前边我们讲述了:Java高并发——了解并行世界、Java高并发——多线程基础、Java高并发——多线程协作,同步控制 。从1,线程是什么?为什么需要多线程?2,Java对多线程的基础操作:线程的状态扭转,线程的创建、终止、中断、等待和通知、挂起和执行、等待结束和谦让,volatile关键字,线程组进行分类管理,守护线程,线程优先级,线程共享资源安全和synchronized进行控制。3,多线程的协作——同步控制:ReentrantLock重入锁为什么叫重入锁、中断的支持、等待时间控制、公平锁支持,Condition条件实现等待通知,Semahore信号量对一个共享资源控制多个线程的访问,ReadWriteLock读写锁对读多写少场景的支持,CountDownLatch倒计时器对线程的统一汇总,CyclicBarrier循环栅栏对线程进行循环统一汇总的支持,LockSupport利用信号量原理对线程进行阻塞和可执行…… 而,这么多线程的操作都有了,我们如何管理这些线程呢?
举个例子:工人干活,工人可以比喻为线程,工人如何干活好比单个线程的各种处理,工人如何分配公共工具,如何进行协作好比线程对共享资源的安全处理,以及各种协作通知。而工人的管理怎么办?线程的管理怎么办?总不能用的时候去招聘一个,不用的时候就解雇了吧(如果工作量不大的话,好像也行啊……)。好,下边我么看看线程池,好比工人团队。我们先看张思维导图吧,从这几个方便进行学习总结一下吧:
一,什么是线程池:
这个从上边的例子,想必已经能有很好的理解了。想必大家都用过数据库连接池,其实线程池也一样:为了避免系统频繁的创建和销毁线程(招聘解雇工人)带来的性能消耗,可以让线程得到很好的复用。当需要使用线程时从线程池取(原来是创建),当用完时归还线程池(原来是销毁)。
二,JDK中的线程池:
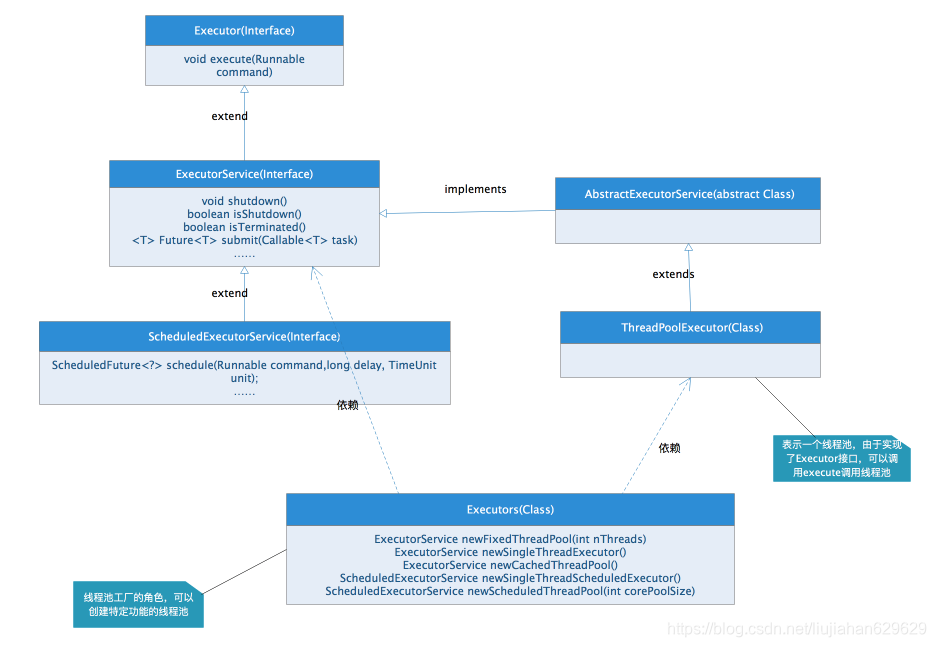
1,先看下JDK对线程池进行各种控制的类关系图(Executor框架),可以看着JDK的源码类,进行解读。通过Executors类方法可以看出,它的方法ExecutorService newFixedThreadPool(int nThreads)可以创建固定数量的线程池;方法ExecutorService newSingleThreadExecutor()可以创建只有一个线程的线程池;方法ExecutorService newCachedThreadPool() 可以返回一个根据实际情况调整线程数量的线程池;方法ScheduledExecutorService newSingleThreadScheduledExecutor()可以返回一个可以执行定时任务线程的线程池;方法ScheduledExecutorService newScheduledThreadPool(int corePoolSize)可以返回指定数量可以执行定时任务的线程池。当然这些方法都有重载方法,例如参数中加入自定义的ThreadFacotry等。
2,看下固定大小线程池的简单使用:
public class FixThreadPoolDemo {
public static class MyTask implements Runnable{
public void run() {
System.out.println(System.currentTimeMillis() + "Thread Name:" + Thread.currentThread().getName());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
MyTask myTask = new MyTask();
int size =5;
//下篇说下阿里技术规范插件对这个的提示问题
// ExecutorService executorService = new ThreadPoolExecutor(size,size,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());
// ThreadFactory namedThreadFactory = new ThreadFactoryBuilder().setNameFormat("thread-call-runner-%d").build();
// ExecutorService executorService2 = new ThreadPoolExecutor(size,size,0L,TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>(),namedThreadFactory);
ExecutorService es = Executors.newFixedThreadPool(size);
for (int i = 0; i < 10 ; i++) {
es.submit(myTask);
}
}
}3,看下定时任务线程池的简单使用:
public class ScheduledThreadPoolDemo {
public static void main(String[] args) {
ScheduledExecutorService executorService = Executors.newScheduledThreadPool(5);
/**
* 1,executorService.scheduleAtFixedRate:创建一个周期性任务,从上个任务开始,过period周期执行下一个(如果执行时间>period,则以执行时间为周期)
* 2,executorService.scheduleWithFixedDelay:创建一个周期上午,从上个任务结束,过period周期执行下一个。
*/
//如果前边任务没有完成则调度也不会启动
executorService.scheduleAtFixedRate(new Runnable() {
public void run() {
try {
Thread.sleep(1000);
