2012年的ImageNet,Hinton和他的学生用了一个神奇的方法拿下了冠军。
论文在这里:https://www.nvidia.cn/content/tesla/pdf/machine-learning/imagenet-classification-with-deep-convolutional-nn.pdf
当时神经网络其实大部分还在SVM的阴影之下,这一把骚操作直接让人们的关注点又拉了过去。
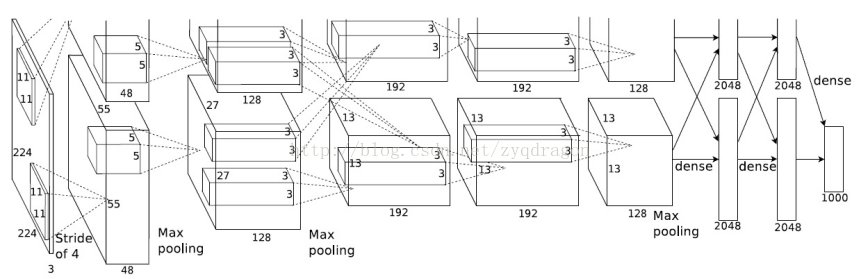
以下是AlexNet的网络拓扑结构:最左边是227 * 227 * 3的彩色图像(图中的224 * 224是因为最后除不尽就先加了padding)
DropOut
这里有一个关键的技术先说一下,就是Dropout。我们都知道要抑制过拟合,可以让损失函数加上权重的L2范数的权值衰减方法。但是如果网络模型变得复杂,权值衰减就难对付。这里我们用dropout
