hbase中的一些重要的知识点
##1.应用场景
1.需要对海量非结构化的数据进行存储
2.需要随机近实时的读写管理数据
##2.rowKey的设计
- 长度原则: rowkey是一个二进制流,建议rowkey的长度不要超过16个字节
原因如下:
(1)数据的持久化文件HFile中是按照KeyValue存储的,如果Rowkey过长比如100个字节,1000万列数据光Rowkey就要占用100*1000万=10亿个字节,将近1G数据,这会极大影响HFile的存储效率;
(2)MemStore将缓存部分数据到内存,如果Rowkey字段过长内存的有效利用率会降低,系统将无法缓存更多的数据,这会降低检索效率。因此Rowkey的字节长度越短越好。
(3)目前操作系统是都是64位系统,内存8字节对齐。控制在16个字节,8字节的整数倍利用操作系统的最佳特性。
-
散列原则: 如果rowkey是按时间戳的方式递增,不要将时间放在二进制码前,建议将rowkey的高位作为散列字段,由程序循环生成,低位放时间字段,这样将提高数据均衡分布在每个regionserver实现负载均衡的几率.如果没有散列字段,首字段直接是时间信息,将产生所有新数据都在一个regionserver上堆积的热点现象,这样在做数据检索的时候负载将会集中在个别regionserver上,降低查询效率
-
rowKey唯一原则: 必须在设计上保持其唯一性.
##3.二级索引
二级索引的本质就是建立各列值与行键之间的映射关系.

由于 HBase 本身没有二级索引( Secondary Index)机制,基于索引检索数据只能单纯地依靠 RowKey,为了能支持多条件查询,开发者需要将所有可能作为查询条件的字段一一拼接到 RowKey 中,这是 HBase 开发中极为常见的做法
##4.协处理器
协处理器有两种:observer和endpoint
Observer允许集群在正常的客户端操作过程中可以有不同的行为表现
Endpoint允许扩展集群的能力,对客户端应用开放新的运算命令
Observer协处理器
² 正常put请求的流程:
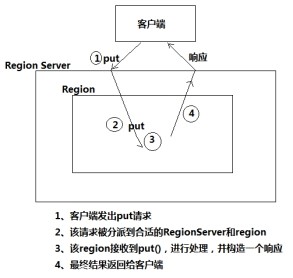
² 加入Observer协处理后的put流程:
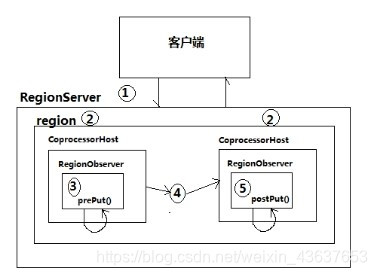
1 客户端发出put请求
2 该请求被分派给合适的RegionServer和region
3 coprocessorHost拦截该请求,然后在该表上登记的每个RegionObserver上调用prePut()
4 如果没有被prePut()拦截,该请求继续送到region,然后进行处理
5 region产生的结果再次被CoprocessorHost拦截,调用postPut()
6 假如没有postPut()拦截该响应,最终结果被返回给客户端
Observer的类型
1、RegionObs——这种Observer钩在数据访问和操作阶段,所有标准的数据操作命令都可以被pre-hooks和post-hooks拦截
2、WALObserver——WAL所支持的Observer;可用的钩子是pre-WAL和post-WAL
3、 MasterObserver——钩住DDL事件,如表创建或模式修改
5.hbase和hive、hdfs的关系
Hive与Hbase的数据一般都存储在HDFS上。Hadoop HDFS为他们提供了高可靠性的底层存储支持。
Hive:
Hive不支持更改数据的操作,Hive基于数据仓库,提供静态数据的动态查询。其使用类SQL语言,底层经过编译转为MapReduce程序,在Hadoop上运行,数据存储在HDFS上。
HDFS:
HDFS是GFS的一种实现,他的完整名字是分布式文件系统,类似于FAT32,NTFS,是一种文件格式,是底层的。
Hbase:
Hbase是Hadoop database,即Hadoop数据库。它是一个适合于非结构化数据存储的数据库,HBase基于列的而不是基于行的模式。
6.hbase的架构及各组件的功能
client**:**
1.hbase的客户端,包含访问hbase的接口(linux shell 、java api)
2.client维护一些cache来加快访问hbase的速度,比如region的位置信息
zookeeper**:**
1.监控hmaster的状态,保证有且仅有一个active的hmaster,达到高可用。
2.存储所有region的寻址入口,–root表在那台服务器上。
3.实时监控hregionserver的状态,将regionserver的上下线信息实时通知给hmaster
4.存储hbase的所有表的信息(hbase的元数据)
hmaster**:(hbase的老大)**
1.为regionserver分配region(新建表等)
2.负责regionserver的负载均衡
3.负责region的重新分配(hregionserver异常、hregion裂变)
4.hdfs上的垃圾文件回收
5.处理schema的更新请求
hregionserver**:(hbase的小弟)**
1.hregionserver维护master分配给他的region(管理本机器上region)
2.处理client对这些region的IO请求,并和hdfs进行交互
3.region server负责切分在运行过程中变大的region
hlog:
对hbase的操作进行记录,使用WAL写数据,优先写入log,然后再写memstore(提速的工具),以防数据丢失时可以进行回滚.
hregion:
hbase中分布式存储和负载均衡的最小单元,是表或者表的一部分
store:
相当于一个列簇.
memstore:128M
内存缓冲区,用于将数据批量刷新到HDFS上.
hstorefile(hfile):
hbase中的数据是以hfile的形式存储在hdfs上
7.hbase的优化
客户端的优化
1.关闭自动刷新
.setAutoFlush
2.尽量批量写入数据(put或者delete时尽量批量写入)
3.谨慎关闭写Log
.setDurability(Durability.SKI);
4.尽量将数据放入到缓存:
.setInMemory(true);
5.尽量不要有太多的列簇,最多两个,hbase在刷新列簇的同时会将相邻的两个列簇也刷新到磁盘
6.rowkey的长度尽量的短,最大64KB,尽量将该关闭的资源关闭
Admin,Table,ResultScanner等 (连接到服务器的对象)
8.宽表高表的选择
hbase中的宽表是指很多列较少行,即列多行少的表,一行中的数据量较大,行数少;高表是指很多行较少列,即行多列少,一行中的数据量较少,行数大。
宽表和高表的优劣总结如下:
1.查询性能:高表更好,因为查询条件都在row key中, 是全局分布式索引的一部分。高表一行中的数据较少。所以查询缓存BlockCache能缓存更多的行,以行数为单位的吞吐量会更高。
2.分片能力:高表分片粒度更细,各个分片的大小更均衡。因为高表一行的数据较少,宽表一行的数据较多。HBase按行来分片。
3.元数据开销:高表元数据开销更大。高表行多,row key多,可能造成region数量也多,- root -、 .meta表数据量更大。过大的元数据开销,可能引起HBase集群的不稳定、master更大的负担(这方面后续再好好总结)。
4.事务能力:宽表事务性更好。HBase对一行的写入(Put)是有事务原子性的,一行的所有列要么全部写入成功,要么全部没有写入。但是多行的更新之间没有事务性保证。
5.数据压缩比:如果我们对一行内的数据进行压缩,宽表能获得更高的压缩比。因为宽表中,一行的数据量较大,往往存在更多相似的二进制字节,有利于提高压缩比。通过压缩,缓解了宽表一行数据量太大,并导致分片大小不均匀的问题。查询时,我们根据row key找到压缩后的数据,进行解压缩。而且解压缩可以通过协处理器(coproesssor)在HBase服务器上做,而不是在业务应用的服务器上做,以充分应用HBase集群的CPU能力