python内置函数:compile()
描述
compile() 函数将一个字符串编译为字节代码。
语法
以下是 compile() 方法的语法:
compile(source, filename, mode[, flags[, dont_inherit]])参数
- source -- 字符串或者AST(Abstract Syntax Trees)对象。。
- filename -- 代码文件名称,如果不是从文件读取代码则传递一些可辨认的值。
- mode -- 指定编译代码的种类。可以指定为 exec, eval, single。
- flags -- 变量作用域,局部命名空间,如果被提供,可以是任何映射对象。。
- flags和dont_inherit是用来控制编译源码时的标志
返回值
返回表达式执行结果。
source_code = \
'''
base_string = 'julyedu.com'
def test1(a,b):
return a+b
def test2(c):
x = 7
print(c**2+x)
'''
co = compile(source_code,'test_compile.py','exec')
exec(co)
test1(2,6),test2(7)
co.co_code
co.__dir__()
test1.__code__.co_argcount
test2.__code__.co_varnames
test2.__code__.co_nlocals输出:
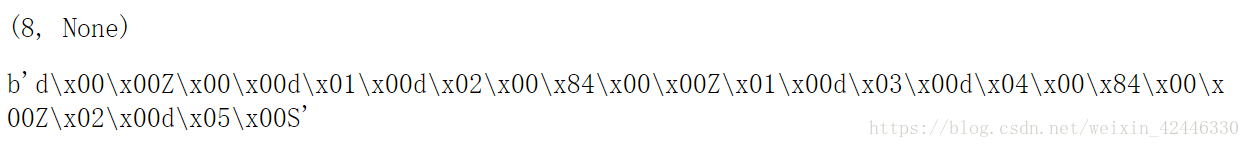
['__repr__',
'__sizeof__',
'__eq__',
'__subclasshook__',
'co_cellvars',
'__class__',
'co_firstlineno',
'co_consts',
'__ge__',
'__reduce__',
'__reduce_ex__',
'co_flags',
'__getattribute__',
'co_filename',
'co_stacksize',
'co_nlocals',
'__new__',
'__dir__',
'__hash__',
'__init__',
'__format__',
'__delattr__',
'__doc__',
'__ne__',
'co_names',
'co_freevars',
'__str__',
'co_lnotab',
'co_kwonlyargcount',
'co_name',
'co_code',
'co_varnames',
'__setattr__',
'__lt__',
'__le__',
'__gt__',
'co_argcount']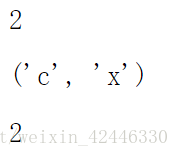
内置模块二:dis模块主要是用来分析字节码的一个内置模块,经常会用到的方法是dis.dis([bytesource]),参数为一个代码块,可以得到这个代码块对应的字节码指令序列。
具体可以看这个文档: https://docs.python.org/3/library/dis.html
import dis
dis.dis(co)#反汇编module test_compile
# dis.dis(test1),dis.dis(test2)#反汇编module test_compile下的函数输出结果:

Disassembler格式及解读
- 第一列表示以下几个指令在py文件中的行号;
- 第二列是该指令在指令序列co_code里的偏移量;
- 第三列是指令opcode的名称,分为有操作数和无操作数两种,opcode在指令序列中是一个字节的整数;
- 第四列是操作数oparg,在指令序列中占两个字节,基本都是co_consts或者co_names的下标;
- 第五列带括号的是操作数说明。
记录几个jupyter notebook常用的指令:
前面加!表示调用系统本身命令,%表示调用jupyter内部魔法命令
%lsmagic 可以看到所有的魔法命令
%quickref 表示所有魔法命令的解释文档
%config ZMQInteractiveShell.ast_node_interactivity='all' 表示一个可以修改内核选项 ast_note_interactivity,使得 Jupyter 对独占一行的所有变量或者语句都自动显示,这样你就可以马上看到多个语句的运行结果了。
%%writefile 直接写入文件
%run 直接脚本运行py文件
更多jupyter notebook的使用,我还收藏了:https://blog.csdn.net/m0_37870649/article/details/79453005
这位仁兄写的比较全,可以看看。
帮助的使用
#dir,help,?,??,shift+tab,tab,相关Python的小抄
还有可以将shift+tab 光标在函数上就可以显示。
在写一个可以观察运行中内存占用的代码:
lesson = ['2018','2019','2020']
import sys
sys.getrefcount(lesson)
import psutil
def rss():
m = psutil.Process().memory_info()
print(m.rss>>20,'MB') #>>表示输出小数位
rss()
x = list(range(20000000))
rss()
del x
rss()
输出结果如下:

垃圾回收的内置函数:gc
import gc
gc.get_count()#看看当前的垃圾的计数
gc.get_threshold()#查看针对每代自动执行垃圾回收的阈值,可以使用gc.set_threshold重新设置阈值
# 当没有回收的0代对象个数超过700,即开始0级垃圾回收,
# 当0代垃圾回收超过10次即开始1级垃圾回收,1级垃圾回收清除包括0级垃圾,
# 当1代垃圾回收超过10次,即开始2级垃圾回收,2级垃圾回收清除包括0级,1级垃圾
#垃圾回收机制python默认开启的,gc.disabled可关闭垃圾回收机制
#而使用gc.collect([generation])显式手动进行垃圾回收
gc.collect(2)#回收2级垃圾,也可以指定0,1输出结果;

格式化访问的两种形势:
格式化访问一:
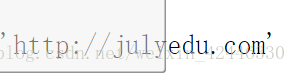
str3='http://{}.com'
companyName='julyedu'
str3.format(companyName)
格式化访问二:
_='Python 3'
str4=f"fstring is new feature of {_}"
str4第二种是python3的新特性。
输出结果: