文章目录
1.JVM介绍
1.1 简介
- 软件层面的翻译(字节码翻译)
- 强大的内存管理机制(让使用者专注于写业务代码)
1.2 JVM内存区域分析
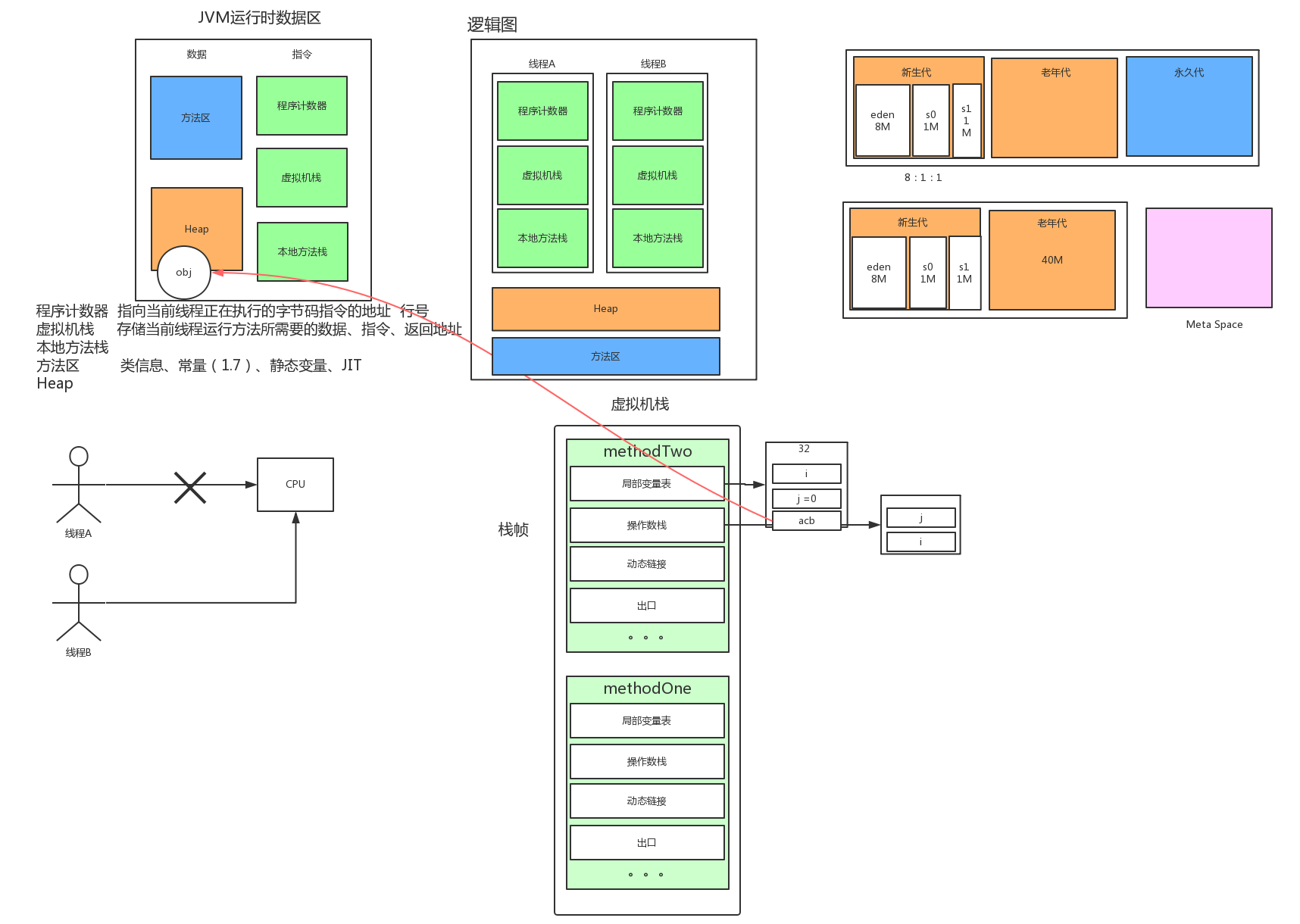
该图的颜色是一一对应的,要关联起来看
1.2.1 程序计数器
指向当前线程正在执行的字节码指令的地址,行号
1.一个程序多个线程再执行,那么资源可能会被抢占,这时候线程如果没有记录自己执行到哪一步的话,等资源空闲出来就找不到下一步该干嘛了
。
2.线程只知道做事情,但是做什么事情它不知道,所以它要去计数器里面取,看下一步做什么
1.2.2 虚拟机栈
1)存储当前线程运行方法所需要的数据、指令、返回地址(运行,要运行才有!!类运行的时候)
栈帧:最小的进进出出的单元,比如下面的methodOne就是一个栈帧
2)字节码反编译
javap -c -v HelloWorldDemo.class >p.txt
得到编译结果输出到p.txt,然后把txt的内容进行 JVM指令对照 查看底层是如何运行的
//局部变量
public void methodOne(int i){
int j=0;
int sum=i+j;
Object acb =obj;
long start = System.currentTimeMillis();
methodTwo();
return;
}
public void methodOne(int);
descriptor: (I)V
flags: ACC_PUBLIC
Code:
stack=2, locals=7, args_size=2
0: iconst_0 //将int类型常量0压入栈 [局部变量表] 就是类自己this
1: istore_2 //将int类型值存入局部变量2 [局部变量表] 就是局部变量j
2: iload_1 //从局部变量1中装载int类型值 [操作数栈] 就是变量i
3: iload_2 //从局部变量2中装载int类型值 [操作数栈] 就是变量j
4: iadd //操作数栈中执行i+j
5: istore_3 //将int类型值存入局部变量3 [局部变量表] 就是局部变量sum
6: aload_0 //加载引用类型 [局部变量表] 就是对象acb的引用地址 -》实际对象指向堆
7: getfield #4 // Field obj:Ljava/lang/Object;
10: astore 4
12: invokestatic #6 // Method java/lang/System.currentTimeMillis:()J
15: lstore 5
17: aload_0
18: invokespecial #7 // Method methodTwo:()V
21: return
LineNumberTable:
line 18: 0
line 19: 2
line 20: 6
line 21: 12
line 22: 17
line 23: 21
LocalVariableTable:
Start Length Slot Name Signature
0 22 0 this Lcom/jvm/HelloWorldDemo;
0 22 1 i I
2 20 2 j I
6 16 3 sum I
12 10 4 acb Ljava/lang/Object;
17 5 5 start J
Constant pool: //常量池 存储了方法,字段,类描述符等、所有类运行需要用到的东西引用
#1 = Methodref #3.#47 // java/lang/Object."<init>":()V
#2 = Fieldref #13.#48 // com/jvm/HelloWorldDemo.i:I
#3 = Class #49 // java/lang/Object
...
3)一个栈帧包含
局部变量表:定长的,32位;存储八大基本类型与引用类型地址
操作数栈:
动态链接:多态,指向真正的实例;当运行时要去解析,去常量池解析,找到一个正确的实例,然后运行这个方法
出口:返回地址,方法执行完之后要出栈 (正常return或者异常)
方法嵌套的时候,虚拟机栈中有多个栈帧?
1.2.3 本地方法栈
对比虚拟机栈,虚拟机栈存储的是java方法的一些进栈出栈,那么本地方法栈就是对本地方法的一些进栈出栈过程
1.2.4 方法区
类信息:存储类的版本号,字段,接口等描述
常量
静态变量
JIT:即时编译器编译后的代码等数据
为什么常量,静态变量要存储在方法区,不存在堆?
1.2.5 堆
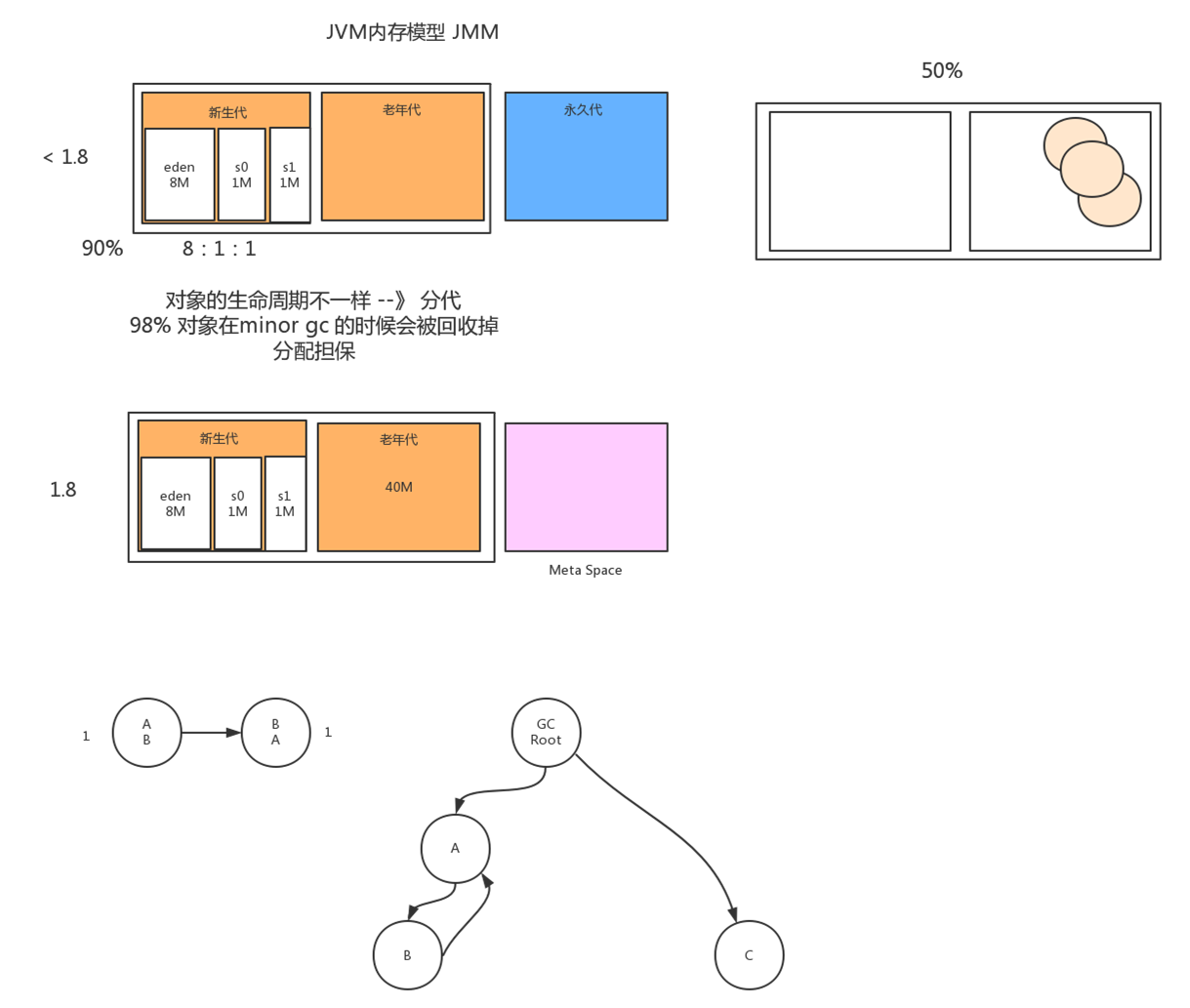
java的内存模型
1.8以前是分为新生代,老年代,永久代(在方法区里面)
1.8以后永久代换成Meta Space(不是在堆里面,是在一个直接内存里面直接分配的,类似ArrayList,会自动扩容!)
