版权声明:如需转载,请注明出处 https://blog.csdn.net/qq_28385535/article/details/83721338
1.使用过程
- AnyQ系统安装完毕后,通过在build文件夹下执行
./run_server命令,来运行系统。系统启动完毕,即可在浏览器中输入http://${host}:${port}/anyq?question=XXX向AnyQ系统发出以question=后面的内容为问题的请求。 - 最初时,通过上述方式向AnyQ系统发送问题,页面返回结果为空,此时需要按下面文档所述方式对系统进行配置
https://github.com/baidu/AnyQ/blob/master/docs/semantic_retrieval_tutorial.md - 配置完毕后,即可向系统发送内容获取答案。但是,系统初始时仅提供5个问题-答案集,因此输入的问题仅与这10个问题进行语义相似度的计算。例如
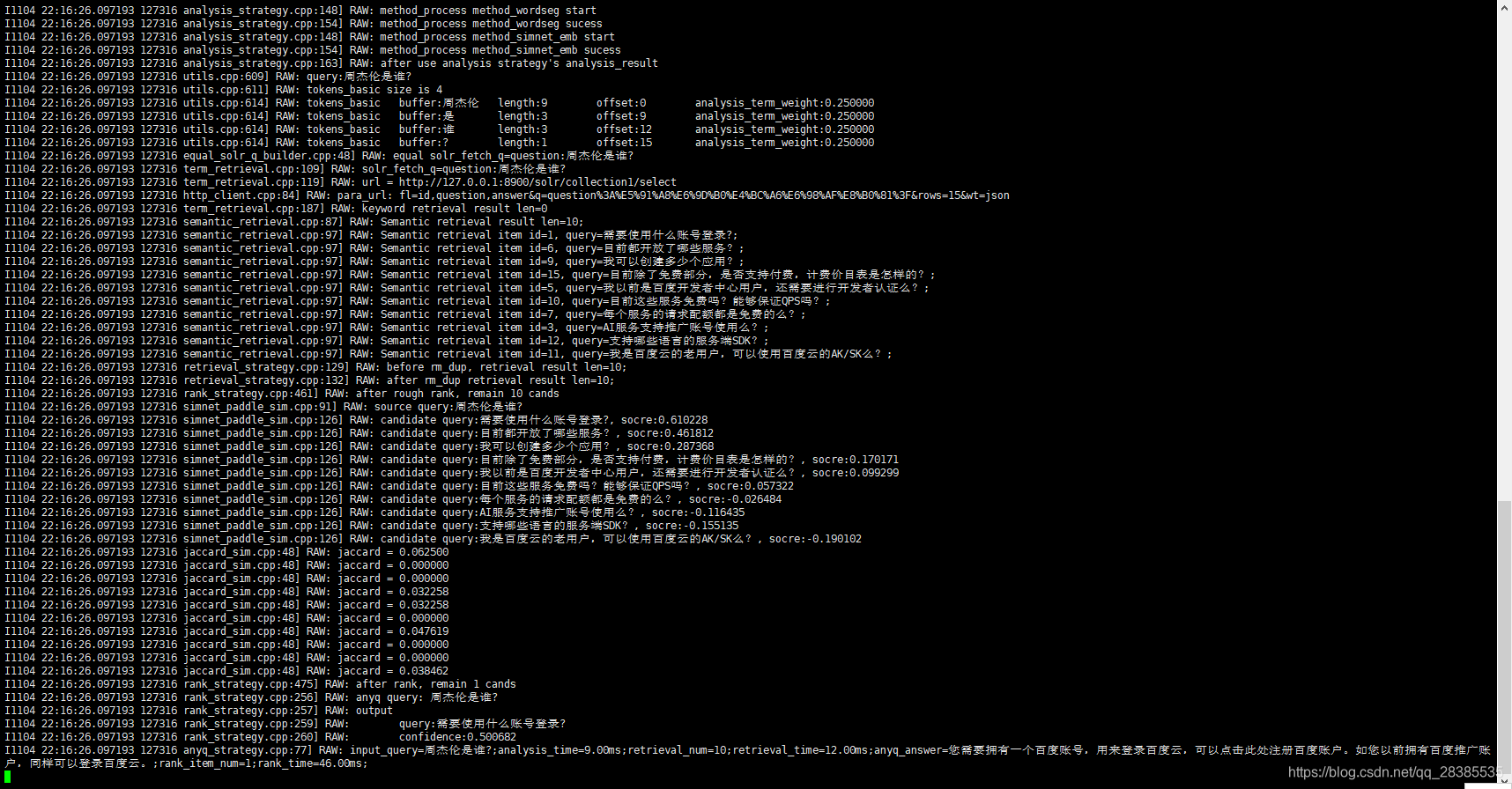
当我想question输入:周杰伦是谁?
