上一章介绍了hadoop的HDFS文件系统的原理及API使用。本章博主将继续对hadoop的mapreduce编程框架进行分享。
mapreduce原理篇
mapreduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架;mapreduce的核心功能是将用户编写的业务逻辑代码和自带的默认组件整合成一个完整的分布式运算程序,并发运行在一个hadoop集群上;
为什么要mapreduce:
(1).海量数据在单机上处理因为硬件资源限制,无法胜任
(2).而一旦将单机版程序扩展到集群来分布式运行,将极大增加程序的复杂度和开发难度
(3).引入mapreduce框架后,开发人员可以将绝大部分工作集中在业务逻辑的开发上,而将分布式计算中的复杂性交由框架来处理
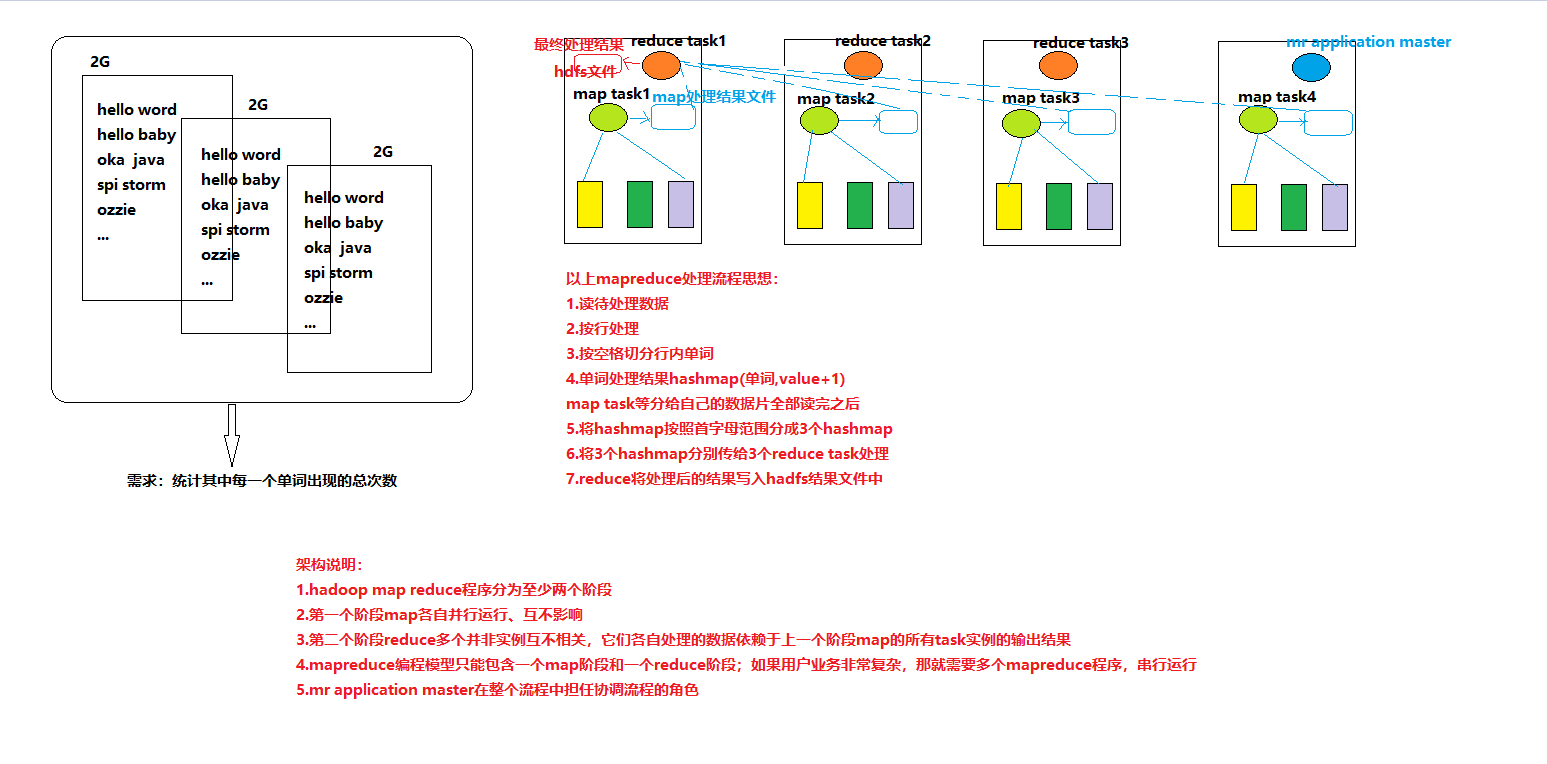
mapreduce的整体结构包含:一个完整的mapreduce程序在分布式运行时有三类实例进程;
1.MRAppMaster(mapreduce application master):负责整个程序的过程调度及状态协调
2.MapTask:负责map阶段的整个数据处理流程
3.ReduceTask:负责reduce阶段的整个数据处理流程
mapredcue核心框架设计思想:
最后寄语,以上是博主本次文章的全部内容,如果大家觉得博主的文章还不错,请点赞;如果您对博主其它服务器大数据技术或者博主本人感兴趣,请关注博主博客,并且欢迎随时跟博主沟通交流。