Meta Space的缺点:如果空间无限扩容,那么会挤掉原先的堆内存!所以要有管制
新生代
正常情况:一个对象在创建初期会在新生代的eden区分配,在gc的时候如果该对象没有被清除,那么会转移到s0区域,age++,当再次gc的时候,对象还在,那么会转移到s1区域,age++,再次gc的时候还在,那么转移到s0(在s0与s1中来回)一直到达age==15的时候,会转移到老年代
其他情况:大部分对象都活不过15岁,基本在新生代就被gc掉了,而jvm设计的目的就是让所有的对象能在新生代gc掉就gc掉,因为老年代的gc时间是新生代的10倍
异常情况:s1放满了怎么办?进老年代
问题
1.新生代的内存分配为什么是8:1:1?
因为二八定律加上上述的分析,只有20%的对象是使用最频繁的
2.为什么要分新生代,老年代?
因为对象的周期不一样
新生代与老年代
新生代与老年代内存比:1:2
新生代GC:Minor GC 在内存快满的时候会触发
老年代GC:Major GC
Full GC:Minor GC+Major GC
1.3 堆配置解析
参数解析地址:链接
1.3.1 基本配置
-Xms20M starting
堆起始内存
-Xmx max
堆最大内存
-Xmn new 堆的新生代内存
-XX: 不保证稳定性
Some Useful -XX Options
Default values are listed for Java SE 6 for Solaris Sparc with -server. Some options may vary per architecture/OS/JVM version. Platforms with a differing default value are listed in the description.
Boolean options are turned on with -XX:+<option> and turned off with -XX:-<option>.Disa
Numeric options are set with -XX:<option>=<number>. Numbers can include 'm' or 'M' for megabytes, 'k' or 'K' for kilobytes, and 'g' or 'G' for gigabytes (for example, 32k is the same as 32768).
String options are set with -XX:<option>=<string>, are usually used to specify a file, a path, or a list of commands
对象分配eden
,新生代8:1:1的配置
-XX:SurvivorRatio=8
查看我们的应用堆信息
# jps
11025 wwx
# jmap -heap 11025
Attaching to process ID 11025, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 24.71-b01
using thread-local object allocation.
Parallel GC with 2 thread(s)
Heap Configuration:
MinHeapFreeRatio = 0
MaxHeapFreeRatio = 100
MaxHeapSize = 419430400 (400.0MB)
NewSize = 268435456 (256.0MB)
MaxNewSize = 268435456 (256.0MB)
OldSize = 5439488 (5.1875MB)
NewRatio = 2
SurvivorRatio = 8
PermSize = 134217728 (128.0MB)
MaxPermSize = 268435456 (256.0MB)
G1HeapRegionSize = 0 (0.0MB)
Heap Usage:
PS Young Generation
Eden Space:
capacity = 237502464 (226.5MB)
used = 65793664 (62.7457275390625MB)
free = 171708800 (163.7542724609375MB)
27.702307964266005% used
From Space:
capacity = 15204352 (14.5MB)
used = 3014656 (2.875MB)
free = 12189696 (11.625MB)
19.82758620689655% used
To Space:
capacity = 14155776 (13.5MB)
used = 0 (0.0MB)
free = 14155776 (13.5MB)
0.0% used
PS Old Generation
capacity = 150994944 (144.0MB)
used = 53031216 (50.57450866699219MB)
free = 97963728 (93.42549133300781MB)
35.12118657430013% used
PS Perm Generation
capacity = 134217728 (128.0MB)
used = 64652952 (61.657859802246094MB)
free = 69564776 (66.3421401977539MB)
48.17020297050476% used
28347 interned Strings occupying 3311312 bytes.
1.3.2 其他配置
1)如果一个对象很大怎么办?
