登录并爬取饿了么餐馆信息
使用了python的crawlerUtils三方库
https://github.com/Tyrone-Zhao/crawlerUtils
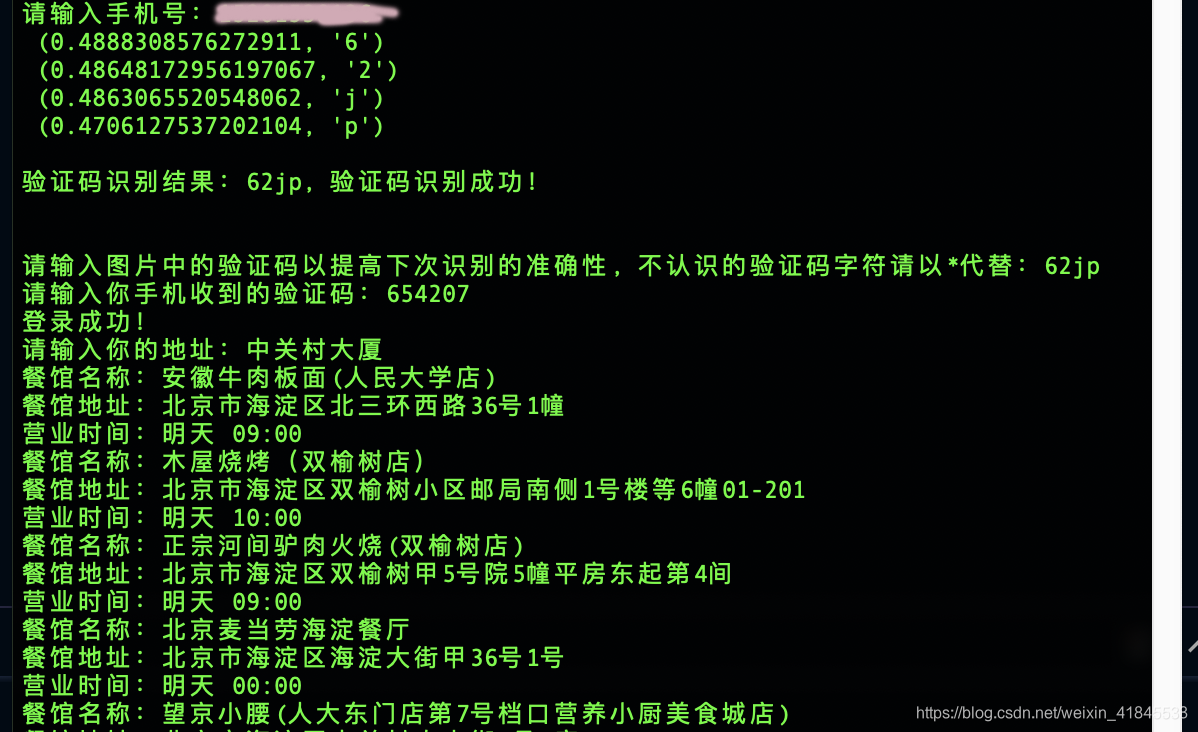
以下为等宽4字符验证码的识别案例
from crawlerUtils import Post
# 验证码的字符集合
CAPTCHA_SET = [
'0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'a',
'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm',
'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z'
]
# 根据验证码的字符集合创建验证码训练文件夹
Post.createTestSet(captcha_set=CAPTCHA_SET)
# 首先构造一个请求并获取验证码的函数,此函数必须返回验证码图片文件的路径和验证码文件的扩展名(如jpeg, 没有.)
def getCaptcha():
""" 获取验证码的函数必须至少返回filepath->验证码路径, 和extension->验证码图片扩展名如jpeg两个参数 """
captcha_params = {
验证码参数
}
captcha_url = 验证码url
captcha_json = Post(captcha_url, jsons=captcha_params).json
b64data = captcha_json['captcha_image']
filepath, extension = Post.base64decode(b64data)
return filepath, extension
# 进行验证码训练, 比如训练2次
Post.captchaTrain(getCaptcha, times=2)
# 识别验证码
captcha_code = Post.recognizeCaptcha(getCaptcha)
print(f"\n验证码识别结果:{captcha_code}, ", end="")