Python3 FreeType库介绍:
安装命令:
python -m pip install freetype-pyfreetype为字体字库提供了一套解决方案,支持文字字体渲染等操作,主要还是其为C语言编写,跨平台,为很多不支持矢量字体格式的嵌入式系统提供使用嵌入式字体的可能,且效率不低。
使用FreeType进行字符转换的基本流程:
创建一个face对象,加载字体字库文件.ttf;
将字符串转换成一系列字形索引;
设定笔位置(原点)到字符串第一个字形原点位置;
将字形渲染到目标设备;
根据字形的步进象素增加笔位置;
对剩余的字形重复第三步向下的步骤。
字形:
字符映像叫做字形,单个字符能够有多个不同的映像,即多个字形。多个字符也可以有一个字形。(可以理解为一个字形就是一种书写风格)
字符图:
字体文件包含一个或多个表,叫做字符图,用来将某种字符码转换成字形索引。一种字符编码方式(如ASCII、Unicode、Big5)对应一张表。
像素、点和设备解析度:
通常计算机的输出设备是屏幕或打印机,在水平和垂直方向都有多种分辨率,当我们使用FreeType渲染文本时要注意这些情况。
设备的分辨率通常使用dpi(每英寸点(dot)数)表示的两个数。如,一个打印机的分辨率为300x600dpi表示在水平方向,每英寸有300 个像素,在垂直方向有600个像素。
文本的大小通常用点(point)表示。点是一种简单的物理单位,在数字印刷中,一点等于1/72英寸。
我们可以用点数大小来计算像素数,公式如下:
像素数 = 点数*分辨率/72
单个点数通常定义不同象素文本宽度和高度。
轮廓线:
字形轮廓的源格式是一组封闭的路径,称为轮廓线。每个轮廓线划定字形的外部或内部区域,它们可以是线段或者Bezier曲线。
EM正方形:
字体在创建字形轮廓时,字体创建者所使用的假象的正方形。他可以将此想象成一个画字符的平面。它是用来将轮廓线缩放到指定文本尺寸的参考,如在300x300dpi中的12pt大小对应12*300/72=50象素。
正方形的大小,即它边长的网格单元是很重要的。如从网格单元缩放到象素可以使用下面的公式:
象素数 = 点数 × 分辨率/72
象素坐标= 网格坐标*象素数/EM大小
EM尺寸越大,可以达到更大的分辨率,例如一个极端的例子,一个4单元的EM,只有25个点位置,显然不够,通常TrueType字体之用2048单元的EM;Type1 PostScript字体有一个固定1000网格单元的EM,但是点坐标可以用浮点值表示。
注意:
字形可以自由超出EM正方形。网格单元通常交错字体单元或EM单元。上边的象素数并不是指实际字符的大小,而是EM正方形显示的大小,所以不同字体,虽然同样大小,但是它们的高度可能不同。
位图渲染:
指从字形轮廓转换成一个位图的过程。
基线:
基线是一个假象的线,用来在渲染文本时知道字形,它可以是水平或垂直的。
笔位置(原点):
为了渲染文本,在基线上有一个虚拟的点,叫做笔位置或原点,它用来定位字形。
布局:
布局有水平布局和垂直布局,每种布局使用不同的规约来放置字形。仅有少数字体格式支持垂直布局。
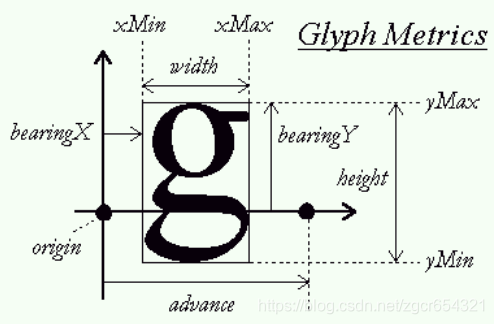
Glyph metrics(字形指标):指创建一个文本布局组织每个字形时描述字形如何定位的确切距离。
对水平布局,字形简单地搁在基线上,通过增加笔位置来渲染文本,既可以向右也可以向左增加。两个相邻笔位置之间的距离叫做步进宽度(advanceX)。注意这个值总是正数 。笔位置总是放置在基线上。
对垂直布局,字形在基线上居中放置:

重要的字体布局参数:
边界框(bounding box,bbox):这是一个假想的框子,即一个紧密地包围字符的轮廓。通过四个值来表示,叫做xMin 、yMin 、xMax 、yMax ,对任何轮廓都可以计算;
上行高度(ascent):从基线到放置轮廓点最高(上)的距离;
下行高度(descent):从基线到放置轮廓点最低(下)的距离;
左跨距(bearingX):从当前笔位置(原点)到包围字符的轮廓的水平距离,用于水平布局;
上跨距(bearingY):从当前笔位置(原点)到包围字符的轮廓的垂直距离,用于垂直布局;
步进宽度(advanceX):相邻两个原点的水平距离(字间距), 用于水平布局,即用来确定下一个字符的笔位置(原点)。
步进宽度(advanceY):相邻两个原点的垂直距离(字间距), 用于垂直布局,即用来确定下一个字符的笔位置(原点)。
字形宽度(width):包围字符的轮廓的水平长度,与是水平布局还是垂直布局无关;
字形高度(height):包围字符的轮廓的垂直长度,与是水平布局还是垂直布局无关。
注意:
每个字形最初的轮廓点放置在一个不可分割单元的网格中,点通常在字体文件中以16 位整型网格坐标存储,网格的原点在(0,0) ,它的范围是-16384 到-16383。
AdvanceX值通常四舍五入为整数像素坐标(例如是64的倍数),字体驱动器用它装载字形图像。
Python3使用FreeType库生成不定长验证码的实现代码:
PutChineseText类:
init创建一个face对象,装载一种字体文件.ttf;
draw_text方法输入一个空白图片(三维数组形式)、要画在图片上的文本内容、文本在图片上的起始位置(像素点为单位)、字体大小(像素点为单位)、字体颜色(RGB颜色),调用draw_string方法返回一个画好文本的图片(三维数组形式);
draw_string方法用来将输入的文本一个字符一个字符地转换成字形,再调用draw_ft_bitmap方法将字形一个一个地画在图片上
在空白图片(三维数组形式)上,该方法输入文本在图片上的起始位置(1/64像素点为单位)、文本内容和颜色
draw_ft_bitmap方法输入空白图片(三维数组形式)、要画成位图的字形、字形的原点位置(1/64像素点为单位)、字体颜色,画出一个带有字形转换成的位图的图片。
GenerateCharListImage()类:
init初始化候选字符集为0-9十个数字,候选字符集的长度,生成的不定长验证码的最大长度,一个PutChineseText类对象(定义使用OCR-B.ttf字体);
random_text方法生成一个随机长度的字符序列和其对应的标签向量;
generate_color_image方法生成一个带不定长的验证码的彩色图片;
image_add_salt_noise方法和image_add_gaussian_noise方法可以给一张图片(三维数组形式)添加椒盐噪声和高斯噪声;
image_reduce_noise方法使用方框滤波给一张图片(三维数组形式)降噪;
color_image_to_gray_image方法将一张三维数组形式的图片转变成灰度图片,并且每个像素点只保留一个值(灰度图片的RGB三个通道的值相同),并将图片形式变成一维数组;
one_char_to_one_element_vector方法将单个字符生成对应的标签向量;
text_vector_to_text方法将由一个标签向量生成对应字符串。
完整代码如下:
import numpy as np
import freetype
import copy
import random
import cv2
import os
# 使用FreeType库生成验证码图片时,我们输入的文本的属性pos位置和text_size大小是以像素点为单位的,但是将文本转化成字形时
# 需要把这些数据转换成1/64像素点单位计数的值,然后在画位图时,还要把相关的数据重新转化成像素点单位计数的值
# 这就是本class中几个方法主要做的工作
class PutChineseText(object):
def __init__(self, ttf):
# 创建一个face对象,装载一种字体文件.ttf
self._face = freetype.Face(ttf)
# 在一个图片(用三维数组表示)上绘制文本字符
def draw_text(self, image, pos, text, text_size, text_color):
"""
draw chinese(or not) text with ttf
:param image: 一个图片平面,用三维数组表示
:param pos: 在图片上开始绘制文本字符的位置,以像素点为单位
:param text: 文本的内容
:param text_size: 文本字符的字体大小,以像素点为单位
:param text_color:文本字符的字体颜色
:return: 返回一个绘制了文本的图片
"""
# self._face.set_char_size以物理点的单位长度指定了字符尺寸,这里只设置了宽度大小,则高度大小默认和宽度大小相等
# 我们将text_size乘以64倍得到字体的以point单位计数的大小,也就是说,我们认为输入的text_size是以像素点为单位来计量字体大小
self._face.set_char_size(text_size * 64)
# metrics用来存储字形布局的一些参数,如ascender,descender等
metrics = self._face.size
# 从基线到放置轮廓点最高(上)的距离,除以64是重新化成像素点单位的计数
# metrics中的度量26.6象素格式表示,即数值是64倍的像素数
# 这里我们取的ascender重新化成像素点单位的计数
ascender = metrics.ascender / 64.0
# 令ypos为从基线到放置轮廓点最高(上)的距离
ypos = int(ascender)
# 如果文本不是unicode格式,则用utf-8编码来解码,返回解码后的字符串
if isinstance(text, str) is False:
text = text.decode('utf-8')
# 调用draw_string方法来在图片上绘制文本,也就是说draw_text方法其实主要是在定位字形位置和设定字形的大小,然后调用draw_string方法来在图片上绘制文本
img = self.draw_string(image, pos[0], pos[1] + ypos, text, text_color)
return img
# 绘制字符串方法
def draw_string(self, img, x_pos, y_pos, text, color):
"""
draw string
:param x_pos: 文本在图片上开始的x轴位置,以1/64像素点为单位
:param y_pos: 文本在图片上开始的y轴位置,以1/64像素点为单位
:param text: unicode形式编码的文本内容
:param color: 文本的颜色
:return: 返回一个绘制了文本字形的图片(三维数组形式)
"""
prev_char = 0
# pen是笔位置或叫原点,用来定位字形
pen = freetype.Vector()
# 设定pen的x轴位置和y轴位置,注意pen.x和pen.y都是以1/64像素点单位计数的,而x_pos和y_pos都是以像素点为单位计数的
# 因此x_pos和y_pos都左移6位即乘以64倍化成1/64像素点单位计数
pen.x = x_pos << 6
pen.y = y_pos << 6
hscale = 1.0
# 设置一个仿射矩阵
matrix = freetype.Matrix(int(hscale) * 0x10000, int(0.2 * 0x10000), int(0.0 * 0x10000), int(1.1 * 0x10000))
cur_pen = freetype.Vector()
pen_translate = freetype.Vector()
# 将输入的img图片三维数组copy过来
image = copy.deepcopy(img)
# 一个字符一个字符地将其字形画成位图
for cur_char in text:
