目录
1、sbt构建spark开发环境与测试
2、spark wordcount打包与布署
详情
1、sbt构建spark开发环境
- 构建一个sbt eclipse的空项目
- 1)创建一个基础项目目录
- 2)在基础项目目录中,新建build.sbt脚本,并添加如下基础依赖。
name := "SparkWordCount4Sbt"
scalaVersion := "2.11.11"
organization := "com.tl.job003"
libraryDependencies ++= Seq(
//暂无依赖
)
- 新建6个空目录,如下列表
mkdir -p src/main/scala
mkdir -p src/main/java
mkdir -p src/main/resources
mkdir -p src/test/scala
mkdir -p src/test/java
mkdir -p src/test/resources
- 4)再执行 sbt eclipse,将生成的项目通过eclipse import导入即可,如下图所示
-
spark依赖加入与测试
-
spark lib依赖配置
- 因为只做spark wordcount基本计算,故只需要引入对应版本的spark core即可
-
-
name := "SparkWordCount4Sbt"
scalaVersion := "2.11.11"
organization := "com.tl.job003"
libraryDependencies ++= Seq(
//spark-core依赖 ,注意版本group对应通过%%实现
"org.apache.spark" %% "spark-core" % "1.6.2" % "provided",
)
- spark本地测试需要的winutils加入
-
winutils跟构建方法无关,故哪种构建方法均需要加入项目路径下的null/bin/winutils.exe可执行文件
-
之前已讲过,故不做赘述
-
scala实现spark wordcount代码编写
- 与之前的版本完全一致
-
package com.tl.job003.examples
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD.rddToPairRDDFunctions
object SparkWordCount {
def main(args: Array[String]) {
if (args.length < 1) {
System.err.println("Usage: <file>")
System.exit(1)
}
val conf = new SparkConf()
conf.setMaster("local");
conf.setAppName("TestSpark");
val sc = new SparkContext(conf)
val line = sc.textFile(args(0))
// line.flatMap(_.split("\t")).map((_, 1)).reduceByKey(_ + _).collect.foreach(println)
var log = line.flatMap(_.split("\\s+")).map((_, 1)).reduceByKey(_ + _);
// log.saveAsTextFile("ttmm");
// println("---" + line);
// log.saveAsTextFile(args(1).toString());
log.foreach(println _);
sc.stop();
}
}
- 本地运行测试
- run configuration,加入输入和输出文件的arguments参数即可
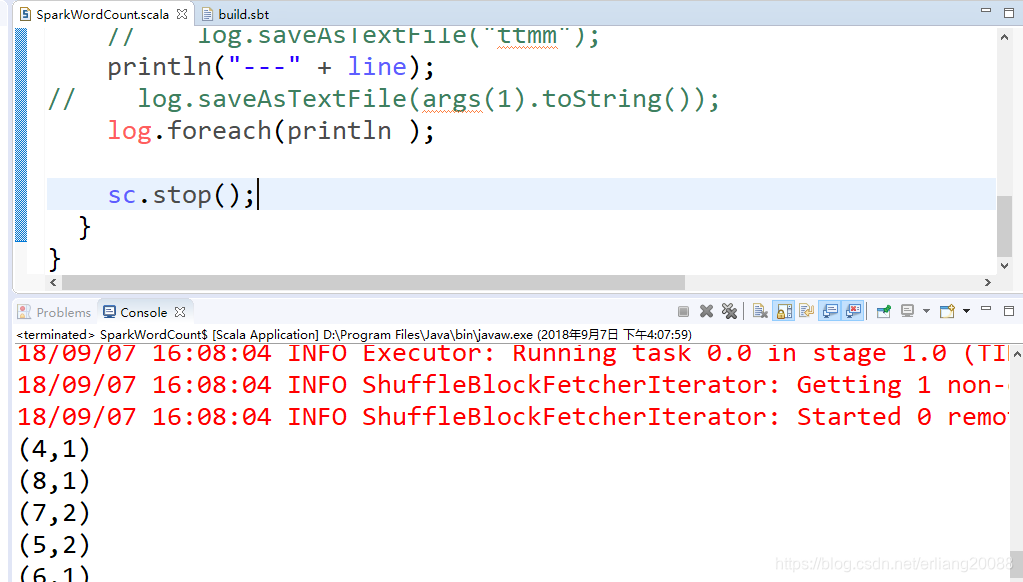
