在VBA中使用正则表达式受限需要引用Microsoft VBScript Regular Expressions 5.5类库。在VBA界面,“工具”-->“引用”,

定义正则表达式,如下例:
Dim reg As New regexp
With reg
.Global = True
.IgnoreCase = True
.MultiLine = False
.Pattern = "[^\u4E00-\u9FA50-9A-Za-z]+" ‘匹配所有非汉字、非数字0-9、非字母
End With
Content = reg.Replace(Content, ",") ‘将匹配的内容用英文状态逗号替换
- 正则表达式的四个属性说明:
- Global:设置为true表示查找引擎返回找到的所有符合要求的子字符串,设置为false表示只返回找到的第一个符合要求的子字符串。
- IgnoreCase:设置为true表示查找时忽略大小写,设置为FALSE表示查找时区分大小写。
- Pattern:存放正则表达式
- MultiLine:如果为false,则通配符可以匹配换行符。
- 正则表达式有3个方法:
- Execute方法:语法object. Execute(sourcestring as string) as string, object为你定义的正则表达式对象(如:regEX),参数sourcestring为要对其进行查找的字符串(如例中的"这有一本关于VBA的书,它在第二个书柜里")。Execute方法查找并返回符合要求的字符串的集合,相当于使用“查找”功能。 Test方法:语法object. Execute(sourcestring as string) as string,其结构和用法和Execute方法一样,它和Execute方法唯一不同的是Test方法只进行测试查找,而不会返回符合要求的子字符串集合。一般用它判断是否可以找到符合要求的字符串。 Replace方法:语法object.
- Replace(sourcestring as string,Replace) as string, object为你定义的正则表达式对象,参数sourcestring为要对其进行查找的字符串, 参数Replacevar为要替换成的内容(如例中的"book")。
- Replace方法查找并返回符合要求的字符串的集合,然后对集合里的字符串进行替换。相当于先使用“查找”功能然后再使用“替换”功能。
- MatchCollection对象与Match对象
匹配到的所有对象放在MatchCollection集合中,这个集合对象只有两个只读属性:
Count:匹配到的对象的数目
Item:集合的又一通用方法,需要传入Index值获取指定的元素。
一般,可以使用For Each语句枚举集合中的对象。集合中对象的类型是Match。
Match对象有以下几个只读的属性:
FirstIndex - 匹配字符串在整个字符串中的位置,值从0开始。
Length - 匹配字符串的长度。
Value - 匹配的字符串。
SubMatches - 集合,匹配字符串中每个分组的值。作为集合类型,有Count和Item两个属性。
- 常用正则表达式
- 匹配中文字符的正则表达式: [\u4e00-\u9fa5]
- 匹配双字节字符(包括汉字在内):[^\x00-\xff]
- 匹配空白行的正则表达式:\n\s*\r
- 匹配HTML标记的正则表达式:<(\S*?)[^>]*>.*?</\1>|<.*? />
- 匹配首尾空白字符的正则表达式:^\s*|\s*$
- 匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
- 匹配网址URL的正则表达式:[a-zA-z]+://[^\s]*
- 匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
- 匹配国内电话号码:\d{3}-\d{8}|\d{4}-\d{7}
- 匹配腾讯QQ号:[1-9][0-9]{4,}
- 匹配中国邮政编码:[1-9]\d{5}(?!\d)
- 匹配身份证:\d{15}|\d{18} 评注:中国的身份证为15位或18位
- 匹配ip地址:\d+\.\d+\.\d+\.\d+
- 匹配特定数字:
^[1-9]\d*$ //匹配正整数
^-[1-9]\d*$ //匹配负整数
^-?[1-9]\d*$ //匹配整数
^[1-9]\d*|0$ //匹配非负整数(正整数 + 0)
^-[1-9]\d*|0$ //匹配非正整数(负整数 + 0)
^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ //匹配正浮点数
^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ //匹配负浮点数
^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$ //匹配浮点数
^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$ //匹配非负浮点数(正浮点数 + 0)
^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$ //匹配非正浮点数(负浮点数 + 0)
评注:处理大量数据时有用,具体应用时注意修正
14)匹配特定字符串:
^[A-Za-z]+$ //匹配由26个英文字母组成的字符串
^[A-Z]+$ //匹配由26个英文字母的大写组成的字符串
^[a-z]+$ //匹配由26个英文字母的小写组成的字符串
^[A-Za-z0-9]+$ //匹配由数字和26个英文字母组成的字符串
