scrapy可以运行在python2.7、python3.3或者是更高的版本上;首先我们借用之前的知识,创建一个python环境。然后在此python环境中创建我们的scrapy项目。这里你如果不理解的可以给你们大个比方,python版本就好比是jdk,scrapy就好比Java项目,这么说你们应该能稍微理解一下两者之间的关系了,可能比喻不贴切,但应该就是这么回事。
1.创建pyhton环境,执行如下脚本:
mkvirtualenv -p /usr/bin/python3 article_scrapy2.查看当前环境的python版本,执行如下脚本:
python3.中途想退出此前的环境,执行如下脚本:
deactivate4.如何进入已创建的python环境,执行如下脚本:
workon article_scrapy5.安装scrapy环境,可以使用常规安装方法(版本更新快,但是安装速度慢),也可以使用豆瓣镜像安装(安装速度快,但可能版本更新的比较慢),各有和好处吧,执行如下脚本:
pip install -i https://pypi.douban.com/simple/ scrappy以上五步的效果图如下所示:

6.创建一个scrapy项目,执行如下脚本:
scrapy startproject ArticleScrapy
7.按照上述给出的方法,进行我们的创建,执行如下脚本:
cd ArticleScrapy #进入到scrapy项目路径下
scrapy genspider jobbole blog.jobbole.com #用模板创建一个爬虫程序

8.创建好了文件,我们打开此文件看看结构。
cd spiders/ #切换到此目录下
vim jobbole.py #打开文件生成的原始文件如下图所示:
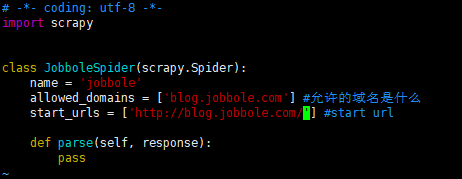
9.编写爬虫文件,爬取我们想要的东西,加入如下代码(注意代码的缩进),这里你可能不明白下面代码的意义,没有关系,先往下看就好了,后面的章节会详细讲解到:
#//*[@id = "post-114505"]/div[1]/h1
#/html/body/div[1]/div[3]/div[1]/div[1]/h1
re_selector=response.xpath('//*[@id="post-114505"]/div[1]/h1/text()')
print(re_selector.extract()[0])
re_selector2 = response.xpath('//*[@id="post-114505"]/div[2]/p/text()[1]')
print(re_selector2.extract()[0])
10.保存并退出此文件,这个时候还需要修改一个配置文件,我们的爬虫才能正常的进行,修改settings.py文件,找到ROBOTSTXT_OBEY = False,原来是True,现在改为False.
vim settings.py #打开配置文件
ROBOTSTXT_OBEY = False #修改为False,这里好像是为了规避掉ROBOTSTXT协议对URL的过滤11.如何运行我们的蜘蛛,在项目的最顶层目录运行:
scrapy crawl jobbole你将得到如下输出:

到此一个爬虫的简单项目就完成了,下一节说一下scrapy start_url(初始链接)简写问题和原始问题解析!今晚到此为止吧,我也是小白一枚,如有问题欢迎各位大佬批评指正。虚心接受批评哦。