版权声明:本文为博主原创文章,如果喜欢欢迎收藏转载!如有错误,请指出! https://blog.csdn.net/h___q/article/details/84330490
环境
在C语言的任何一种实现中,存在两种不同的环境,分别是翻译环境和执行环境。这两种环境并不一定必须同时位于一台机器上。
翻译环境
翻译环境即是为C语言代码从代码转变为机器可以执行的二进制文件过程中所要依赖的环境。
执行环境
执行环境即用于实际执行代码。
程序的翻译过程
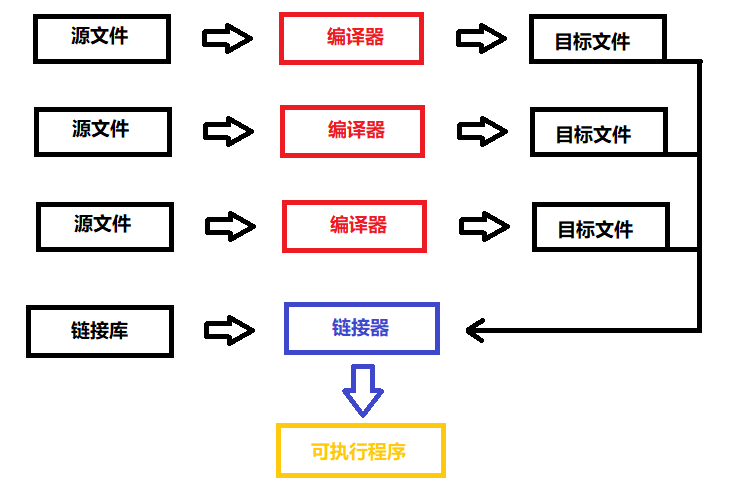
当一个项目进程编译时,项目中可能存在多个xxx.c的源文件,每一个源文件都会单独经过编译器处理并分别生成一个目标文件,当生成目标文件之后再经过链接器,将生成的目标文件及库文件链接进来并生成可执行程序。所以一个源文件会经过两个大的过程,即先编译,后链接。在windows下,xxx.c源文件经过编译器处理之后会生成xxx.obj的目标文件。在windows环境下,目标文件为xxx.o文件。
C语言代码编译过程详解
预处理
预处理阶段编译器仅会对源文件进行文本处理。
在Linux环境下,使用下面的命令对xxx.c源文件仅进行预处理:
- gcc -E xxx.c -o xxx.i
编译器在预处理阶段会做如下的事情:
- 删除代码中的注释片段
- 用实际值替换代码中的宏定义(#define)并删除宏定义行
- 展开头文件(#include)
编译
在该阶段编译器会检测代码中的错误,绝大多数的错误和警告产生在这个过程中。
在Linux环境下,使用下面的命令产生xxx.c/xxx.i源文件经过编译后的文件xxx.s:
- gcc -S xxx.c/xxx.i -o xxx.s
编译器在编译阶段会做如下的事情:
- 将C语言代码转换为汇编代码
- 对代码进行语法分析、词法分析、语义分析、符号汇总
- 语法分析
- 词法分析
- 语义分析
- 符号汇总:统计代码中出现的全局变量、静态变量。
汇编
在Linux环境下,使用下面的命令产生xxx.x/xxx,i/xxx.s源文件经过汇编之后的文件xxx.o:
- gcc xxx.c/xxx.i/xxx.s -o xxx.o
编译器在这个过程中会做如下的事情:
- 将汇编代码转换为机器指令(二进制指令)
- 生成符号表:依赖编译阶段的符号汇总,会给每一个符号分配一个地址,所以代码中的全局变量、静态变量会在该阶段分配好储存空间。
- 在Linux下,使用readelf -s xxx.o即可查看目标文件中的生成的符号表
- 在该阶段中,会给代码中的函数符号分配一个地址,用来供后来的链接器合并文件使用
链接
链接器会做如下的事情:
- 合并段表
- elf:一种文件组织形式
- 编译器会在编译阶段,按照elf的组织形式,将生成的目标文件分为固定的段,当链接器需要合并多个目标文件时,合并每个目标文件的对应段即可。
- elf:一种文件组织形式
- 符号表的合并和重定位
- 将不同目标文件的符号表进行合并。
- 重定位:当不同的符号表进行合并时,有时会出现不同的目标文件中含有一个或多个相同的符号,这种情况多出现与一个xxx.c文件使用了另一个xxx.c文件中的函数,所以在定义被使用函数的xxx.c的目标文件中,该函数的符号对应的指针是一个合法的值,而在使用函数的xxx.c的目标文件中,该函数符号对应的指针则是一个非法的值,链接器合并这两个目标文件时,发现两个目标文件的符号表中都含有该函数的符号,则链接器会检测哪一个符号对应的指针为合法的值,即将该符号在合并后的符号表中的位置修改为该合法值。
- 生成的新的符号表即就会存放在生成的可执行文件中。