直接分配在老年代,参数配置超过3M直接进入老年代: -XX:PretenureSizeThreshold=3145728 3M
2)长期存活的对象
(年龄配置,超过15岁进入老年代)
-XX:MaxTenuringThreshold=15
3)动态对象年龄判定
(进入老年代条件)
相同年龄所有对象的大小总和 > Survivor空间的一半
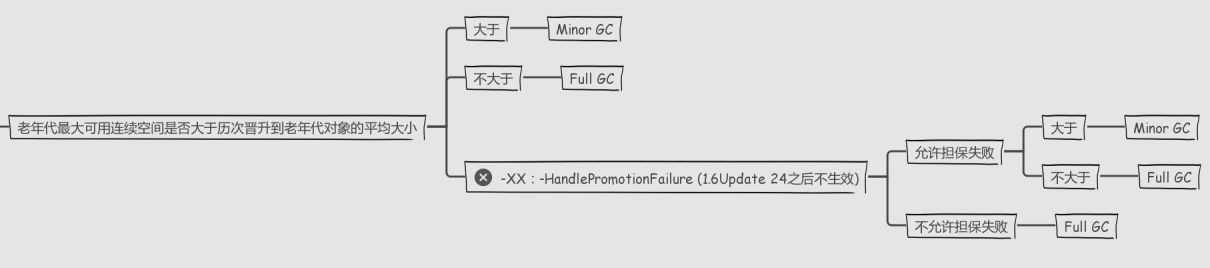
4)分配担保
Minor GC 之前检查 老年代最大可用连续空间是否>新生代所有对象总空间
大于:Minor GC
小于:如图
1.4 对象分配
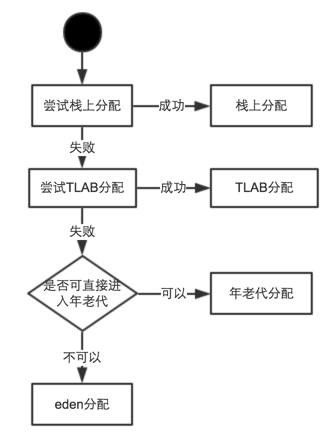
- 对于单线程来说我们可以在堆里面一个一个的分配内存,指针也慢慢往后移。
- 指针碰撞:但是实际上都是多线程的·情况,这时候如果多个线程同时在一个堆里面取竞争内存就会出现锁等待问题!
- 栈上分配:这时候出现每个线程各自划分一个区域分配内存,然后在同步到堆就会解决这个问题了(栈是每个线程独享的)
- TLAB:Thread Local Allaction Buffer,在eden区,每个线程都有一块自己的buffer,就不存在并发锁问题
- 空闲列表: FreeList,内存不规整,与TLAB不同的是,每块buffer不连续,位置随便放
2.垃圾回收
2.1 什么样的对象被GC
2.1.1 判断算法
1)引用计数法:判断对象没有被引用就回收掉
一般不使用,因为循环引用的情况旧回收不了
2)可达性分析 GC Roots
- 虚拟机栈中本地变量表引用的对象
- 方法区中:类静态变量引用的对象、常量引用的对象
- 本地方法栈中JNI引用的对象
2.1.2 引用
1)强 Object object = new Object();
该引用下会收是根据判断算法
2)软 缓存 在内存不足的时候下一次gc会被干掉,如果是强引用那么一直不会被回收
ConcurrentHashMap<?,?> cache = new ConcurrentHashMap<String,SoftReference<?>>();
3)弱 WeakReference 下一次gc就会被干掉
4)虚 类似弱引用
2.1.3 问题
1.为什么上面的那些区域对象是GC Roots?
因为在gc的时候,比如上面的例子methodOne在运行的时候,方法里面的变量都不能被回收,这就是原因,变量在栈帧里面跑的时候,不可能被回收,回收了还怎么搞 ==》没有在运行的区域会被回收:堆,方法区
2.不可达是不是就一定会被回收?
finalize() 挽回一次 ,建议什么场景下都不挽救
2.2 回收算法
2.2.1 算法
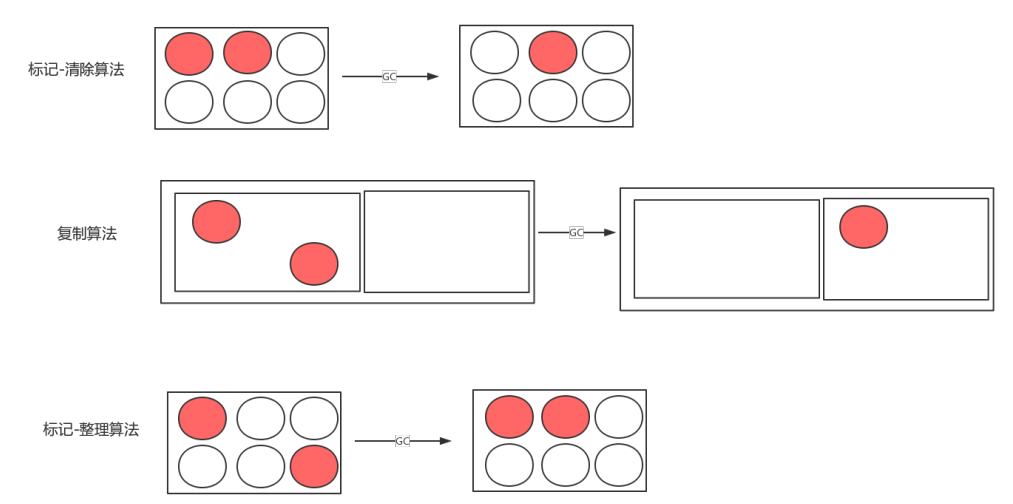
1)标记-清除算法
对象被使用了就标记一下,标记完之后清除能清除的对象
问题:效率不高、产生空间碎片
2)复制回收算法
新生代的算法,有两个空间,一个用一个不用,一个空间快满了之后,gc之后把还留存的对象copy到另外一个空间
优点:高效、不存在碎片问题
问题:利用率不高
3)标记-整理算法
与标记清除有点类似,该算法判断如果两个对象都存活的话会把对象整理到一端
优点:没有空间碎片
2.2.2 垃圾收集器
(算法的实现)
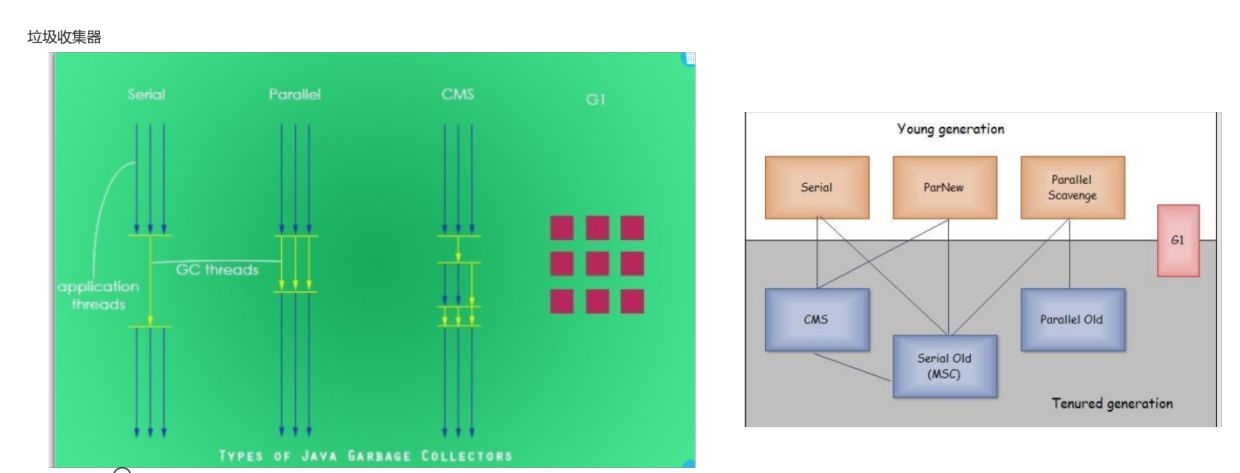
橙色是新生代
蓝色是老年代
G1是两代都有,有连线的可以搭配使用
STW Stop The World
1)Serial
单线程版
2)ParNew
Serial的多线程版(在cpu一核的情况下不一定效率高)
-XX:ParallelGCThreads
设置线程数量
3)Parallel Scavenge (全局)
与CMS的区别在哪里 --》吞吐量区别
吞吐量 = 运行用户代码时间 / (运行用户代码时间 + 垃圾收集时间)
#这两个参数配置吞吐量
-XX:MaxGCPauseMillis=n #垃圾回收时间尽量不超过
-XX:GCTimeRatio=n #垃圾收集时间占总时间的比率
-XX:UseAdaptiveSizePolicy #自动设置 动态调整 #GC Ergonomics 能效GC
4)Serial Old
CMS备用预案 Concurrent Mode Failusre时使用
标记-整理算法
5)Parallel Old
标记-整理算法
6)CMS
标记-清除算法
减少回收停顿时间
分母变小吞吐量变大:吞吐量 = 运行用户代码时间 / (运行用户代码时间 + 垃圾收集时间)
#无法处理浮动垃圾,配置以下参数
-XX:CMSInitiationgOccupancyFraction 碎片
Concurrent Mode Failure 启用Serial Old
#碎片
-XX:+UseCMSCompactAtFullCollection #在full gc的时候要不要开启压缩
-XX:CMSFullGCsBeforeCompaction #执行多少次不压缩FullGC后 来一次带压缩的 0 表示每次都压
-XX:+UseConcMarkSweep #显示使用CMS算法
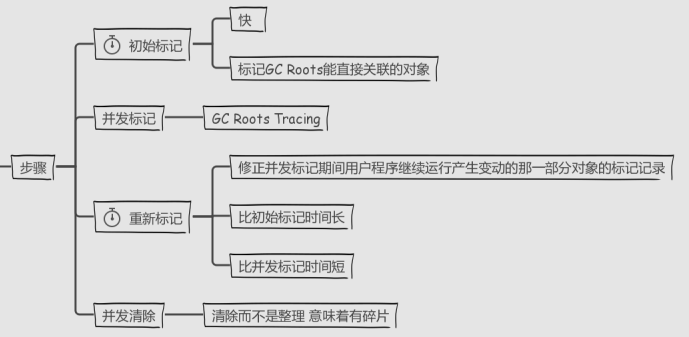
7)G1
- G1垃圾回收器适用于堆内存很大的情况,它将堆内存分割成不同的区域,并且并发的对其进行垃圾回收。
- G1也可以在回收内存之后对剩余的堆内存空间进行压缩。
- 并发扫描标记垃圾回收器在STW情况下压缩内存
- G1垃圾回收会优先选择第一块垃圾最多的区域
- 通过JVM参数 -XX:UseG1GC使用G1垃圾回收器
CMS与Parallel的不同?
