1. 任务
使用网格搜索对模型进行调优并采用五折交叉验证的方式进行模型评估
2. 网格搜索
2.1 什么是Grid Search 网格搜索?
网格搜索是一种调参手段;在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终的结果。其原理就像是在数组里找最大值。(为什么叫网格搜索?以有两个参数的模型为例,参数a有3种可能,参数b有4种可能,把所有可能性列出来,可以表示成一个3*4的表格,其中每个cell就是一个网格,循环过程就像是在每个网格里遍历、搜索,所以叫grid search)
2.2 Simple Grid Search:简单的网格搜索
原始数据集划分成训练集和测试集以后,其中测试集除了用作调整参数,也用来测量模型的好坏
缺点:导致最终的评分结果比实际效果要好。(因为测试集在调参过程中,送到了模型里,而我们的目的是将训练模型应用在unseen data上)
解决方法:对训练集再进行一次划分,分成训练集和验证集,这样划分的结果就是:原始数据划分为3份,分别为:训练集、验证集和测试集;其中训练集用来模型训练,验证集用来调整参数,而测试集用来衡量模型表现好坏。然而,这种简单的grid search方法,其最终的表现好坏与初始数据的划分结果有很大的关系,为了处理这种情况,我们采用交叉验证的方式来减少偶然性。
2.3 实现代码(使用SVM模型)
#!/usr/bin/env python 3.6
#-*- coding:utf-8 -*-
# @File : GridSearch.py
# @Date : 2018-11-23
# @Author : 黑桃
# @Software: PyCharm
import pickle
from sklearn.svm import SVC
path = "E:/MyPython/Machine_learning_GoGoGo/"
"""=====================================================================================================================
1 读取数据
"""
print("0 读取特征")
f = open(path + 'feature/feature_V3.pkl', 'rb')
X_train,X_test,y_train,y_test = pickle.load(f)
f.close()
print("训练集:{} 测试集:{}".format(X_train.shape[0],X_test.shape[0]))
"""=====================================================================================================================
2 网格搜索
"""
# X_train,X_val,y_train,y_val = train_test_split(X_train,y_train,test_size=0.3,random_state=1)
X_train,X_val,y_train,y_val = X_train,X_test,y_train,y_test
print("训练集:{} 验证集:{} 测试集:{}".format(X_train.shape[0],X_val.shape[0],X_test.shape[0]))
best_score = 0
for gamma in [0.001,0.01,0.1,1,10,100]:
for C in [0.001,0.01,0.1,1,10,100]:
svm = SVC(gamma=gamma,C=C)
svm.fit(X_train,y_train)
score = svm.score(X_val,y_val)
print("当前gamma值:{} , 当前C值:{}, 当前分数:{}".format(gamma, C, score))
if score > best_score:
best_score = score
best_parameters = {'gamma':gamma,'C':C}
svm = SVC(**best_parameters) #使用最佳参数,构建新的模型
svm.fit(X_train,y_train) #使用训练集和验证集进行训练,more data always results in good performance.
test_score = svm.score(X_test,y_test) # evaluation模型评估
print("Best score on validation set:{}".format(best_score))
print("Best parameters:{}".format(best_parameters))
print("Best score on test set:{}".format(test_score))
3. 交叉验证
3.1 原理
一个模型如果性能不好,要么是因为模型过于复杂导致过拟合(高方差),要么是模型过于简单导致导致欠拟合(高偏差)。使用交叉验证评估模型的泛化能力,使用交叉验证可以减少初始数据的划分的偶然性,使得对模型的评估更加准确。
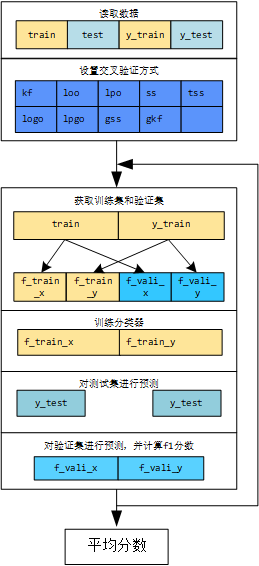
3.2 交叉验证方式
sklearn中的交叉验证(Cross-Validation)
"""
3.1 交叉验证方式
"""
## 对交叉验证方式进行指定,如验证次数,训练集测试集划分比例等
kf = KFold(n_splits=5, random_state=1)
loo = LeaveOneOut()#将数据集分成训练集和测试集,测试集包含一个样本,训练集包含n-1个样本
lpo = LeavePOut(p=2000)## #将数据集分成训练集和测试集,测试集包含p个样本,训练集包含n-p个样本
ss= ShuffleSplit(n_splits=5, test_size=.25, random_state=0)
## ShuffleSplit 咋一看用法跟LeavePOut 很像,其实两者完全不一样,LeavePOut 是使得数据集经过数次分割后,所有的测试集出现的
##元素的集合即是完整的数据集,即无放回的抽样,而ShuffleSplit 则是有放回的抽样,只能说经过一个足够大的抽样次数后,保证测试集出
##现了完成的数据集的倍数。
tss = TimeSeriesSplit(n_splits=5)# 针对时间序列的处理,防止未来数据的使用,分割时是将数据进行从前到后切割(这个说法其实不太恰当,因为切割是延续性的。。)
3.3 下面的几种分组的交叉验证方式还没弄懂 (具体是怎么分组的)
logo = LeaveOneGroupOut()# 这个是在GroupKFold 上的基础上混乱度又减小了,按照给定的分组方式将测试集分割下来。
lpgo = LeavePGroupsOut(n_groups=3)# 跟LeaveOneGroupOut一样,只是一个是单组,一个是多组
gss = GroupShuffleSplit(n_splits=5, test_size=.2, random_state=0)# 这个是有放回抽样
skf = StratifiedKFold(n_splits=3)#通过指定分组,对测试集进行无放回抽样。【指定分组具体是怎么指定的????】
gkf = GroupKFold(n_splits=2)# 这个跟StratifiedKFold 比较像,不过测试集是按照一定分组进行打乱的, 即先分堆,然后把这些堆打乱,每个堆里的顺序还是固定不变的。
3.4 实验代码
#!/usr/bin/env python 3.6
#-*- coding:utf-8 -*-
# @File : CV1.py
# @Date : 2018-11-22
# @Author : 黑桃
# @Software: PyCharm
from pandas import Series, DataFrame
import pickle
from sklearn import svm
from sklearn.model_selection import * #划分数据 交叉验证
from sklearn.metrics import accuracy_score, recall_score, f1_score, roc_auc_score, roc_curve
import warnings
warnings.filterwarnings("ignore")
path = "E:/MyPython/Machine_learning_GoGoGo/"
"""=====================================================================================================================
1 读取数据
"""
print("0 读取特征")
f = open(path + 'feature/feature_V3.pkl', 'rb')
train, test, y_train,y_test = pickle.load(f)
f.close()
"""=====================================================================================================================
2 进行K次训练;用K个模型分别对测试集进行预测,并得到K个结果,再进行结果的融合
"""
preds = []
i = 0
"""=====================================================================================================================
3 交叉验证方式
"""
## 对交叉验证方式进行指定,如验证次数,训练集测试集划分比例等
kf = KFold(n_splits=5, random_state=1)
loo = LeaveOneOut()#将数据集分成训练集和测试集,测试集包含一个样本,训练集包含n-1个样本
lpo = LeavePOut(p=2000)## #将数据集分成训练集和测试集,测试集包含p个样本,训练集包含n-p个样本
ss= ShuffleSplit(n_splits=5, test_size=.25, random_state=0)
tss = TimeSeriesSplit(n_splits=5)
logo = LeaveOneGroupOut()
lpgo = LeavePGroupsOut(n_groups=3)
gss = GroupShuffleSplit(n_splits=4, test_size=.5, random_state=0)
gkf = GroupKFold(n_splits=2)
"""【配置交叉验证方式】"""
cv=ss
clf = svm.SVC(kernel='linear', C=1)
score_sum = 0
# 原始数据的索引不是从0开始的,因此重置索引
y_train = y_train.reset_index(drop=True)
y_test = y_test.reset_index(drop=True)
for train_idx, vali_idx in cv.split(train, y_train):
i += 1
"""获取训练集和验证集"""
f_train_x = DataFrame(train[train_idx])
f_train_y = DataFrame(y_train[train_idx])
f_vali_x = DataFrame(train[vali_idx])
f_vali_y = DataFrame(y_train[vali_idx])
"""训练分类器"""
classifier = svm.LinearSVC()
classifier.fit(f_train_x, f_train_y)
"""对测试集进行预测"""
y_test = classifier.predict(test)
preds.append(y_test)
"""对验证集进行预测,并计算f1分数"""
pre_vali = classifier.predict(f_vali_x)
score_vali = f1_score(y_true=f_vali_y, y_pred=pre_vali, average='macro')
print("第{}折, 验证集分数:{}".format(i, score_vali))
score_sum += score_vali
score_mean = score_sum / i
print("第{}折后, 验证集分平均分数:{}".format(i, score_mean))
4. 网格搜索+交叉验证调参(直接调包实现)
4.1 实验代码
#!/usr/bin/env python 3.6
#-*- coding:utf-8 -*-
# @File : GrideSearchCV.py
# @Date : 2018-11-23
# @Author : 黑桃
# @Software: PyCharm
import numpy as np
import pickle
from sklearn.tree import DecisionTreeClassifier
from xgboost.sklearn import XGBClassifier
from sklearn import svm
import lightgbm as lgb
from sklearn.model_selection import *
import warnings
warnings.filterwarnings("ignore")
# iris = load_iris()
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import LogisticRegression
path = "E:/MyPython/Machine_learning_GoGoGo/"
"""=====================================================================================================================
1 读取数据
"""
print("0 读取特征")
f = open(path + 'feature/feature_V3.pkl', 'rb')
X_train,X_test,y_train,y_test = pickle.load(f)
f.close()
"""
3.1 交叉验证方式
"""
## 对交叉验证方式进行指定,如验证次数,训练集测试集划分比例等
kf = KFold(n_splits=5, random_state=1)
loo = LeaveOneOut()#将数据集分成训练集和测试集,测试集包含一个样本,训练集包含n-1个样本
lpo = LeavePOut(p=2000)## #将数据集分成训练集和测试集,测试集包含p个样本,训练集包含n-p个样本
ss= ShuffleSplit(n_splits=5, test_size=.25, random_state=0)
tss = TimeSeriesSplit(n_splits=5)
## 下面的几种分组的交叉验证方式还没弄懂
logo = LeaveOneGroupOut()
lpgo = LeavePGroupsOut(n_groups=3)
gss = GroupShuffleSplit(n_splits=5, test_size=.2, random_state=0)
gkf = GroupKFold(n_splits=2)
"""=====================================================================================================================
2 模型参数设置
"""
"""【SVM】"""
SVM_linear = svm.SVC(kernel = 'linear', probability=True)
SVM_poly = svm.SVC(kernel = 'poly', probability=True)
SVM_rbf = svm.SVC(kernel = 'rbf',probability=True)
SVM_sigmoid = svm.SVC(kernel = 'sigmoid',probability=True)
SVM_param_grid = {"C":[0.001,0.01,0.1,1,10,100]}
"""【LG】"""
LG = LogisticRegression()
LG_param_grid = {"C":[0.001,0.01,0.1,1,10,100]}
"""【DT】"""
DT = DecisionTreeClassifier()
DT_param_grid = {'max_depth':range(1,5)}
params = {'max_depth':range(1,21),'criterion':np.array(['entropy','gini'])}
"""【XGB_sklearn】"""
# XGB_sklearn = XGBClassifier(n_estimators=30,#三十棵树
# learning_rate =0.3,
# max_depth=3,
# min_child_weight=1,
# gamma=0.3,
# subsample=0.8,
# colsample_bytree=0.8,
# objective= 'binary:logistic',
# nthread=12,
# scale_pos_weight=1,
# reg_lambda=1,
# seed=27)
XGB_sklearn = XGBClassifier()
XGB_sklearn_param_grid = {"max_depth":[1,10,100]}
# param_test4 = {
# 'min_child_weight':[6,8,10,12],
# 'gamma':[i/10.0 for i in range(0,5)],
# 'subsample':[i/10.0 for i in range(6,10)],
# 'colsample_bytree':[i/10.0 for i in range(6,10)],
# 'reg_alpha': [1e-5, 1e-2, 0.1, 1, 100]
# }
"""【LGB_sklearn】"""
LGB_sklearn = lgb.LGBMClassifier()
# LGB_sklearn = lgb.LGBMClassifier(learning_rate=0.1,
# max_bin=150,
# num_leaves=32,
# max_depth=11,
# reg_alpha=0.1,
# reg_lambda=0.2,
# # objective='multiclass',
# n_estimators=300,)
LGB_sklearn_param_grid = {"max_depth":[1,10,100]}
def GridSearch(clf,param_grid,cv,name):
grid_search = GridSearchCV(clf,param_grid,cv=cv) #实例化一个GridSearchCV类
grid_search.fit(X_train,y_train) #训练,找到最优的参数,同时使用最优的参数实例化一个新的SVC estimator。
print(name+"_Test set score:{}".format(grid_search.score(X_test,y_test)))
print(name+"_Best parameters:{}".format(grid_search.best_params_))
print(name+"_Best score on train set:{}".format(grid_search.best_score_))
GridSearch(LGB_sklearn,LGB_sklearn_param_grid,kf,"LGB_sklearn")
GridSearch(LG,LG_param_grid,kf,"LG")
GridSearch(SVM_linear,SVM_param_grid,kf,"SVM_linear")
GridSearch(DT,DT_param_grid,kf,"DT")
GridSearch(XGB_sklearn,XGB_sklearn_param_grid,kf,"XGB_sklearn")
GridSearch(SVM_rbf,SVM_param_grid,kf,"SVM_rbf")
GridSearch(SVM_sigmoid,SVM_param_grid,kf,"SVM_sigmoid")
GridSearch(SVM_poly,SVM_param_grid,kf,"SVM_poly")
4.2 实验结果
| 模型 | 交叉验证方式 | 网格搜索参数 | 最优参数 | 训练集最优评分 | 测试集最优评分 |
|---|---|---|---|---|---|
| LGB_sklearn | kf | LGB_sklearn_param_grid = {“max_depth”:[1,10,100]} | {‘max_depth’: 1} | 0.7915848527349229 | 0.7863751051303617 |
| SVM_linear | kf | SVM_param_grid = {“C”:[0.001,0.01,0.1,1,10,100]} | {‘C’: 10} | 0.7870967741935484 | 0.7922624053826746 |
| SVM_poly | kf | SVM_param_grid = {“C”:[0.001,0.01,0.1,1,10,100]} | {‘C’: 100} | 0.7573632538569425 | 0.7485281749369218 |
| SVM_rbf | kf | SVM_param_grid = {“C”:[0.001,0.01,0.1,1,10,100]} | {‘C’: 100} | 0.7876577840112202 | 0.7855340622371741 |
| SVM_sigmoid | kf | SVM_param_grid = {“C”:[0.001,0.01,0.1,1,10,100]} | {‘C’: 100} | 0.7856942496493688 | 0.7729184188393609 |
| DT | kf | DT_param_grid = {‘max_depth’:range(1,5)} | {‘max_depth’: 4} | 0.7685834502103787 | 0.7729184188393609 |
| LG | kf | LG_param_grid = {“C”:[0.001,0.01,0.1,1,10,100]} | {‘C’: 1} | 0.7929873772791024 | 0.7973086627417998 |
| XGB_sklearn | kf | XGB_sklearn_param_grid = {“max_depth”:[1,10,100]} | {‘max_depth’: 100} | 0.7921458625525947 | 0.7914213624894869 |
5. 参考资料
模型的选择与调优:交叉验证与网格搜索
Machine Learning-模型评估与调参 ——K折交叉验证
sklearn中的交叉验证(Cross-Validation)
Grid Search 网格搜索