^\w+$ //匹配由数字、26个英文字母或者下划线组成的字符串
【例1】匹配一次
Worksheets("sheet1").Activate
Content = "张三;李四!王武佳、高寒;陈庆,郑强叁”晓红。赵楼.金三峰"
Dim reg
Set reg = CreateObject("VBSCRIPT.REGEXP")
Dim mc As Match
reg.Pattern = "[\u4E00-\u9FA50-9A-Za-z]+"
Dim row As Integer
row = 1
If reg.test(Content) Then
Debug.Print reg.Execute(Content)(0).Value '输出张三
End If
【例2】匹配所有满足条件的内容
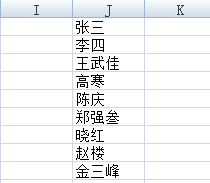
Sub test()
Worksheets("sheet1").Activate
Content = "张三;李四!王武佳、高寒;陈庆,郑强叁”晓红。赵楼.金三峰"
Dim reg As New RegExp
Dim mc As MatchCollection
With reg
.Global = True
.IgnoreCase = True
.MultiLine = False
.Pattern = "[\u4E00-\u9FA50-9A-Za-z]+"
End With
Dim row As Integer
row = 1
If reg.test(Content) Then
Set mc = reg.Execute(Content)
For Each mt In mc
Cells(row, "J").Value = mt.Value
row = row + 1
Next
End If
End Sub
结果为:
【例三】匹配优先 及非匹配优先
Sub test()
Rem 匹配优先(贪婪模式)
Dim str As String
str = "abcesfa"
Set reg = CreateObject("vbscript.regexp")
Dim mat As Match
reg.Pattern = "\w+"
result = reg.Execute(str)(0).value '结果为abcesfa
Debug.Print result
Rem 忽略匹配优先(非贪婪模式)
reg.Pattern = "\w+?"
result = reg.Execute(str)(0).value '结果为a
Debug.Print result
End Sub
【例四】后向引用:找出所有年份相同的
Sub test()
Dim str As String
str = "张三20120212到20120922;李斯20110101到2020150909;王武2009到2009;金荣2008到2009"
Set reg = CreateObject("vbscript.regexp")
Dim mat As Match
reg.Pattern = "(\d{4})[^;]+\1+([^;]*)" //\1表示第一个括号匹配的内容
reg.Global = True
For Each mat In reg.Execute(str)
Debug.Print mat.value
Next
End Sub
输出结果:
20120212到20120922
2009到2009
【例五】正向环视:找出下面字符串中的所有金额,金额后面有单位“元”或“块”
Sub test()
Dim str As String
str = "张三买了2把扫帚花了22.89元;李斯买了12个水杯花费98.00块钱"
Set reg = CreateObject("vbscript.regexp")
Dim mat As Match
reg.Pattern = "([\d|.]+)(?=[元|块])"
reg.Global = True
For Each mat In reg.Execute(str)
Debug.Print mat.value
Next
End Sub
结果为:
22.89
98.00
【例六】正向否定环视:找出下面字符串中所有的字母组成的字符串
Sub test()
Dim str As String
str = "asdf张三vdajo?asdv李斯n213749fbi王武:"
Set reg = CreateObject("vbscript.regexp")
Dim mat As Match
reg.Pattern = "\w+(?![a-z])"
reg.Global = True
For Each mat In reg.Execute(str)
Debug.Print mat.value
Next
End Sub
结果为:
asdf
vdajo
asdv
n213749fbi
【例七】分组的应用
Sub test()
Dim str As String
str = "财务部23人;后勤部32人;外交部20人"
Set reg = CreateObject("vbscript.regexp")
Dim mat As MatchCollection
reg.Pattern = "([\u4e00-\u9fa5]{3,})(\d+人)"
reg.Global = True
Set mat = reg.Execute(str)
For i = 0 To mat.Count - 1
Debug.Print mat(i).SubMatches(0) & ":" & mat(i).SubMatches(1)
Next
End Sub
结果为:
财务部:23人
后勤部:32人
外交部:20人