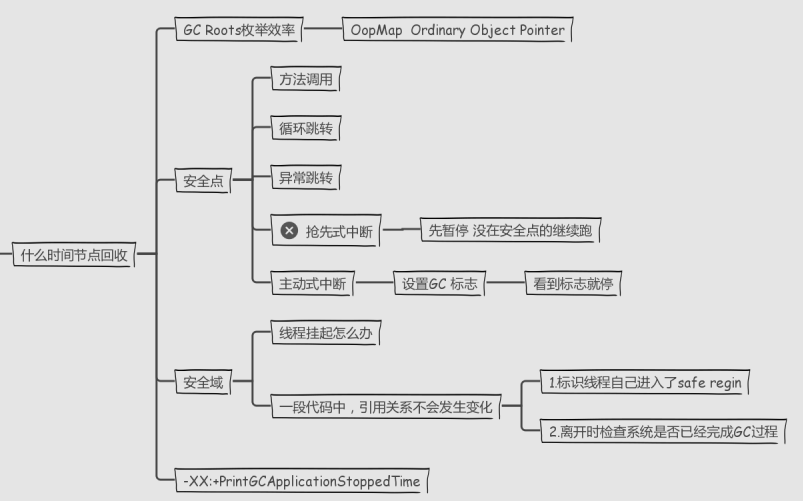
2.2.3 回收的时间节点
3.实践
3.1 模拟GC回收
java代码
private static List<int[]> bigObj = new ArrayList<>();
private static List<char[]> bigCharObj = new ArrayList<>();
public static int[] genetate1M(){return new int[524288];}
public static char[] genetate1MChar(){return new char[1048576];}
@RequestMapping(value = { "jvmError" })
public String jvmError() throws InterruptedException {
for(int i=0;i<100;i++){
if(i == 0){
Thread.sleep(500L);
System.out.println("start:"+new Date());
}else{
Thread.sleep(4000L);
}
bigObj.add(genetate1M());//该list一直有【大对象】生成,并且这些【大对象】有gc root指向,一直不会被回收,就会占满先占满eden,然后再占满old取,最后内存溢出
bigCharObj.add(genetate1MChar());
}
return "jvmError";
}
应用启动参数
#gc log
#内存溢出
#日志打印内容
#jsconsole连接配置
java -Xms128m -Xmx128m -verbose:gc -Xloggc:/usr/data/logs/jvmgc.log
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/usr/data/logs/error.hprof
-XX:+PrintGCApplicationStoppedTime -XX:+PrintGCTimeStamps -XX:+PrintCommandLineFlags
-XX:+PrintFlagsFinal -XX:+PrintGCDetails -XX:+UseCMSCompactAtFullCollection
-Dcom.sun.management.jmxremote.authenticate=false
-Dcom.sun.management.jmxremote.ssl=false