- run configuration,加入输入和输出文件的arguments参数即可
2、spark wordcount打包与布署
- assembly打包
- 本地测试运行时候,直接利用sbt run即可测试,无需打包。
- 用于远程布署与测试的打包
- 已在spark集群中的lib依赖,均加上provided参数项,防止多打lib包进入最后的assembly大jar包。
- 将scala版本环境去掉,入口机及集群中均已存在。加入如下配置项:
autoScalaLibrary := false
* 执行sbt assembly,得到最终的assembly jar包
* 因为去掉了spark-core、scala自依赖,最终jar只有几k的大小。
- jar包布署
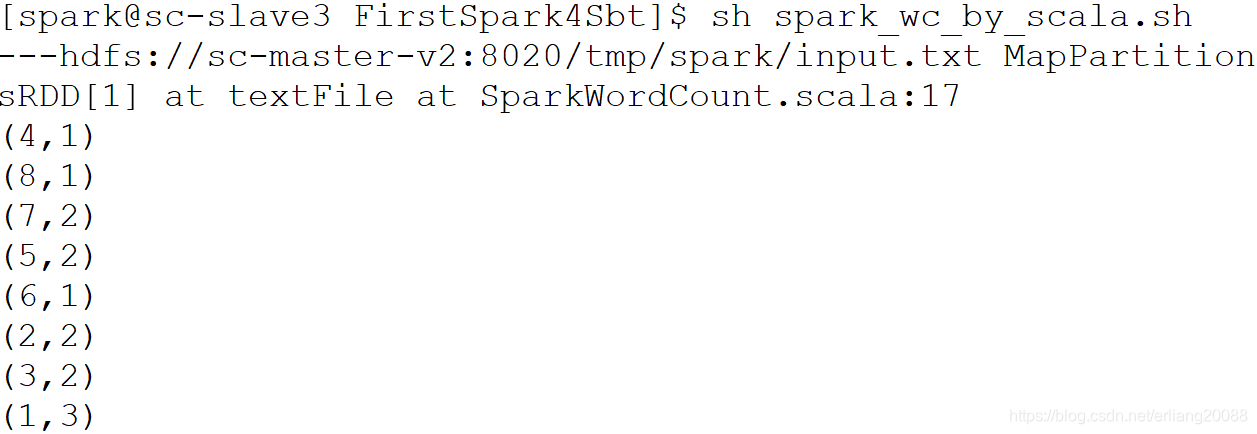
- 将jar上传到入口机中,并编写脚本spark_wc_by_scala.sh,如下所示
#! /bin/sh
# 配置成YARN配置文件存放目录
export HADOOP_CONF_DIR=/usr/hdp/2.5.3.0-37/hadoop/conf
SPARK_JAR=/usr/hdp/2.5.3.0-37/spark/lib/spark-assembly-1.6.2.2.5.3.0-37-hadoop2.7.3.2.5.3.0-37.jar
/usr/hdp/2.5.3.0-37/spark/bin/spark-submit \
--class com.tl.job003.examples.SparkWordCount \
--master local \
--driver-memory 512m \
--executor-memory 512m \
--num-executors 2 \
--jars $SPARK_JAR \
/home/spark/FirstSpark4Sbt/SparkWordCount4Sbt-assembly-0.1.0-SNAPSHOT.jar \
hdfs://sc-master-v2:8020/tmp/spark/input.txt \
hdfs://sc-master-v2:8020/tmp/spark/output_001_1
-
直接 sh spark_wc_by_scala.sh执行即可,结果如下图所示
- 亦可以切换脚本中不同的执行模式运行,如yarn-client,yarn-cluster等等。
- 亦可以切换脚本中不同的执行模式运行,如yarn-client,yarn-cluster等等。
天亮教育是一家从事大数据云计算、人工智能、教育培训、产品开发、咨询服务、人才优选为一体的综合型互联网科技公司。
公司由一批BAT等一线互联网IT精英人士创建,
以"快乐工作,认真生活,打造高端职业技能教育的一面旗帜"为愿景,胸怀"让天下没有难找的工作"使命,
坚持"客户第一、诚信、激情、拥抱变化"的价值观,
全心全意为学员赋能提效,践行技术改变命运的初心。
更多学习讨论, 请加入
官方-天亮大数据交流-366784928
群二维码:
天亮教育公开课-从小白到大佬修成记-全系列视频地址:http://bbs.myhope365.com/forum.php?mod=viewthread&tid=1422&extra=page%3D1
欢迎关注天亮教育公众号,大数据技术资料与课程、招生就业动态、教育资讯动态、创业历程分享一站式分享,官方微信公众号二维码:

天亮教育官方群318971238,
爬虫、nlp技术qq群320349384
hadoop & spark & hive技术群297585251
教育培训官网:http://myhope365.com
项目研发业务尚云科技官网:http://shangyuninfo.com/
官方天亮论坛:http://bbs.myhope365.com/