# 当字形图像被装载时,对该字形图像进行仿射变换,这只适用于可伸缩(矢量)字体格式。set_transform()函数就是做这个工作
self._face.set_transform(matrix, pen_translate)
# 装载文本中的每一个字符
self._face.load_char(cur_char)
# 获取两个字形的字距调整信息,注意获得的值是1/64像素点单位计数的。因此可以用来直接更新pen.x的值
kerning = self._face.get_kerning(prev_char, cur_char)
# 更新pen.x的位置
pen.x += kerning.x
# 创建一个字形槽,用来容纳一个字形
slot = self._face.glyph
# 字形图像转换成位图
bitmap = slot.bitmap
# cur_pen记录当前光标的笔位置
cur_pen.x = pen.x
# pen.x的位置上面已经更新过
# bitmap_top是字形原点(0,0)到字形位图最高像素之间的垂直距离,由于是像素点计数的,我们用其来更新cur_pen.y时要转换成1/64像素点单位计数
cur_pen.y = pen.y - slot.bitmap_top * 64
# 调用draw_ft_bitmap方法来画出字形对应的位图,注意这里是循环,也就是一个字符一个字符地画
self.draw_ft_bitmap(image, bitmap, cur_pen, color)
# 每画完一个字符,将pen.x更新成下一个字符的笔位置(原点位置),advanceX即相邻两个原点的水平距离(字间距)
pen.x += slot.advance.x
# prev_char更新成当前新画好的字符的字形的位置
prev_char = cur_char
# 返回包含所有字形的位图的图片(三维数组)
return image
# 将字形转化成位图
def draw_ft_bitmap(self, img, bitmap, pen, color):
"""
draw each char
:param bitmap: 要转换成位图的字形
:param pen: 开始画字形的位置,以1/64像素点为单位
:param color: RGB三个通道值表示,每个值0-255范围
:return: 返回一个三维数组形式的图片
"""
# 获得笔位置的x轴坐标和y轴坐标,这里右移6位是重新化为像素点单位计数的值
x_pos = pen.x >> 6
y_pos = pen.y >> 6
# rows即位图中的水平线数
# width即位图的水平象素数
cols = bitmap.width
rows = bitmap.rows
# buffer数一个指向位图象素缓冲的指针,里面存储了我们的字形在某个位置上的信息,即字形轮廓中的所有的点上哪些应该画成黑色,或者是白色
glyph_pixels = bitmap.buffer
# 循环画位图
for row in range(rows):
for col in range(cols):
# 如果当前位置属于字形的一部分而不是空白
if glyph_pixels[row * cols + col] != 0:
# 写入每个像素点的三通道的值
img[y_pos + row][x_pos + col][0] = color[0]
img[y_pos + row][x_pos + col][1] = color[1]
img[y_pos + row][x_pos + col][2] = color[2]
# 快速设置带字符串的图片的属性
class GenerateCharListImage(object):
# 初始化图片属性
def __init__(self):
# 候选字符集为数字0-9
self.number = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
# 令char_set为候选字符集
self.char_set = self.number
# 计算候选字符集的字符个数
self.len = len(self.char_set)
# 生成的不定长验证码最大长度
self.max_size = 4
self.ft = PutChineseText('fonts/OCR-B.ttf')
# 生成随机长度0-max_size之间的字符串,并返回字符串及对应的标签向量
def random_text(self):
# 空字符串
text = ''
# 空标签向量
text_vector = np.zeros((self.max_size * self.len))
# 设置字符串的长度是随机的
size = random.randint(1, self.max_size)
# size = self.max_size
# 逐个生成字符串和对应的标签向量
for index in range(size):
c = random.choice(self.char_set)
one_element_vector = self.one_char_to_one_element_vector(c)
# 更新字符串和标签向量
text = text + c
text_vector[index * self.len:(index + 1) * self.len] = np.copy(one_element_vector)
# 返回字符串及对应的标签向量
return text, text_vector
# 根据生成的字符串,生成验证码图片,返回图片数据和其标签,默认给图片添加高斯噪声
def generate_color_image(self, img_shape, noise):
text, text_vector = self.random_text()
# 创建一个图片背景,图片背景为黑色
img_background = np.zeros([img_shape[0], img_shape[1], 3])
