用户所处的上下文(context)包括用户访问推荐系统的时间、地点、心情等,对于提高推荐系统的推荐系统是非常重要的。
关于上下文推荐的研究,可以参考Alexander Tuzhilin教授(个人主页为http://people.stern.nyu.edu/atuzhili/)的一篇综述“Context Aware Recommender Systems”
5.1 时间上下文信息
5.1.1 时间效应简介
一般认为,时间信息对用户兴趣的影响表现在以下几个方面。
用户兴趣是变化的,如果我们要准确预测用户现在的兴趣,就应该关注用户最近的行为,因为用户最近的行为最能体现他现在的兴趣。
物品也是有生命周期的,当我们决定在某个时刻给某个用户推荐某个物品时,需要考虑该物品在该时刻是否已经过时了。不同系统的物品具有不同的生命周期。
季节效应,季节效应主要反映了时间本身对用户兴趣的影响。
5.1.2 时间效应举例
 标号为①的曲线对应facebook,标号为②的曲线对应myspace,标号为③的曲线对应twitter。
标号为①的曲线对应facebook,标号为②的曲线对应myspace,标号为③的曲线对应twitter。
 标号为①的曲线对应iphone,标号为②的曲线对应samsung,标号为③的曲线对应nokia。
标号为①的曲线对应iphone,标号为②的曲线对应samsung,标号为③的曲线对应nokia。
 标号为①的曲线对应coffee(咖啡),标号为②的曲线对应chocolate(巧克力),标号为③的曲线对应soup(汤),标号为④的曲线对应ice cream(冰淇淋)
标号为①的曲线对应coffee(咖啡),标号为②的曲线对应chocolate(巧克力),标号为③的曲线对应soup(汤),标号为④的曲线对应ice cream(冰淇淋)
5.1.3 系统时间特性的分析
包含时间信息的用户行为数据集由一系列三元组构成,其中每个三元组(u,i,t)代表了用户u在时刻t对物品i产生过行为。在给定数据集后,本节通过统计如下信息研究系统的时间特性。
数据集每天独立用户数的增长情况
系统的物品变化情况
用户访问情况:可以统计用户的平均活跃天数,同时也可以统计相隔T天来系统的用户的重合度。
1. 数据集的选择
将利用Delicious数据集进行离线实验以评测不同算法的预测精度。该数据集包含950 000个用户在2003年9月到2007年12月间对网页打标签的行为。该数据集中包含132 000 000个标签和420 000 000条标签行为记录。因为网页由URL标识,因此可以根据域名将网页分成不同的类别。本节选取了5个域名对应的网页,将整个数据集分成5个不同的数据集加以研究。

2. 物品的生存周期和系统的时效性
不同类型网站的物品具有不同的生命周期,我们可以用如下指标度量网站中物品的生命周期。
(1)物品平均在线天数:如果一个物品在某天被至少一个用户产生过行为,就定义该物品在这一天在线。因此,我们可以通过物品的平均在线天数度量一类物品的生存周期。考虑到物品的平均在线天数和物品的流行度应该成正比,因此给定一个数据集,我们首先将物品按照流行度分成20份,然后计算每一类物品的平均在线天数。

(2)相隔T天系统物品流行度向量的平均相似度:取系统中相邻T天的两天,分别计算这两天的物品流行度,从而得到两个流行度向量。然后,计算这两个向量的余弦相似度,如果相似度大,说明系统的物品在相隔T天的时间内没有发生大的变化,从而说明系统的时效性不强,物品的平均在线时间较长。相反,如果相似度很小,说明系统中的物品在相隔T天的时间内发生了很大变化,从而说明系统的时效性很强,物品的平均在线时间很短。

