
from collections import Iterable
my_list = MyList()
result = isinstance(my_list, Iterable)
# Iterable判断是否是可迭代对象
iter()函数与next()函数
iter函数: 获取可迭代对象的迭代器,会调用可迭代对象身上的__iter__方法
next函数: 获取迭代器中下一个值,会调用迭代器对象身上的__next__方法
自定义迭代器对象: 在类里面定义__iter__和__next__方法创建的对象就是迭代器对象
# 自定义一个类去判断当前的类是否可以被迭代
from collections import Iterable # 可迭代的对象
# 只要类实现iter,那么这个类就可以被迭代
# 只要类实现了iter 跟next这两个方法就是迭代器了
class MyIter(object):
# 初始化值
def __init__(self):
self.value = 0 # 初始化的值
# 这个返回迭代器对象
def __iter__(self):
return self # 这个以后自定义迭代器固定写法就是返回self
# 返回迭代的数据
def __next__(self):
# 手动抛出异常
# 每一次数据都 增长
self.value += 1
# 到十停止
if self.value > 10:
# 停止 迭代
raise StopIteration
return self.value
# 得到一个对象
my_iter = MyIter()
# print(isinstance(my_iter, Iterable))
# 这个类是一个可迭代的对象,但是他还不能被迭代,因为他没有返回迭代的数据
# 如果你要使用for,那么你一定要是一个迭代器对象,迭代器前提是你是可迭代的对象,但是再加一个返回数据
for temp in my_iter:
print(temp)
迭代器与列表的区别
迭代器是在里面写了一个公式,而不是将数据真正的存进来,在内存使用上比列表效率更高一点。列表是将所要数据循环遍历一遍,占用内存比较严重
for循环底层
是iter和next一步步拆分出来的
# for 循环的底层
# 生成一个一百万的数据遍历
class MyIter(object):
# 实现两个方法iter,next
# 初始化值
def __init__(self):
self.start = 0 # 初始化起始值
def __iter__(self):
return self # 返回自身
def __next__(self):
# 判断是如果到了一百万那么手动抛出停止迭代的异常
if self.start > 1000000:
# 停止迭代
raise StopIteration
self.start += 1
return self.start
my_iter = MyIter()
# for temp in my_iter:
# print(temp)
# 得到我们的迭代器对象
my_iter_object = iter(my_iter)
# iter next拆分得到for循环,是一个一个next遍历出来的
# 得到迭代的数据
print(next(my_iter_object))
print(next(my_iter_object))
print(next(my_iter_object))
生成器
生成器就是迭代器,迭代器必须是可迭代对象,生成器生成的方式不一样
生成器不需要定义类,
生成器第一种方式
# 生成器是一种特殊的迭代器,特殊在于他的生成的方式不能通过类实现iter跟next
# 列表推导式
a_list = [x for x in range(10)]
# print(a_list)
# 把列表推导式的[]改成()就是生成器了
# 了解一下
a_list = (x for x in range(10))
print(a_list)
for temp in a_list:
print(temp)
生成器第二种方式
gevent的底层就是yield,可以使两个函数之间来回切换,因为next使函数执行了一次,然后在执行另一个函数,就实现了两个函数的来回切换,但是需要有耗时任务,没有耗时任务是无法来回切换
# 使用函数生成器,把return 换成yield就是生成器了
# 只要函数中有yield那么就是生成器了
def count():
for temp in range(10):
yield temp # yield能让我们的函数暂停执行
print(count())
# 得到器对象
count_iter = iter(count())
# 迭代
print(next(count_iter))
print(next(count_iter))
print(next(count_iter))
print(next(count_iter))
print(next(count_iter))
print(next(count_iter))
闭包
# 格式
# 两个函数嵌套, 外部函数返回内部函数的引用,一般外部函数都有参数,外部参数的值会一直保留在内存中
def 外部函数(参数):
def 内部函数():