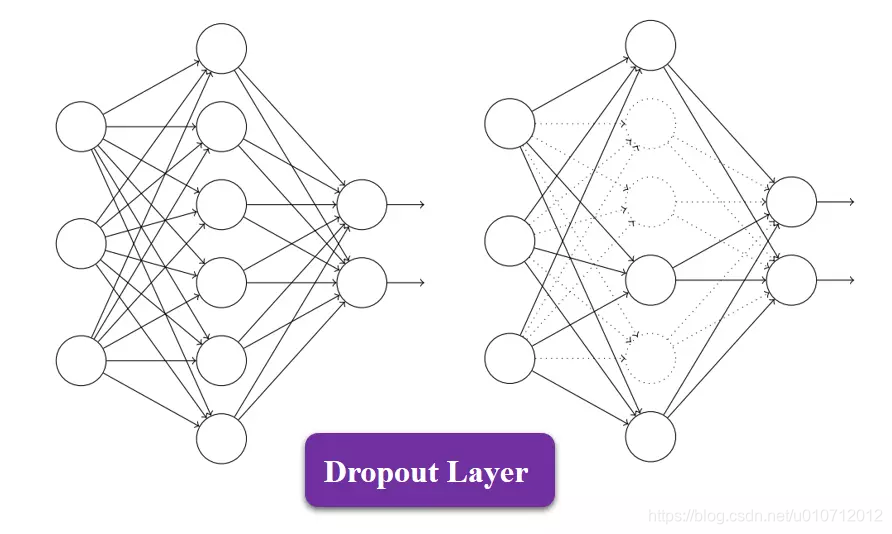
Dropout是一种在学习过程中随机删除神经元的方法。训练时,随机选出隐藏层的神经元,然后将其删除。被删除的神尽管不在进行信号的传递,如上图的虚线部分。
训练时,每传递一次数据,就会随机选择要删除的神经元。然后,测试时,虽然会传递所有的神经元信号,但是对于各个神经元的输出,要乘上训练时的删除比例后再输出。
学过机器学习的都知道集成学习,dropout在这里就很像bagging,这是因为可以将Dropout理解为,通过在学习中随机删除神经元,从而每一次都让不同的模型进行学习。也就是说,可以理解为,Dropout将集成学习的效果通过一个网络实现了。
Alexnet由八层网络组成。前五层是卷积层,中间穿插着Norm和最大池化层。如下图:
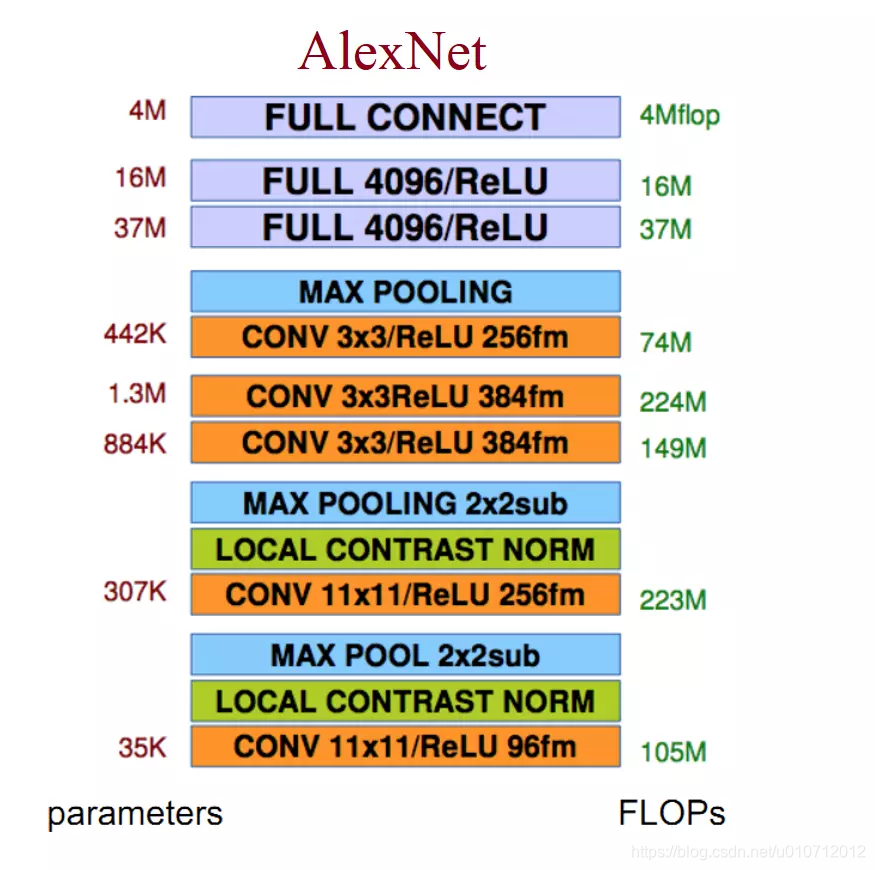
