本篇文章主要为之后的支持向量机打下数学基础
一、拉格朗日乘子法的目的
拉格朗日乘子法将原始的约束问题转换成求解无约束优化问题。
对形如:
通过拉格朗日乘子法转化成:
通俗地说就是转换目标函数,把约束条件去掉。
二、等式约束条件下的拉格朗日乘子法
在约束条件是等式的情况下,引用深入理解拉格朗日乘子法(Lagrange Multiplier) 和KKT条件对拉格朗日乘子法的直观理解。
设想我们的目标函数,
取不同的值,相当于投影在
构成的平面(曲面)上,即成为等高线。如下图所示,目标函数是
,这里
,在
与等高线相交,这里的交点就是既满足了等式约束条件和目标函数可行域的值,但一定不是最优值。因为相交就意味着还存在其他的等高线在该条等高线的内部或外部,使得新的等交线与目标函数的交点的值更大或者更小。只有等高线与目标函数的曲线相切的时候,可能取得最优值,如下图所示,即等高线和目标函数得曲线在该点得法向量必须有相同得方向
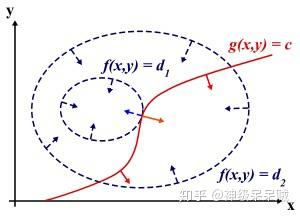
有上面的理解,设最优点 ,则有
使得:
在约束条件是等式的情况下,定义拉格朗日函数:
观察(2)式可以发现对 的偏导数并置零,得到(1)式。因此可以将有等式约束的优化问题,通过(2)式改写成无约束优化问题。
三、不等式约束下的KKT条件
现在考虑含有不等式约束的优化条件。
当不等式约束 ,此时的最优点
要么在
区域内,要么在
上。对于
的情形下,约束条件不起作用,此时是一个无约束的优化问题,可以直接通过
来获取最优点。对于
的情况下,这就相当于一个等式约束,但此时的
方向与
的方向相反,否则将会突破
的约束。即存在
使得
。所以在
情况下,考虑之前提到的两种情况,推导出拉格朗日函数的KKT条件:
四、对偶问题
在满足KKT的条件下后,通过求解对偶问题来替代求解的原问题,这样可以避免求解复杂的原问题。
在这种情况下,将目标函数,等式约束,不等式约束写成一个方程式,若有 个等式约束和
个不等式约束,则定义拉格朗日函数:
回顾目标函数,需要 ,由拉格朗日函数,在KKT条件下,
就是
这是因为,在KKT条件下,在
,
时。观察(3)式,此时
等价于
。
因此在满足约束条件的情况下,原问题的最优值 :
则对偶问题的最优值 :
形式上观察,原问题先固定 ,优化参数
,再优化出
,而对偶问题则是先固定
,优化参数
,再优化出
。
分别求出原始问题的最优值 和对偶问题的最优值
后,二者间的关系有:
证明:


又因为原始问题与对偶问题都有最优值:

所以
因此,对偶问题相当于给出了原问题一个下界。这个下界就确定了 的值。在满足KKT的条件下,
,这就说明求解对偶问题就相当于求解了原问题。
这里说明以下,对原始问题和对偶问题,设 和
都是凸函数,
使仿射函数(一阶多项式),不等式约束
严格可行的,即存在
对所有
成立。则原问题和对偶问题最优解的充分必要条件是:
首先,前三个约束条件保证了原问题存在鞍点。而求解原问题的最优值就是通过求解这些鞍点得到,但是函数的鞍点可能会有很多个,而最优值是在这些中的某个鞍点。在KKT约束条件下,相当于在这些鞍点中施加约束,最终能得到一个全局最优值。
参考文献:
1.支持向量机通俗导论(理解SVM的三层境界) - Mac Track - CSDN博客
3.深入理解拉格朗日乘子法(Lagrange Multiplier) 和KKT条件
4.周志华. 机器学习[M]. 清华大学出版社, 2016