后台系统仅进行如下计算
即仅将问题‘周杰伦是谁’与图片所示10个问题进行相似度计算,最终返回相似度最大的问题所对应的答案。
2.AnyQ系统框架及处理流程
AnyQ系统的整体架构如下所示:
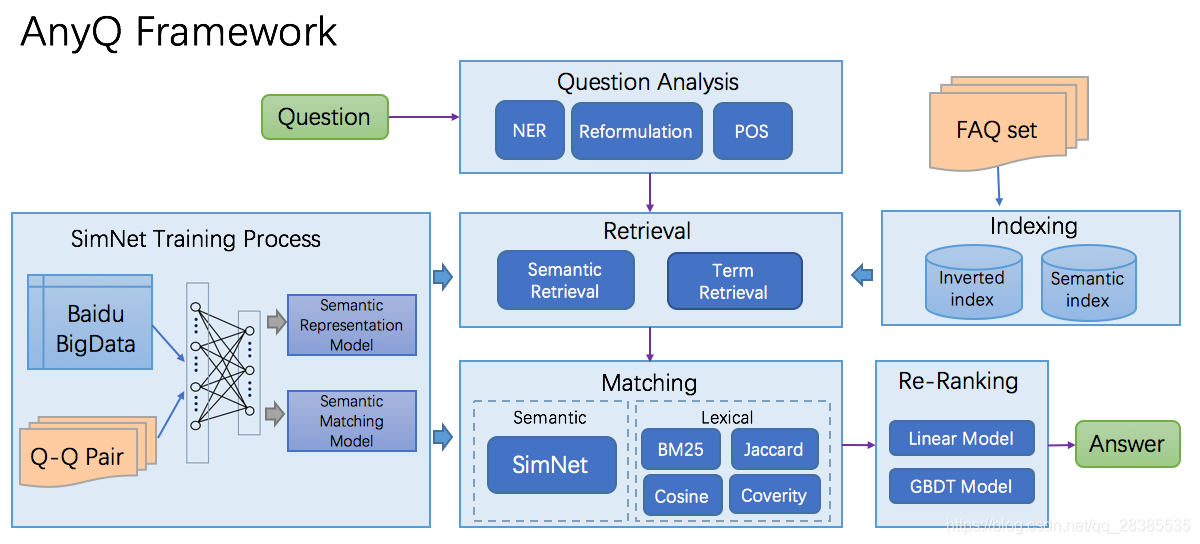
- 系统主要分为6个模块,每一个模块都以插件的形式进行添加和配置,也就是说每一个模块,都可以通过相应模块的配置文件,以JSON格式的形式,对已有插件,或自定义插件进行引用。
- 下面4个模块组成了一个问题的解析过程:
1.问题分析(Qusetion Analysis),详解:https://blog.csdn.net/qq_28385535/article/details/84446282
2.检索(Retrieval),详解:待续
3.匹配(Matching),详解:待续
4.分级(Ranking),详解:待续 - SimNet模块:用于计算语义相似度模型的训练,支持两种模型训练框架:
PaddleFluid
TensorFlow,详解:待续 - 索引模块:索引模块主要对FAQ数据集进行处理,并将处理好的数据应用到检索模块进行问题的解析。详解:https://blog.csdn.net/qq_28385535/article/details/83958168