卷积层的过程就不在这里讲了,大家可以看下面的文章
https://blog.csdn.net/v_JULY_v/article/details/51812459
激活函数为什么选取relu呢?可以看看
https://blog.csdn.net/u013982164/article/details/83448504
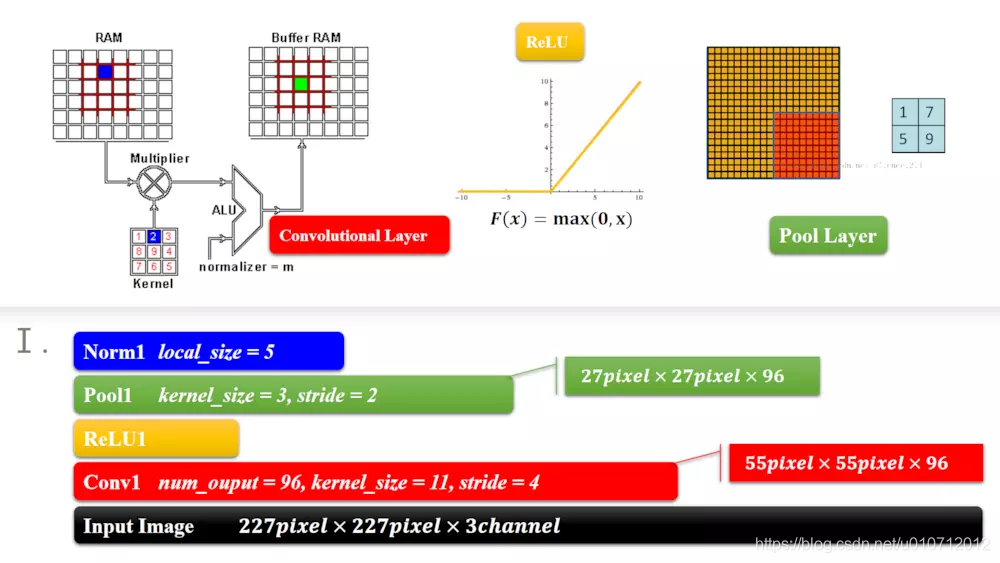
刚开始的227 * 227,卷积核是11,stride = 4,所以有(227-11)/4+1 = 55,输出96
,池化层同样的算法
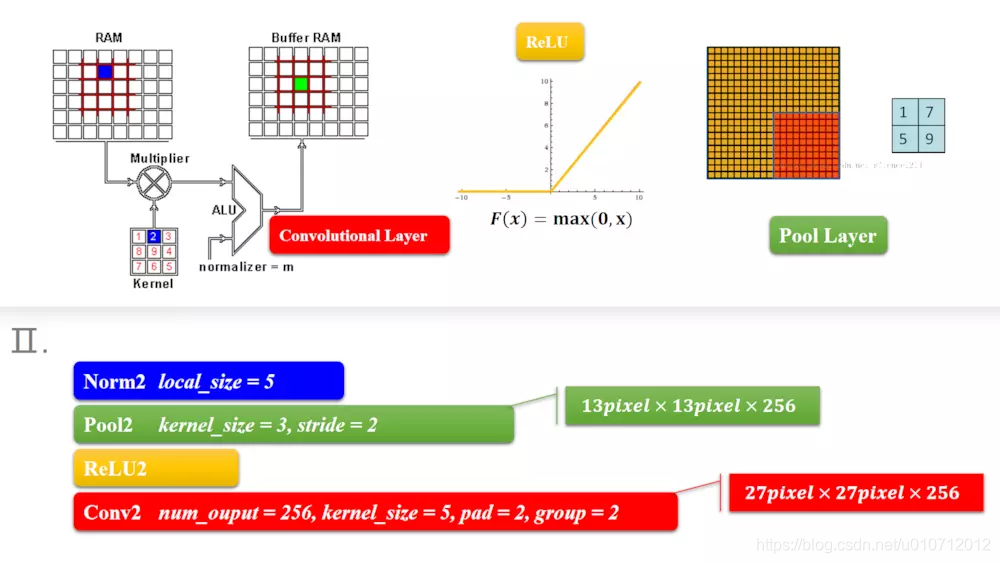
第二层的这里因为有pad=2,相当于正方形两边都加了2,也就是加了4,就变成(27-5+2 * 2)/1+1 = 27。

一样的算法,3.4层也是卷积层。
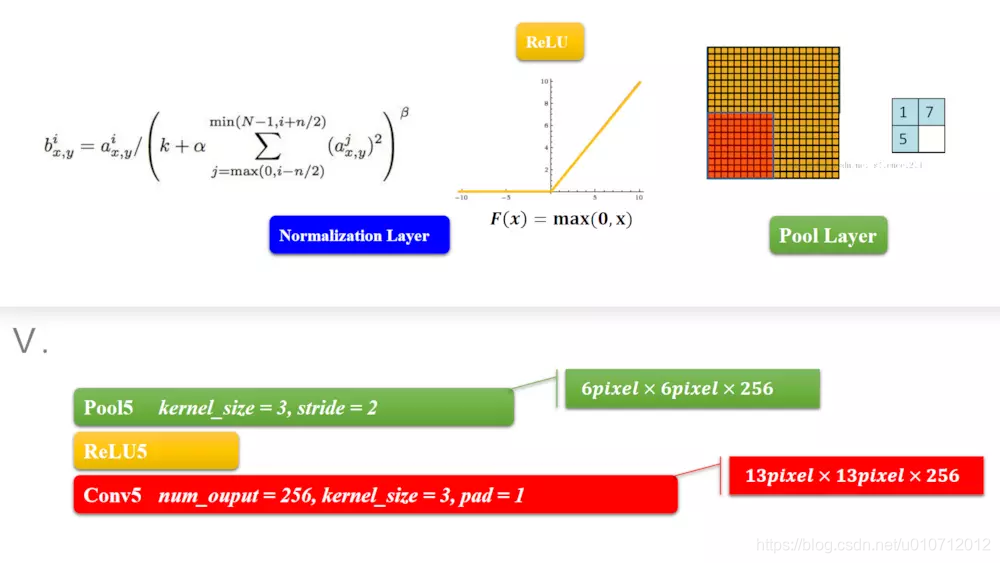