# 设置图片背景为白色
img_background[:, :, 0], img_background[:, :, 1], img_background[:, :, 2] = 255, 255, 255
# (0, 0, 0)黑色,(255, 255, 255)白色,(255, 0, 0)深蓝色,(0, 255, 0)绿色,(0, 0, 255)红色
# 设置字体颜色为黑色
text_color = (0, 0, 0)
# 设置文本在图片上起始位置和文本大小,单位都是像素点
pos = (20, 10)
text_size = 20
# 画出验证码图片,返回的image是一个三维数组
image = self.ft.draw_text(img_background, pos, text, text_size, text_color)
# 如果想添加噪声
if noise == "gaussian":
# 添加20%的高斯噪声
image = self.image_add_gaussian_noise(image, 0.2)
elif noise == "salt":
# 添加20%的椒盐噪声
image = self.image_add_salt_noise(image, 0.1)
elif noise == "None":
pass
# 返回三维数组形式的彩色图片
return image, text, text_vector
# 给一张生成的图片加入随机椒盐噪声
def image_add_salt_noise(self, image, percent):
rows, cols, dims = image.shape
# 要添加椒盐噪声的像素点的数量,用全图像素点个数乘以一个百分比计算出来
salt_noise_num = int(percent * image.shape[0] * image.shape[1])
for i in range(salt_noise_num):
# 获得随机的一个x值和y值,代表一个像素点
x = np.random.randint(0, rows)
y = np.random.randint(0, cols)
# 所谓的椒盐噪声就是随机地将图像中的一定数量(这个数量就是椒盐的数量num)的像素值取极大或者极小
# 即让维度0第x个,维度1第y个确定的一个像素点的数组(这个数组有三个元素)的三个值都为0,即噪点是黑色,因为我们的图片背景是白色
image[x, y, :] = 0
return image
# 给一张生成的图片加入高斯噪声
def image_add_gaussian_noise(self, image, percent):
rows, cols, dims = image.shape
# 要添加的高斯噪点的像素点的数量,用全图像素点个数乘以一个百分比计算出来
gaussian_noise_num = int(percent * image.shape[0] * image.shape[1])
# 逐个给像素点添加噪声
for index in range(gaussian_noise_num):
# 随机挑一个像素点
x_temp, y_temp = np.random.randint(0, rows), np.random.randint(0, cols)
# 随机3个值,加到这个像素点的3个通道值上,为了不超过255,后面再用clamp函数限定其范围不超过255
value_temp = np.random.normal(0, 255, 3)
for subscript in range(3):
image[x_temp, y_temp, subscript] = image[x_temp, y_temp, subscript] - value_temp[subscript]
if image[x_temp, y_temp, subscript] > 255:
image[x_temp, y_temp, subscript] = 255
elif image[x_temp, y_temp, subscript] < 0:
image[x_temp, y_temp, subscript] = 0
return image
# 图片降噪函数
def image_reduce_noise(self, image):
# 使用方框滤波,normalize如果等于true就相当于均值滤波了,-1表示输出图像深度和输入图像一样,(2,2)是方框大小
image = cv2.boxFilter(image, -1, (2, 2), normalize=False)
return image
# 将彩色图像转换成灰度图片的一维数组形式的数据形式
def color_image_to_gray_image(self, image):
# 将图片转成灰度数据,并进行标准化(0-1之间)
r, g, b = image[:, :, 0], image[:, :, 1], image[:, :, 2]
gray = (0.2989 * r + 0.5870 * g + 0.1140 * b) / 255
# 生成灰度图片对应的一维数组数据,即输入模型的x数据形式
gray_image_array = np.array(gray).flatten()
# 返回度图片的一维数组的数据形式
return gray_image_array
# 单个字符转为向量
def one_char_to_one_element_vector(self, c):
one_element_vector = np.zeros([self.len, ])
# 找每个字符是字符集中的第几个字符,是第几个就把标签向量中第几个元素值置1
for index in range(self.len):
if self.char_set[index] == c:
one_element_vector[index] = 1
return one_element_vector
# 整个标签向量转为字符串
def text_vector_to_text(self, text_vector):
