1、数据倾斜的原理
2、数据倾斜的现象
3、数据倾斜的产生原因与定位
在执行shuffle操作的时候,大家都知道,我们之前讲解过shuffle的原理。
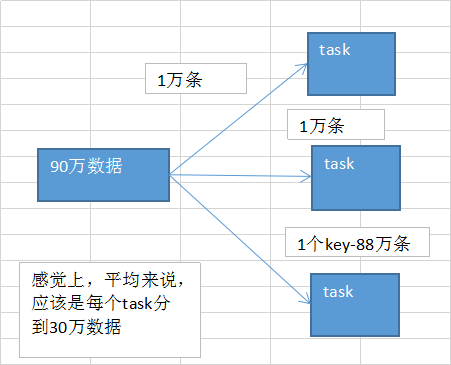
是按照key,来进行values的数据的输出、拉取和聚合的。 同一个key的values,一定是分配到一个reduce task进行处理的。 多个key对应的values,总共是90万。
但是问题是,可能某个key对应了88万数据,key-88万values,分配到一个task上去面去执行。 另外两个task,可能各分配到了1万数据,可能是数百个key,对应的1万条数据。
想象一下,出现数据倾斜以后的运行的情况。很糟糕!极其糟糕!无比糟糕!
第一个和第二个task,各分配到了1万数据;那么可能1万条数据,需要10分钟计算完毕;第一个和第二个task,可能同时在10分钟内都运行完了;第三个task要88万条,88 * 10 = 880分钟 = 14.5个小时;
大家看看,本来另外两个task很快就运行完毕了(10分钟),但是由于一个拖后腿的家伙,第三个task,要14.5个小时才能运行完,就导致整个spark作业,也得14.5个小时才能运行完。
导致spark作业,跑的特别特别特别特别慢!!!像老牛拉破车! 数据倾斜,一旦出现,是不是性能杀手。。。。
发生数据倾斜以后的现象:
spark数据倾斜,有两种表现:
1、你的大部分的task,都执行的特别特别快,刷刷刷,就执行完了(你要用client模式,standalone client,yarn client,本地机器主要一执行spark-submit脚本,就会开始打印log),task175 finished;剩下几个task,执行的特别特别慢,前面的task,一般1s可以执行完5个;最后发现1000个task,998,999 task,要执行1个小时,2个小时才能执行完一个task。 出现数据倾斜了 还算好的,因为虽然老牛拉破车一样,非常慢,但是至少还能跑。
2、运行的时候,其他task都刷刷刷执行完了,也没什么特别的问题;但是有的task,就是会突然间,啪,报了一个OOM,JVM Out Of Memory,内存溢出了,task failed,task lost,resubmitting task。反复执行几次都到了某个task就是跑不通,最后就挂掉。 某个task就直接OOM,那么基本上也是因为数据倾斜了,task分配的数量实在是太大了!!!所以内存放不下,然后你的task每处理一条数据,还要创建大量的对象。内存爆掉了。 出现数据倾斜了 这种就不太好了,因为你的程序如果不去解决数据倾斜的问题,压根儿就跑不出来。 作业都跑不完,还谈什么性能调优这些东西。扯淡。。。
定位原因与出现问题的位置:
根据log去定位 出现数据倾斜的原因,基本只可能是因为发生了shuffle操作,在shuffle的过程中,出现了数据倾斜的问题。因为某个,或者某些key对应的数据,远远的高于其他的key。
1、你在自己的程序里面找找,哪些地方用了会产生shuffle的算子,groupByKey、countByKey、reduceByKey、join
2、看log log一般会报是在你的哪一行代码,导致了OOM异常;或者呢,看log,看看是执行到了第几个stage!!! 我们这里不会去剖析stage的划分算法,spark代码,是怎么划分成一个一个的stage的。哪一个stage,task特别慢,就能够自己用肉眼去对你的spark代码进行stage的划分,就能够通过stage定位到你的代码,哪里发生了数据倾斜 去找找,代码那个地方,是哪个shuffle操作。