System.out.println("当前时间:" + System.currentTimeMillis()/1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
},0,2, TimeUnit.SECONDS);
}
}三,线程池的实现原理:
1,通过看JDK源码可以知道上边五种类型的线程池创建无论哪种最后都是ThreadPoolExecutor类的封装,我们来看下ThreadPoolExecutor最原始的构造函数,和调度execute源码:
/**
* 1,corePoolSize:指定线程池中活跃的线程数量
* 2,maximumPoolSize:指定线程池中最大线程数量
* 3,keepAliveTime:超过corePoolSize个多余线程的存活时间
* 4,unit:keepAliveTime的时间单位
* 5,workQueue:任务队列,被提交但尚未被执行的任务
* 6,threadFactory:线程工厂,用于创建线程
* 7,handler拒绝策略:当任务太多来不及处理时,如何拒绝任务
*/
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
/**
* 三步:1,创建线程直到corePoolSize;2,加入任务队列;3,如果还是执行不过来,则执行拒绝策略
*/
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}2,workQueue,当任务被提交但尚未被执行的任务队列,是一个BlockingQueue接口的对象,只存放Runnable对象。根据队列功能分类,看下JDK提供的几种BlockingQueue:
| work queue class name | 说明 |
|---|---|
| SynchronousQueue | 直接提交队列:没有容量,每一个插入操作都要等待一个相应的删除操作。通常使用需要将maximumPoolSize的值设置很大,否则很容易触发拒绝策略。 |
| ArrayBlockingQueue | 有界的任务队列:任务大小通过入参 int capacity决定,当填满队列后才会创建大于corePoolSize的线程。 |
| LinkedBlockingQueue | 无界的任务队列:线程个数最大为corePoolSize,如果任务过多,则不断扩充队列,知道内存资源耗尽。 |
| PriorityBlockingQueue | 优先任务队列:是一个无界的特殊队列,可以控制任务执行的先后顺序,而上边几个都是先进先出的策略。 |
3,ThreadFactory,是用来创建线程池中的线程工厂类,我们来看下JDK中的默认DefaultThreadFactory类,并自己写个试试:
/**
* The default thread factory
*/
static class DefaultThreadFactory implements ThreadFactory {
private static final AtomicInteger poolNumber = new AtomicInteger(1);
private final ThreadGroup group;
private final AtomicInteger threadNumber = new AtomicInteger(1);
private final String namePrefix;
DefaultThreadFactory() {
SecurityManager s = System.getSecurityManager();
group = (s != null) ? s.getThreadGroup() :
Thread.currentThread().getThreadGroup();
namePrefix = "pool-" +
poolNumber.getAndIncrement() +
"-thread-";
}
public Thread newThread(Runnable r) {
Thread t = new Thread(group, r,
namePrefix + threadNumber.getAndIncrement(),
0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
}
/**
* 自定义试试
*/
public class ThreadFactoryDemo {
public static class MyTask implements Runnable{
public void run() {
System.out.println(System.currentTimeMillis() + "Thread Name:" + Thread.currentThread().getName());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
FixThreadPoolDemo.MyTask myTask = new FixThreadPoolDemo.MyTask();
ExecutorService es = new ThreadPoolExecutor(5, 5, 0L, TimeUnit.MILLISECONDS, new SynchronousQueue<Runnable>(), new ThreadFactory() {
public Thread newThread(Runnable r) {
Thread t =new Thread(r);
t.setDaemon(true);
System.out.println("create thread" + t.getName());
return t;
}
});
for (int i = 0; i < 10 ; i++) {
es.submit(myTask);
}
}
}4,拒绝策略:如果线程池处理速度达不到任务的出现速度时,只能执行拒绝策略,看下JDK提供几种,然后自定义看个例子:
| 策略名称 | 描述 |
|---|---|
| AbortPolicy | 该策略会直接抛出异常,阻止系统正常 工作。线程池默认为此。 |
| CallerRunsPolicy | 只要线程池未关闭,该策略直接在调用者线程中,运行当前被丢弃的任务。 |
| DiscardOledestPolicy | 该策略将丢弃最老的一个请求,也就是即将被执行的一个任务,并尝试重新提交当前任务。 |
| DiscardPolicy | 该策略默默地丢弃无法处理的任务,不予任务处理。 |
public class RejectThreadPoolDemo {
public static class MyTask implements Runnable{
public void run() {
System.out.println(System.currentTimeMillis() + "Thread Name:" + Thread.currentThread().getName());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
FixThreadPoolDemo.MyTask myTask = new FixThreadPoolDemo.MyTask();
ExecutorService es = new ThreadPoolExecutor(5, 5, 0L, TimeUnit.MILLISECONDS, new ArrayBlockingQueue<Runnable>(10), Executors.defaultThreadFactory(), new RejectedExecutionHandler() {
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
System.out.println(r.toString() + "is discard");
}
});
for (int i = 0; i < 20 ; i++) {
es.submit(myTask);
}
}
}四,线程池的扩展:JDK已经对线程池做了非常好的编写,如果我们想扩展怎么办呢?ThreadPoolExecutor提供了三个方法供我们使用:beforeExecute()每个线程执行前,afterExecute()每个线程执行后,terminated()线程池退出时。我们只要对这个三方法进行重写即可:
public class ExtThreadPoolDemo {
public static class MyTask implements Runnable{
public void run() {
System.out.println(System.currentTimeMillis() + "Thread Name:" + Thread.currentThread().getName());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws InterruptedException {
FixThreadPoolDemo.MyTask myTask = new FixThreadPoolDemo.MyTask();
ExecutorService es = new ThreadPoolExecutor(5, 5, 0L, TimeUnit.MILLISECONDS, new ArrayBlockingQueue<Runnable>(10)){
@Override
protected void beforeExecute(Thread t, Runnable r) {
System.out.println("准备执行线程:" + r.toString() +"===" + t.getName());
}
@Override
protected void afterExecute(Runnable r, Throwable t) {
System.out.println("执行完成线程:" + r.toString());
}
@Override
protected void terminated() {
System.out.println("线程池退出" );
}
};
for (int i = 0; i < 10 ; i++) {
es.submit(myTask);
}
Thread.sleep(3000);
es.shutdown();
}
}五,线程数量的优化:线程池的大小对系统性能有一定的影响,过大或者过小都无法发挥系统的最佳性能。但是也没有必要做的特别精确,只是不要太大,不要太小即可。我们可以根据此公式进行粗略计算:线程池个数=CPU的数量*CPU的使用率*(1+等待时间/计算时间)。当然了还需要根据实际情况,积累实际经验,来进行判断。
六,线程池中的堆栈信息,我们通过下边两个例子进行查看:
/**
* 会吃掉一些异常信息,非常不友好
*/
public class ExceptionThreadPoolDemo {
public static class MyTask implements Runnable {
int a, b;
public MyTask(int a, int b) {
this.a = a;
this.b = b;
}
public void run() {
double re = a / b;
System.out.println(re);
}
}
public static void main(String[] args) {
//ExecutorService es = new TraceThreadPoolExecutor(0,Integer.MAX_VALUE,0L, TimeUnit.SECONDS,new SynchronousQueue<Runnable>());
ExecutorService es = new ThreadPoolExecutor(0,Integer.MAX_VALUE,0L, TimeUnit.SECONDS,new SynchronousQueue<Runnable>());
for (int i = 0; i < 5; i++) {
//不进行日志打印
//es.submit(new MyTask(100,i));
//进行日志打印,只是打印了具体方法错误:Exception in thread "pool-1-thread-1" java.lang.ArithmeticException: / by zero
// at com.ljh.thread.thread_pool.ExceptionThreadPoolDemo$MyTask.run(ExceptionThreadPoolDemo.java:24)
// at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
// at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
// at java.lang.Thread.run(Thread.java:748)
es.execute(new MyTask(100,i));
}
}
}
/**
* 通过自定自己的线程池,重写execute和submit方法,将异常打印出来:
*/
public class TraceThreadPoolExecutor extends ThreadPoolExecutor {
public TraceThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);
}
@Override
public void execute(Runnable command) {
super.execute(wrap(command,ljhTrace(),Thread.currentThread().getName()));
}
@Override
public Future<?> submit(Runnable task) {
return super.submit(wrap(task,ljhTrace(),Thread.currentThread().getName()));
}
private Exception ljhTrace(){
return new Exception("ljh-stack-trace");
}
private Runnable wrap(final Runnable task , final Exception ljhException,String threadName){
return new Runnable() {
public void run() {
try {
task.run();
}catch (Exception e){
ljhException.printStackTrace();
e.printStackTrace();
}
}
};
}
}七,最后看下分而治之:Fork/Join:大家都知道hadoop中的Map-Reduce分开处理,合并结果;当今流行的分布式,将用户的请求分散处理等等。分而治之是非常有用实用的。JDK帮我们提供了ForkJoinPool线程池,供我们做这些处理,有两个子类供我们使用,Recursive有返回值,RecursiveAction无返回值,看个例子吧:
public class ForkJoinThreadPoolDemo extends RecursiveTask<Long> {
private static final int THRESHOLD = 10000;
private long start;
private long end;
public ForkJoinThreadPoolDemo(long start, long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
long sum = 0;
boolean canCompute = (end - start) < THRESHOLD;
if (canCompute) {
for (long i = start; i < end; i++) {
sum += i;
}
} else {
//分成100份进行处理
long step = (start + end) / 50;
ArrayList<ForkJoinThreadPoolDemo> subTasks = new ArrayList<ForkJoinThreadPoolDemo>();
long pos = start;
for (int i = 0; i < 50; i++) {
long lastOne = pos + step;
if (lastOne > end) {
lastOne = end;
}
ForkJoinThreadPoolDemo subTask = new ForkJoinThreadPoolDemo(pos, lastOne);
pos += step;
subTasks.add(subTask);
subTask.fork();
}
for (ForkJoinThreadPoolDemo t : subTasks) {
sum += t.join();
}
}
return sum;
}
//结果199990000
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool();
ForkJoinThreadPoolDemo task = new ForkJoinThreadPoolDemo(0, 20000);
ForkJoinTask<Long> result = forkJoinPool.submit(task);
try {
long res = result.get();
System.out.println("结果" + res);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}好,JDK线程池的知识就到这吧,困了,睡觉了……