text = ''
text_vector_len = len(text_vector)
# 找标签向量中为1的元素值,找到后index即其下标,我们就知道那是候选字符集中的哪个字符
for index in range(text_vector_len):
if text_vector[index] == 1:
text = text + self.char_set[index % self.len]
# 返回字符串
return text
if __name__ == '__main__':
# 创建文件保存路径
if not os.path.exists("./image/"):
os.mkdir("./image/")
# 图片尺寸
image_shape = (40, 120)
test_object = GenerateCharListImage()
# 生成一个不加噪声的图片
test_color_image_no_noise, test_text_no_noise, test_text_vector_no_noise = test_object.generate_color_image(
image_shape, noise="None")
test_gray_image_array_no_noise = test_object.color_image_to_gray_image(test_color_image_no_noise)
print(test_gray_image_array_no_noise)
print(test_text_no_noise, test_text_vector_no_noise)
cv2.imwrite("./image/test_color_image_no_noise.jpg", test_color_image_no_noise)
# 显示这张不加噪声的图片
cv2.imshow("test_color_image_no_noise", test_color_image_no_noise)
# 2000毫秒后刷新图像
cv2.waitKey(2000)
# 生成一个加了高斯噪声的图片
test_color_image_gaussian_noise, test_text_gaussian_noise, test_text_vector_gaussian_noise = \
test_object.generate_color_image(image_shape, noise="gaussian")
cv2.imwrite("./image/test_color_image_gaussian_noise.jpg", test_color_image_gaussian_noise)
cv2.imshow("test_color_image_gaussian_noise", test_color_image_gaussian_noise)
# 2000毫秒后刷新图像
cv2.waitKey(2000)
# 高斯噪声图片降噪后的图片
test_color_image_reduce_gaussian_noise = test_object.image_reduce_noise(test_color_image_gaussian_noise)
cv2.imwrite("./image/test_color_image_reduce_gaussian_noise.jpg", test_color_image_reduce_gaussian_noise)
cv2.imshow("test_color_image_reduce_gaussian_noise", test_color_image_reduce_gaussian_noise)
# 2000毫秒后刷新图像
cv2.waitKey(2000)
# 生成一个加了椒盐噪声的图片
test_color_image_salt_noise, test_text_salt_noise, test_text_vector_salt_noise = test_object.generate_color_image(
image_shape, noise="salt")
cv2.imwrite("./image/test_color_image_salt_noise.jpg", test_color_image_salt_noise)
cv2.imshow("test_color_image_salt_noise", test_color_image_salt_noise)
# 2000毫秒后刷新图像
cv2.waitKey(2000)
# 椒盐噪声图片降噪后的图片
test_color_image_reduce_salt_noise = test_object.image_reduce_noise(test_color_image_salt_noise)
cv2.imwrite("./image/test_color_image_reduce_salt_noise.jpg", test_color_image_reduce_salt_noise)
cv2.imshow("test_color_image_reduce_salt_noise", test_color_image_reduce_salt_noise)
# 2000毫秒后刷新图像
cv2.waitKey(2000)
cv2.destroyAllWindows()运行结果如下:
[0.9999 0.9999 0.9999 ... 0.9999 0.9999 0.9999]
691 [0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 1. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
Process finished with exit code 0生成了5张不同的图片,具体可以注释上的说明:
