- 当我们编译C程序时会发生什么?
- 编译过程中的组件有哪些,编译执行过程是什么样的?
-
什么是编译
C语言的编译过程就是把我们可以理解的高级语言代码转换为计算机可以理解的机器代码的过程,其实就是一个翻译的过程。
源代码和可执行机器代码
程序编译是将源代码转换为可执行代码的过程,通常包括以下几个主要步骤:
-
预处理(Preprocessing): 在这个阶段,预处理器会处理源代码文件,执行一些预处理指令。常见的预处理指令包括
#include(用于包含头文件)、#define(用于定义宏)、#ifdef和#ifndef(用于条件编译)等。预处理器的输出通常是一个经过预处理的源代码文件。 -
编译(Compilation): 编译器接收预处理后的源代码并将其转换为汇编代码。汇编代码是一种低级的代码,与特定的计算机体系结构相关。编译器会执行语法分析、语义分析和代码生成等操作。如果在这个阶段发现语法错误或其他编译错误,编译过程会中止,并输出错误消息。
-
汇编(Assembly): 汇编器接收编译器生成的汇编代码,并将其转换为机器代码或可重定位目标代码。汇编过程将汇编指令转换为二进制形式,同时解析符号引用,生成可执行的机器代码或可链接的目标文件。
-
链接(Linking): 如果程序由多个源代码文件组成,编译后会生成多个目标文件。链接器接受这些目标文件以及所需的库文件,并将它们组合成一个可执行文件。链接过程涉及解析符号引用,将不同模块之间的引用关系解决,并生成最终的可执行文件。这也包括动态链接(在运行时加载共享库)或静态链接(在编译时将库链接到可执行文件)。
-
优化(Optimization)(可选): 一些编译器在生成目标代码之前会执行优化步骤,以提高程序的性能或减小可执行文件的大小。优化可以包括常量折叠、循环展开、内联函数、无用代码删除等操作。
-
生成可执行文件(Executable Generation): 最终的可执行文件包含了机器代码,它是计算机可以直接执行的二进制文件。这个文件可以通过操作系统加载到内存中,并执行。
总之,程序编译的过程包括预处理、编译、汇编、链接和可选的优化步骤,最终生成可执行文件。不同的编程语言和编译器可能在这个过程中有些许不同,但这个基本流程适用于大多数编程环境.
详细分析
C 语言的编译过程主要包括四个步骤:
- 预处理
- 编译
- 汇编
- 连接
下面这张图就是C程序编译的完整过程

接下我们看看编译过程不同阶段都在做什么。
1.预处理
编译过程的第一步预就是预处理,与处理结束后会产生一个后缀为(.i)的临时文件,这一步由预处理器完成。预处理器主要完成以下任务。
- 删除所有的注释
- 宏扩展
- 文件包含
预处理器会在编译过程中删除所有注释,因为注释不属于程序代码,它们对程序的运行没有特别作用。
宏是使用 #define 指令定义的一些常量值或表达式。宏调用会导致宏扩展。预处理器创建一个中间文件,其中一些预先编写的汇编级指令替换定义的表达式或常量(基本上是匹配的标记)。为了区分原始指令和宏扩展产生的程序集指令,在每个宏展开语句中添加了一个“+”号。
文件包含
C语言中的文件包含是在预处理期间将另一个包含一些预写代码的文件添加到我们的C程序中。它是使用#include指令完成的。在预处理期间包含文件会导致在源代码中添加文件名的全部内容,从而替换#include<文件名>指令,从而创建新的中间文件。
2.编译
C 中的编译阶段使用内置编译器软件将 (.i) 临时文件转换为具有汇编级指令(低级代码)的汇编文件 (.s)。为了提高程序的性能,编译器将中间文件转换为程序集文件。
汇编代码是一种简单的英文语言,用于编写低级指令(在微控制器程序中,我们使用汇编语言)。整个程序代码由编译器软件一次性解析(语法分析),并通过终端窗口告诉我们源代码中存在的任何语法错误或警告。
下图显示了编译阶段如何工作的示例。
3.组装
使用汇编程序将程序集级代码(.s 文件)转换为机器可理解的代码(二进制/十六进制形式)。汇编程序是一个预先编写的程序,它将汇编代码转换为机器代码。它从程序集代码文件中获取基本指令,并将其转换为特定于计算机类型(称为目标代码)的二进制/十六进制代码。
生成的文件与程序集文件同名,在 DOS 中称为扩展名为 .obj 的对象文件,在 UNIX 操作系统中扩展名为 .o。
下图显示了组装阶段如何工作的示例。程序集文件 hello.s 将转换为具有相同名称但扩展名不同的对象文件 hello.o。
4. 链接
链接是将库文件包含在我们的程序中的过程。库文件是一些预定义的文件,其中包含机器语言中的函数定义,这些文件的扩展名为.lib。一些未知语句写入我们的操作系统无法理解的对象 (.o/.obj) 文件中。你可以把它理解为一本书,里面有一些你不知道的单词,你会用字典来找到这些单词的含义。同样,我们使用库文件来为对象文件中的一些未知语句赋予意义。链接过程会生成一个可执行文件,其扩展名为 .exe 在 DOS 中为 .out,在 UNIX 操作系统中为 .out。
下图显示了链接阶段如何工作的示例,我们有一个具有机器级代码的对象文件,它通过链接器传递,链接器将库文件与对象文件链接以生成可执行文件。
举例
接下来,我们通过一个例子详细看看C编译过程中涉及的所有步骤。第一步先写一个简单的C程序并保存为hello.c
// Simple Hello World program in C