5.1.4 推荐系统的实时性
用户兴趣是不断变化的,其变化体现在用户不断增加的新行为中。一个实时的推荐系统需要能够实时响应用户新的行为,让推荐列表不断变化,从而满足用户不断变化的兴趣。
实现推荐系统的实时性除了对用户行为的存取有实时性要求,还要求推荐算法本身具有实时性,而推荐算法本身的实时性意味着:
实时推荐系统不能每天都给所有用户离线计算推荐结果,然后在线展示昨天计算出来的结果。所以,要求在每个用户访问推荐系统时,都根据用户这个时间点前的行为实时计算推荐列表。
推荐算法需要平衡考虑用户的近期行为和长期行为,即要让推荐列表反应出用户近期行为所体现的兴趣变化,又不能让推荐列表完全受用户近期行为的影响,要保证推荐列表对用户兴趣预测的延续性。
5.1.5 推荐算法的时间多样性
推荐系统每天推荐结果的变化程度被定义为推荐系统的时间多样性。时间多样性高的推荐系统中用户会经常看到不同的推荐结果。
为了研究推荐系统的时间多样性和用户满意度之间是否存在关系,设计了3种推荐系统。
A 给用户推荐最热门的10部电影。
B 从最热门的100部电影中推荐10部给用户,但保证了时间多样性,每周都有7部电影推荐结果不在上周的推荐列表中。
C 每次都从所有电影中随机挑选10部推荐给用户。
结果发现:
(1)A、B算法的平均分明显高于C算法。这说明纯粹的随机推荐虽然具有最高的时间多样性,但不能保证推荐的精度。
(2)A算法的平均分随时间逐渐下降,而B算法的平均分随时间基本保持不变。这说明A算法因为没有时间多样性,从而造成用户满意度不断下降,从而也说明了保证时间多样性的重要性。
提高推荐结果的时间多样性需要分两步解决:首先,需要保证推荐系统能够在用户有了新的行为后及时调整推荐结果,使推荐结果满足用户最近的兴趣;其次,需要保证推荐系统在用户没有新的行为时也能够经常变化一下结果,具有一定的时间多样性。
如果用户没有行为,如何保证给用户的推荐结果具有一定的时间多样性呢?一般的思路有以下几种。
(1)在生成推荐结果时加入一定的随机性。
(2)记录用户每天看到的推荐结果,然后在每天给用户进行推荐时,对他前几天看到过很多次的推荐结果进行适当地降权。
(3)每天给用户使用不同的推荐算法。
5.1.6 时间上下文推荐算法
1. 最近最热门
在获得用户行为的时间信息后,最简单的非个性化推荐算法就是给用户推荐最近最热门的物品了。给定时间T,物品i最近的流行度可以定义为:
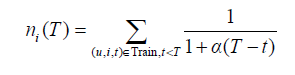 ,α是时间衰减参数。
,α是时间衰减参数。
2. 时间上下文相关的ItemCF算法
基于物品(item-based)的个性化推荐算法由两个核心部分构成:
(1)利用用户行为离线计算物品之间的相似度;
(2)根据用户的历史行为和物品相似度矩阵,给用户做在线个性化推荐。
时间信息在上面两个核心部分中都有重要的应用,这体现在两种时间效应上。
(1)物品相似度:用户在相隔很短的时间内喜欢的物品具有更高相似度。:
(2)在线推荐:用户近期行为相比用户很久之前的行为,更能体现用户现在的兴趣。因此在预测用户现在的兴趣时,应该加重用户近期行为的权重,优先给用户推荐那些和他近期喜欢的物品相似的物品。
基于物品的协同过滤算法,它通过如下公式计算物品的相似度:
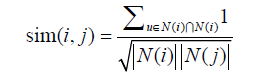
在得到时间信息(用户对物品产生行为的时间)后,我们可以通过如下公式改进相似度计算:
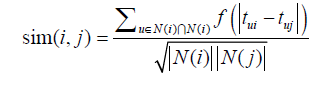 ,其中衰减函数
,其中衰减函数
α是时间衰减参数,它的取值在不同系统中不同。如果一个系统用户兴趣变化很快,就应该取比较大的α,反之需要取比较小的α。
而在给用户u做推荐时,用户u对物品i的兴趣p(u,i)通过如下公式计算:

一般来说,用户现在的行为应该和用户最近的行为关系更大。因此,我们可以通过如下方式修正预测公式:

是当前时间。
是时间衰减参数,需要根据不同的数据集选择合适的值。
3. 时间上下文相关的UserCF算法
可以在以下两个方面利用时间信息改进UserCF算法。
(1)用户兴趣相似度:如果两个用户同时喜欢相同的物品,那么这两个用户应该有更大的兴趣相似度。
(2)相似兴趣用户的最近行为:在找到和当前用户u兴趣相似的一组用户后,这组用户最近的兴趣显然相比这组用户很久之前的兴趣更加接近用户u今天的兴趣。也就是说,我们应该给用户推荐和他兴趣相似的用户最近喜欢的物品。
UserCF通过如下公式计算用户u和用户v的兴趣相似度:
 ,N(u)是用户u喜欢的物品集合,N(v)是用户v喜欢的物品集合。
,N(u)是用户u喜欢的物品集合,N(v)是用户v喜欢的物品集合。
可以利用如下方式考虑时间信息:
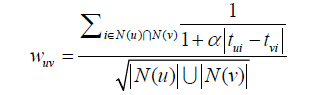 ,用户u和用户v对物品i产生行为的时间越远,那么这两个用户的兴趣相似度就会越小。
,用户u和用户v对物品i产生行为的时间越远,那么这两个用户的兴趣相似度就会越小。
在得到用户相似度后,UserCF通过如下公式预测用户对物品的兴趣:

如果考虑和用户u兴趣相似用户的最近兴趣,我们可以设计如下公式:

5.1.7 时间段图模型
时间段图模型也是一个二分图。U是用户节点集合,
是用户时间段节点集合。一个用户时间段节点
会和用户u在时刻t喜欢的物品通过边相连。I是物品节点集合,
是物品时间段节点集合。一个物品时间段节点
会和所有在时刻t喜欢物品i的用户通过边相连。E是边集合,它包含了3种边:(1)如果用户u对物品i有行为,那么存在边
;(2)如果用户u在t时刻对物品i有行为,那么就存在两条边
。w(e)定义了边的权重,
定义了顶点的权重。
 ,(A,b,2)表示用户A在时刻2对物品b有行为。
,(A,b,2)表示用户A在时刻2对物品b有行为。
定义完图的结构后,最简单的想法是可以利用前面提到的PersonalRank算法给用户进行个性化推荐。但是因为这个算法需要在全图上进行迭代计算,所以时间复杂度比较高。因此我们提出了一种称为路径融合算法的方法,通过该算法来度量图上两个顶点的相关性。
一般来说,图上两个相关性比较高的顶点一般具有如下特征:
两个顶点之间有很多路径相连;
两个顶点之间的路径比较短;
两个顶点之间的路径不经过出度比较大的顶点。
路径融合算法首先提取出两个顶点之间长度小于一个阈值的所有路径,然后根据每条路径经过的顶点给每条路径赋予一定的权重,最后将两个顶点之间所有路径的权重之和作为两个顶点的相关度。
假设是连接顶点
和
的一条路径,这条路径的权重
取决于这条路径经过的所有顶点和边:

这里out(v)是顶点v指向的顶点集合,|out(v)|是顶点v的出度, 定义了顶点的权重,
定义了边
的权重。上面的定义符合上面3条原则的后两条。首先,因为
,所以路径越长n越大,
就越小。同时,如果路径经过了出度大的顶点v',那么因为|out(v')|比较大,所以
也会比较小。
在定义了一条路径的权重后,就可以定义顶点之间的相关度。对于顶点v和v',令p(v,v',K)为这两个顶点间距离小于K的所有路径,那么这两个顶点之间的相关度可以定义为:
![]()
对于时间段图模型,所有边的权重都定义为1,而顶点的权重定义如下:
 ,
,是两个参数,控制了不同顶点的权重。
5.1.8 离线实验
1. 实验设置
在得到由(用户、物品、时间)三元组组成的数据集后,我们可以通过如下方式生成训练集和测试集。对每一个用户,将物品按照该用户对物品的行为时间从早到晚排序,然后将用户最后一个产生行为的物品作为测试集,并将这之前的用户对物品的行为记录作为训练集。推荐算法将根据训练集学习用户兴趣模型,给每个用户推荐N个物品,并且利用准确率和召回率评测推荐算法的精度。将选取不同的N(10,20,…,100)进行10次实验,并画出最终的准确率和召回率曲线,通过该曲线来比较不同算法的性能。
 ,R(u,N)是推荐算法给用户u提供的长度为N的推荐列表,T(u)是测试集中用户喜欢的物品集合。
,R(u,N)是推荐算法给用户u提供的长度为N的推荐列表,T(u)是测试集中用户喜欢的物品集合。
离线实验将同时对比如下算法,将它们的召回率和准确率曲线画在一张图上。
Pop 给用户推荐当天最热门的物品。
TItemCF 融合时间信息的ItemCF算法。
TUserCF 融合时间信息的UserCF算法。
ItemCF 不考虑时间信息的ItemCF算法。
UserCF 不考虑时间信息的UserCF算法。
SGM 时间段图模型。
USGM 物品时间节点权重为0的时间段图模型。
ISGM 用户时间节点权重为0的时间段图模型。





