一、简介
继上一篇基于用户的推荐算法,这一篇是要基于商品的,基于用户的好处是可以根据用户的评价记录找出跟他兴趣相似的用户,再推荐这些用户也喜欢的电影,但是万一这个用户是新用户呢?或是他还没有对任何电影做评价,那我们要怎么去推荐他可能会有兴趣的东西呢?这边就是要介绍基于商品的相似度,我们打开豆瓣随便查看一部电影,会看到下面有一个栏位是喜欢这部电影的人也喜欢哪些电影,就是利用了商品相似度的概念。商品相似度还有一个好处,就是可以“事先”计算好,由于商品相似度每个用户看到的结果都会是一样的,他可以事先就先算好放在那,等有一批新商品进入时再计算,比较不需要为每个用户都计算一遍,这是他的一个很大的优势。原理也很简单,就是找出喜欢这个电影的用户,他们也喜欢哪些电影,下面就是利用pyhton来做示范。
二、数据预处理
这次我们还是沿用之前在movielens下载的数据,但由于我们的“目标”变了,所以数据预处理的方式也要做些调整,之前我们是以人为键值(key),后面跟了他评价的电影和评分,现在我们要改成以电影为键值,后面跟了评价他的人和给出的评分,这样做是方便到时候算法代码比较好写,下面是数据读取和预处理的代码。
def load_data(): f = open('u.data') movie_list={} for line in f: (user,movie,rating,ts) = line.split('\t') movie_list.setdefault(movie,{}) movie_list[movie][user] = float(rating) return movie_list
用print查看movie_list的样子
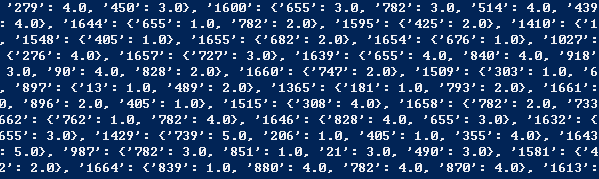
可以看到,与前面以人为主的相比,很多电影的评分人数都只有一个,所以数据量的不足也会影响到最后算出来的结果。
三、数据分析
这边跟前面以人为主的推荐有点不一样,上一篇我挑了7号用户作为我们的推荐对象,但商品我要对‘’所有商品‘’都找出他们的相似商品,计算量就会大很多,下面为代码
def calculate(): list = load_data() movie_diff = {} for movie1 in list.keys(): movie_diff.setdefault(movie1,{}) for movie2 in list.keys(): if movie1 != movie2: a = 0 b=0 for name1 in list[movie1].keys(): for name2 in list[movie2].keys(): if name1 == name2: diff = sqrt(pow(list[movie1][name1] -list[movie2][name2],2)) b += 1 a += diff if b != 0: movie_diff[movie1][movie2] = 1/(1+(a/b)) print(movie_diff)
这次跑的时间长了很多,因为要拿所有电影跟其他所有电影进行比较,而且是要比评价电影的所有人,所以计算量大很多,以下是跑完出来的结果,可以看到其实很多的相关性都是1,代表其实由于数据量太少,所以出来的结果参考价值并不大。
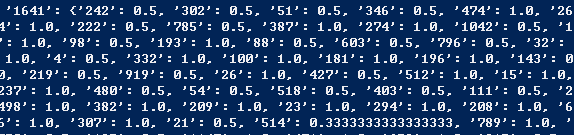
四、后续改进
以下是经过这两次的演练的心得
1、欧几里得虽然简单快速,但他出来的结果并不好,下次可以试试其他的算法
2、for循环可以用矩阵来代替,效率会更好
3、可以尝试跑数据量大数据,出来的效果会比较好