-Dcom.sun.management.jmxremote.port=9004
-Djava.rmi.server.hostname=192.168.98.165 -jar jvmdemo-0.0.1-SNAPSHOT.jar > catalina.out 2>&1 &
#使用CMS,CMS的GC会占用cpu
-XX:+UseConcMarkSweepGC
-XX:+CMSScavengeBeforeRemark
关闭java进程
jps#查看java进程
kill pid #不要用kill -9 ,jvm在关闭之前有一个钩子,优雅关闭
3.2 如何查看当前的垃圾回收器
-XX:+PrintFlagsFinal
-XX:+PrintCommandLineFlags
java -version查看(server client
)
MBean
(代码)
@RequestMapping(value = { "jvmInfo" })
public String jvmInfo() {
List<GarbageCollectorMXBean> l = ManagementFactory.getGarbageCollectorMXBeans();
StringBuffer sb = new StringBuffer();
for (GarbageCollectorMXBean b:l){
sb.append(b.getName()+"\n");
}
return sb.toString();
}
3.3 GC日志
1.输出日志
-XX:+PrintGCTimeStamps
-XX:+PrintGCDetails
-Xloggc:/home/administrator/james/gc.log
-XX:+PrintHeapAtGC
2.日志文件大小控制
-XX:-UseGCLogFileRotation
-XX:GCLogFileSize=8K
3.怎么看
#查看log
vi /usr/data/log/jvmgc.log
#gc的log,与下图做对比
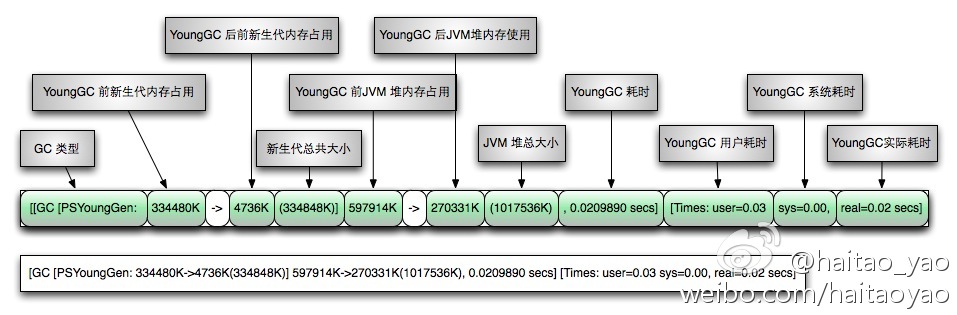
[GC (CMS Initial Mark) [1 CMS-initial-mark: 85587K(87424K)] 124423K(126720K), 0.0032560 secs] [Times: user=0.01 sys=0.00, real=0.00 secs]
GC解析图
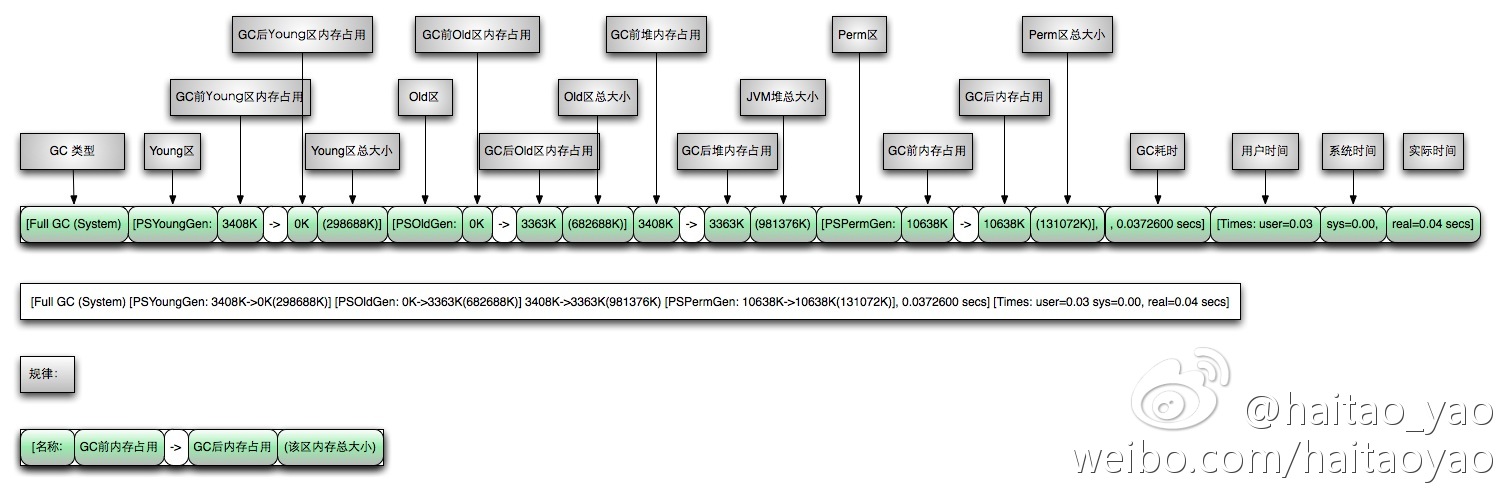
