#正则表达式
首先明确一下学习正则表达式的初衷
读完了虫师的自动化实践书,自己动手想写一个接口测试,发现很多东西都不大会,很多地方卡死了,尤其卡在匹配字符上,师父让我直接用index取出字符,代码感觉不大美观。
正则表达式是一些有字符和特殊符号组成的字符串,它们描述了模式的重复或者表述多个字符
作用:为高级的文本模式匹配、抽取与为文本形式的搜索和替换功能提供了基础
这里推荐菜鸟工具
https://c.runoob.com/front-end/854
标准库中的re模块
模式匹配的完成方式:一是搜索search(),二是匹配match()
^匹配字符串起始部分

$匹配字符串结尾部分
*一次或多次出现的正则表达式
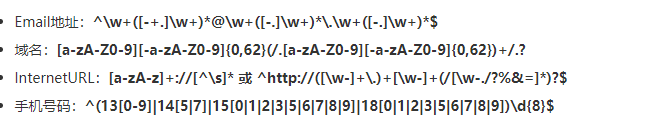
注意:
1、|匹配多个正则表达式模式
2、从字符串的开头和结尾或单词边界开始匹配(^/$/\b/\B)
3、匹配任意单个字符(.)(不包括\n)
4、创建字符集合[]
re模块函数的使用
import re
match() 开头开始,成功返回匹配对象,否则返回None
search() 查找正则表达式第一次出现,如果匹配成功返回匹配对象,否则返回None
findall() 在字符串中查找正则表达模式的所有(非重复)出现;返回一个列表
split() 根据正则表达式中的分隔符吧字符分割为一个列表,返回成功匹配的列表,可以设定次数(默认是分割所有匹配的地方)
sub() 把字符串中所有匹配正则表达式的地方替换成字符串,如果次数没有给出,则对所有匹配的地方进行替换
group() 返回所有匹配对象或是返回某个特定自足(指定编号是num的子组)
import re
re.match(‘app’,‘app123’).group()
‘app’
re.match(‘app’,‘123app’).group()
×
re.search(‘app’,‘app123’).group()
‘app’
findall()的妙用
findall(rule,target[,flag])
flags定义包括:
re.I 忽略大小写
re.L 表示特殊字符集\w,\W,\b,\B,\s,\S依赖于当前环境
re.M 多行模式
re.S '.‘并且包括换行符在内的任意字符(’.'不包括换行符)
re.U 表示特殊字符集\w,\W,\b,\B,\s,\S依赖于Unicode字符属性数据库
#爬取标题

//title=re.findall(’
print ‘’.join(title)
——转化为列表
#爬取链接
//links=re.findall('href="(.?)"’,html)
for each in links:
print each
sub()和subn()进行替换
用split()分隔(分隔模式)
贪婪匹配和非贪婪匹配
1、当正则表达式中包含能接受重复的限定符时,匹配尽可能多的字符
2、贪婪匹配:a.b,它将会匹配最长的以a开始,以b结束的字符串,如果让它来搜索aabab,它将会匹配整个字符串aabab
3、非贪婪匹配:贪婪模式它后面加上一个问号?。‘.?’就意味着在能使整个匹配成功的前提下使用最少的重复
4、a.*?b匹配最短的以a开始,以b结束的字符串,如果把它应用于aabab的话,他会匹配aab和ab