这些曲线的形状将数据集分成了两类。一类是BlogSpot、YouTube、NYTimes,另一类是Wikipedia和SourceForge。在第一类数据集中,有4个算法(SGM、ISGM、TUserCF、Pop)明显好于另外4个算法,而在第二类数据集中,不同算法的召回率和准确率曲线交织在一起,并不能明显分开。而且,在第一类数据集中,即使是非个性化推荐算法Pop也优于很多个性化推荐算法(TItemCF、USGM)。这主要是因为第一类数据集的时效性很强,因此用户兴趣的个性化不是特别明显,每天最热门的物品已经吸引了绝大多数用户的眼球,而长尾中的物品很少得到用户的关注。
5.2 地点上下文信息
不同地区的用户兴趣有所不同,用户到了不同的地方,兴趣也会有所不同。
基于位置的推荐算法
明尼苏达大学的研究人员提出过一个称为LARS(Location Aware Recommender System,位置感知推荐系统)的和用户地点相关的推荐系统(https://ieeexplore.ieee.org/document/6228105)。该系统首先将物品分成两类,一类是有空间属性的,比如餐馆、商店、旅游景点等,另一类是无空间属性的物品,比如图书和电影等。同时,它将用户也分成两类,一类是有空间属性的,比如给出了用户现在的地址(国家、城市、邮编等),另一类用户并没有相关的空间属性信息。它使用的数据集有3种不同的形式。
(1)(用户,用户位置,物品,评分),每一条记录代表了某一个地点的用户对物品的评分。
(2)(用户,物品,物品位置,评分),每一条记录代表了用户对某个地方的物品的评分。
(3)(用户,用户位置,物品,物品位置,评分),每一条记录代表了某个位置的用户对某个位置的物品的评分。
LARS通过研究前两种数据集,发现了用户兴趣和地点相关的两种特征。
(1)兴趣本地化:不同地方的用户兴趣存在着很大的差别。不同国家和地区用户的兴趣存在着一定的差异性。
(2)活动本地化:一个用户往往在附近的地区活动。
对于第一种数据集,LARS的基本思想是将数据集根据用户的位置划分成很多子集。因为位置信息是一个树状结构,比如国家、省、市、县的结构。因此,数据集也会划分成一个树状结构。我们可以从根节点出发,在到叶子节点的过程中,利用每个中间节点上的数据训练出一个推荐模型,然后给用户生成推荐列表。而最终的推荐结果是这一系列推荐列表的加权。这种算法称为金字塔模型,而金字塔的深度影响了推荐系统的性能,因而深度是这个算法的一个重要指标。下文用LARS-U代表该算法。
对于第二种数据集,每条用户行为表示为四元组(用户、物品、物品位置、评分),表示了用户对某个位置的物品给了某种评分。对于这种数据集,LARS会首先忽略物品的位置信息,利用ItemCF算法计算用户u对物品i的兴趣P(u,i),但最终物品i在用户u的推荐列表中的权重定义为:
![]()
TravelPenalty(u,i)表示了物品i的位置对用户u的代价。计算TravelPenalty(u,i)的基本思想是对于物品i与用户u之前评分的所有物品的位置计算距离的平均值(或者最小值)。该中算法称为LARS-T算法。
考虑TravelPenality确实能够提高TopN推荐的离线准确率,LARS-T算法明显优于ItemCF算法。
选择合适的深度对LARS-U算法很重要,不过在绝大多数深度的选择下,LARS-U算法在两个数据集上都优于普通的ItemCF算法。
5.3 扩展阅读
“collaborative filtering with temporal dynamics”,该文系统地总结了各种使用时间信息的方式,包括考虑用户近期行为的影响,考虑时间的周期性等。http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.379.1951&rep=rep1&type=pdf
“Temporal Diversity in Recommender Systems”一文中深入分析了时间多样性对推荐系统的影响。http://www0.cs.ucl.ac.uk/staff/l.capra/publications/lathia_sigir10.pdf
“Evaluating Collaborative Filtering Over Time”论述了各种不同推荐算法是如何随时间演化的。http://ntp-0.cs.ucl.ac.uk/staff/n.lathia/thesis/lathia_thesis.pdf
如果要系统地研究与上下文推荐相关的工作,可以参考Alexander Tuzhili教授的工作(http://pages.stern.nyu.edu/~atuzhili/)。