# 让函数做一些事情
print(参数)
return 内部函数
内部函数的引用 = 外部函数("传入参数")
# 执行内部的函数
内部函数的引用()
装饰器
def set_fun(func):
def call_fun(*args, **kwargs):
print("装饰一把")
return func(*args, **kwargs)
return call_fun
@set_fun
def test():
print("test")
test()
多个装饰器装饰一个函数
执行顺序是先上后下,先外后内
def set_fun1(func1):
print("set_fun1")
def call_fun1():
print("call_fun1")
func1()
return call_fun1
def set_fun2(func2):
print("set_fun2")
def call_fun2():
print("call_fun2")
func2()
return call_fun2
@set_fun2
@set_fun1
def test():
print("test")
test()
gil锁
gil全局解释器锁 ,是python解释器历史遗留问题,跟python语言没有什么关系,换一个jpython就没有这个问题了。不用线程用进程
对多线程的影响,在同一时刻只有一个线程执行,这些线程在一同个进程内
并阐明多线程抓取程序是否可比单线程性能有提升,多线程还是可以用到多核的资源,但是爬虫是一个阻塞的东西,网络的速度比CPU的速度慢很多,
任何Python线程执行前,必须先获得GIL锁,然后,每执行100条字节码,解释器就自动释放GIL锁,让别的线程有机会执行
Python虽然不能利用多线程实现多核任务,但可以通过多进程实现多核任务
拷贝与引用的区别
引用:是两个变量值,指向同一个内存地址
拷贝:是会生成一个新的内存地址
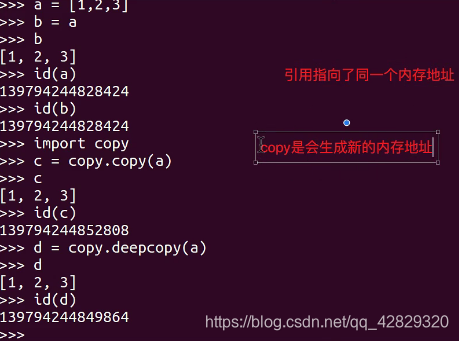
浅拷贝
拷贝了最外围的对象本身,内部的元素都只是拷贝了一个引用而已。也就是,把对象复制一遍,但是该对象中引用的其他对象我不复制
深拷贝
外围和内部元素都进行了拷贝对象本身,而不是引用。也就是,把对象复制一遍,并且该对象中引用的其他对象我也复制。
切片与深浅拷贝
1.切片可以应用于:列表、元组、字符串,但不能应用于字典。
2.深浅拷贝,既可应用序列(列表、元组、字符串),也可应用字典。
深浅拷贝的作用
1,减少内存的使用
2,以后在做数据的清洗、修改或者入库的时候,对原数据进行复制一份,以防数据修改之后,找不到原数据。
单例模式
使一个类只能创建一个对象,创建单例时只执行一次__init__方法
class Person(object):
instance = None
is_first_run = True
def __new__(cls, *args, **kwargs):
if cls.instance == None:
cls.instance = object.__new__(cls)
return cls.instance
def __init__(self, name=''):
if Person.is_first_run:
self.name = name # 只有第一次创建对象才应该赋值
Person.is_first_run = False
def set_name(self, new_name):
self.name = new_name
zs = Person('张三')
print(zs.name)
li = Person()
print(li.name)
li.set_name('李思')
print(zs.name)
flask和Django路由映射的区别
索引:
是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的位置信息。如火车站的车次表、图书的目录等
数据库优化
1、使用索引(B+树、hash)
应 尽量避免全表扫描,首先应考虑在order,group by 涉及的列上建立索引
2、优化SQL语句
通过explain(查询优化神器)用来查看SQL语句的执行效果,可以帮助写出更 好的SQL语句: (1)避免使用
select * from,用具体的字段代替*,不要返回用不到的任何字段 (2)不在索引列做运算或者使用函数
(3)尽量使用limit减少返回的行数,减少数据传输时间和带宽浪费
3、优化数据库对象
(1)使用procedure
analyse()函数对表进行分析,该函数可以对表中列的数据类型提出优化建议,使用能正确的表示和存储数据的最短类型,这样可以减少对磁盘空间。内存。CPU缓存的使用
4、使用缓存
把经常访问的且不需要经常变化的数据放在缓存中能节约磁盘的IO
5、主从复制、读写分离、负载均衡
6、分布式
函数装饰器有什么作用(常考)
装饰器本质上是一个Python函数,它可以让其他函数在不需要做任何代码变动的前提下增加额外功能,装饰器的返回值也是一个函数对象。它经常用于有切面需求的场景,比如:插入日志、性能测试、事务处理、缓存、权限校验等场景。有了装饰器,就可以抽离出大量与函数功能本身无关的雷同代码并继续重用。