前五层都是差不多的算法。只不过卷积核数不太一样。
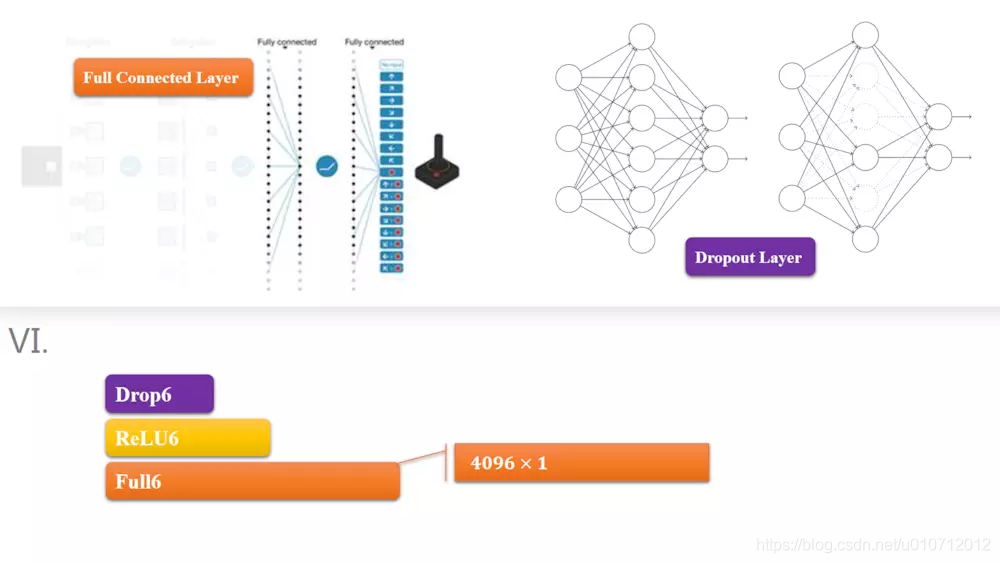
模块6,7是全连接层,第5层输出的6 * 6 * 256规模的像素层数据与第6层的4096个神经元进行全连接,然后经由relu进行处理后生成4096个数据,再经过dropout处理后输出4096个数据。
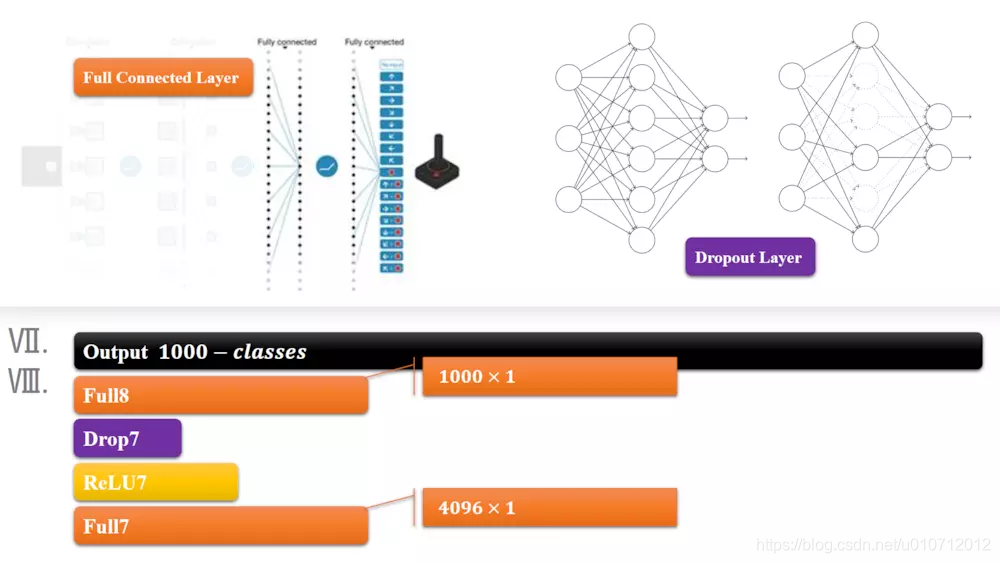
第7层输出的4096个数据与第8层的1000个神经元进行全连接,经过训练后输出被训练的数值。结合上softmax做出分类。有几类,输出几个结点,每个结点保存的是属于该类别的概率值。
参考:https://www.jianshu.com/p/58168fec534d
https://blog.csdn.net/zyqdragon/article/details/72353420
《深度学习入门》