Full GC解析图
3.3 JDK自带的 监控工具
文档地址:链接
jmap -heap pid 查看jvm堆使用情况
jstat -gcutil pid 1000 查看jvm的状态
jstack 线程dump
链接
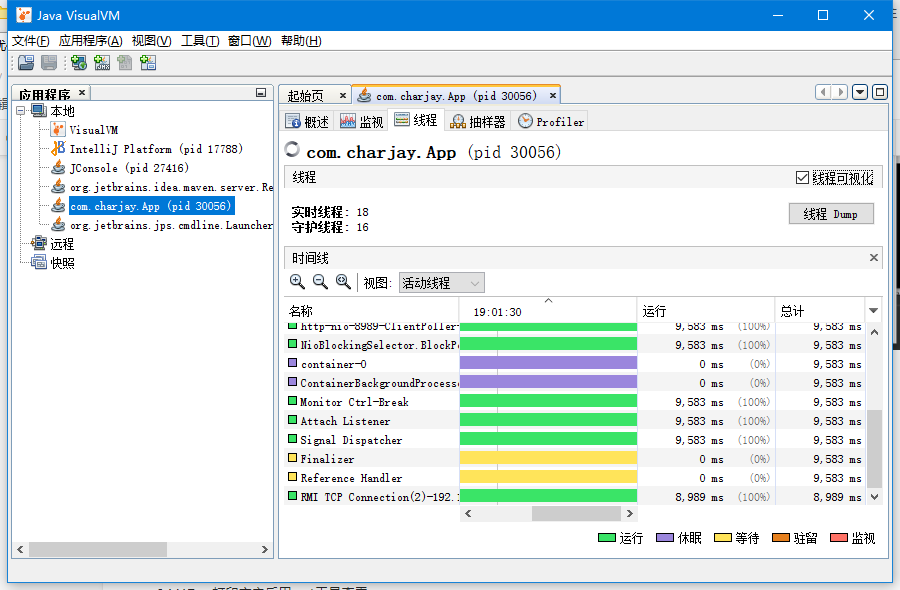
jvisualvm
(可以查看线程死锁,jvm等信息)
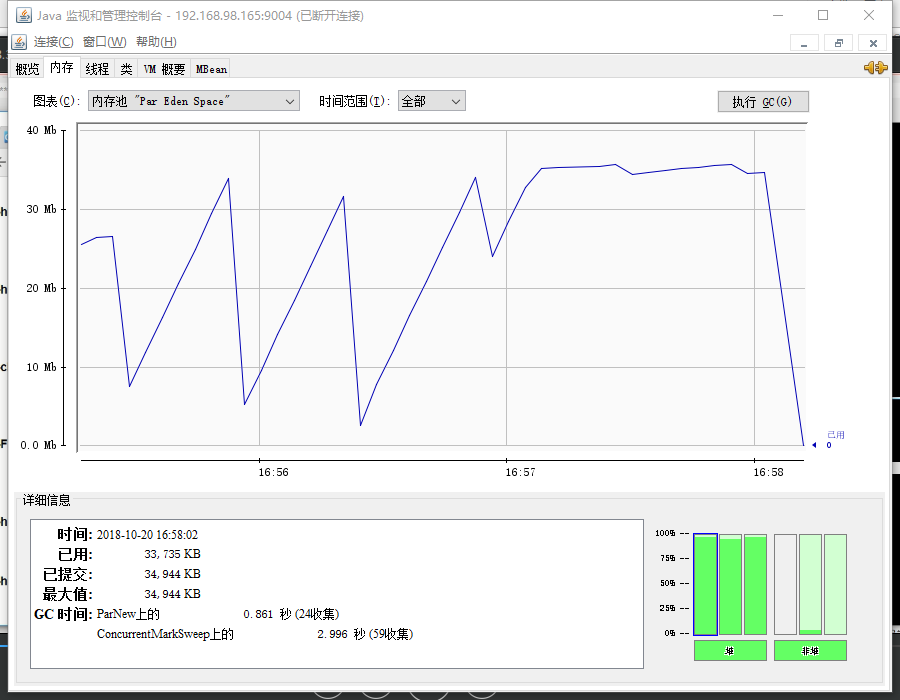
jconsole 远程连接,监控jvm 链接
MAT(Eclipse Memory Analyzer 内存分析工具)
文档:链接
#当出现内存溢出的时候查看日志
-XX:+HeapDumpOnOutOfMemoryError - XX:HeapDumpPath=/usr/data/logs/error.hprof
该工具会具体分析到哪个类出了问题,分析内存中哪种类型的对象溢出了
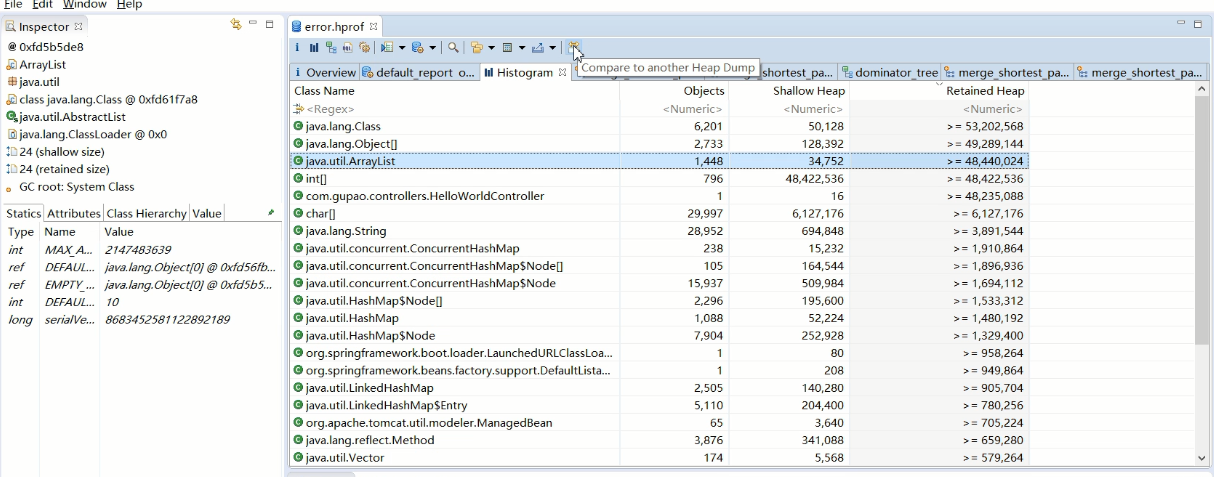
3.4 如何定位内存溢出的位置?
1.看GC日志 :126719K->126719K(126720K) 回收前与回收后的一直一样,或者回收后变大--》内存泄露 2.dump :如果真的内存泄露了,打印dump 3.MAT :打印完之后用mat工具查看 1.占用Retained Heap 2.查看最大的Histogram 对象类型 3.有件看有没有GC Root指向,如果有定位gc root对象,没有继续看下一个3.5 什么条件触发STW的Full GC呢?
Perm空间不足;
CMS GC时出现promotion failed和concurrent mode failure(concurrent mode failure发生的原因一般是CMS正在进行,但是由于老年代空间不足,需要尽快回收老年代里面的不再被使用的对象,这时停止所有的线程,同时终止CMS,直接进行Serial Old GC);
(promontion faild产生的原因是EDEN空间不足的情况下将EDEN与From survivor中的存活对象存入To survivor区时,To survivor区的空间不足,再次晋升到old gen区,而old gen区内存也不够的情况下产生了promontion faild从而导致full gc )
统计得到的Young GC晋升到老年代的平均大小大于老年代的剩余空间;
主动触发Full GC(执行jmap -histo:live [pid])来避免碎片问题。
3.6 GC优化案例
查看参考的第一条