#include<stdio.h>
int main()
{
// printf() is a output function which prints
// the passed string in the output console
printf("Hello World!");
return 0;
}接着我们执行编译命令对hello.c进行编译:
gcc -save-temps hello.c -o compilation-save-temps 选项会保留所有编译过程中产生的中间文件,总共会生成四个文件。
- hello.i 预处理器产生的文件
- hello.s 编译器编译后产生的文件
- hello.o 汇编程序翻译后的目标文件
- hello.exe 可执行文件(Linux系统会产生hello.out文件)
首先,我们的C程序的预处理开始,注释从程序中删除,因为该程序中没有宏指令,因此宏扩展不会发生,我们还包含了一个stdio.h头文件,并且在预处理期间,标准输入/输出函数(如printf(),scanf()等)的声明被添加到我们的C程序中。
打开预处理阶段产生的hello.i 文件就可以看到类似下面这样的代码。
# 1 "hello.c"
# 1 ""
# 1 ""
# 1 "hello.c"
# 1 "C:/Program Files (x86)/CodeBlocks/MinGW/include/stdio.h" 1 3
# 293 "C:/Program Files (x86)/CodeBlocks/MinGW/include/stdio.h" 3
int __attribute__((__cdecl__)) __attribute__ ((__nothrow__)) fprintf (FILE*, const char*, ...);
int __attribute__((__cdecl__)) __attribute__ ((__nothrow__)) printf (const char*, ...);
int __attribute__((__cdecl__)) __attribute__ ((__nothrow__)) sprintf (char*, const char*, ...);
int __attribute__((__cdecl__)) __attribute__ ((__nothrow__)) scanf (const char*, ...);
int __attribute__((__cdecl__)) __attribute__ ((__nothrow__)) sscanf (const char*, const char*, ...);
...
...
...
int __attribute__((__cdecl__)) __attribute__ ((__nothrow__)) putw (int, FILE*);
# 3 "hello.c" 2
int main()
{
printf("Hello World!");
return 0;
}从上面的代码中可以看到,预编译过后,所有的注释没有了,#include <stdio.h>也被它的头文件内容代替了。
接下来就是编译阶段,编译器接收到hello.i 文件将它转化为汇编代码hello.s文件。这过程中发生了以下几件事:
- 编译器检查语法错误
- 将源代码翻译中间代码,例如汇编代码
- 对代码进行优化
编译结束后产生的hello.s 文件长这个样子:
.file "hello.c"
.def ___main; .scl 2; .type 32; .endef
.section .rdata,"dr"
LC0:
.ascii "Hello World!\0"
.text
.globl _main
.def _main; .scl 2; .type 32; .endef
_main:
LFB12:
.cfi_startproc
pushl %ebp
.cfi_def_cfa_offset 8
.cfi_offset 5, -8
movl %esp, %ebp
.cfi_def_cfa_register 5
andl $-16, %esp
subl $16, %esp
call ___main
movl $LC0, (%esp)
call _printf
movl $0, %eax
leave
.cfi_restore 5
.cfi_def_cfa 4, 4
ret
.cfi_endproc
LFE12:
.ident "GCC: (MinGW.org GCC-6.3.0-1) 6.3.0"
.def _printf; .scl 2; .type 32; .endef接下来,汇编程序把hello.s 文件转换为二进制代码,并在Windows环境中生成对象文件 hello.obj,在 Linux系统中生成 hello.o文件。
接着,链接器使用库文件将所需的定义添加到对象文件中,并在Windows环境中生成一个可执行文件 hello.exe,在 Linux操作系统中生成 hello.out文件。
- 当我们运行 hello.exe/hello.out 时,我们会在屏幕上 输出 Hello World!。
程序流程图
让我们看一下C语言编译过程中程序的流程图:
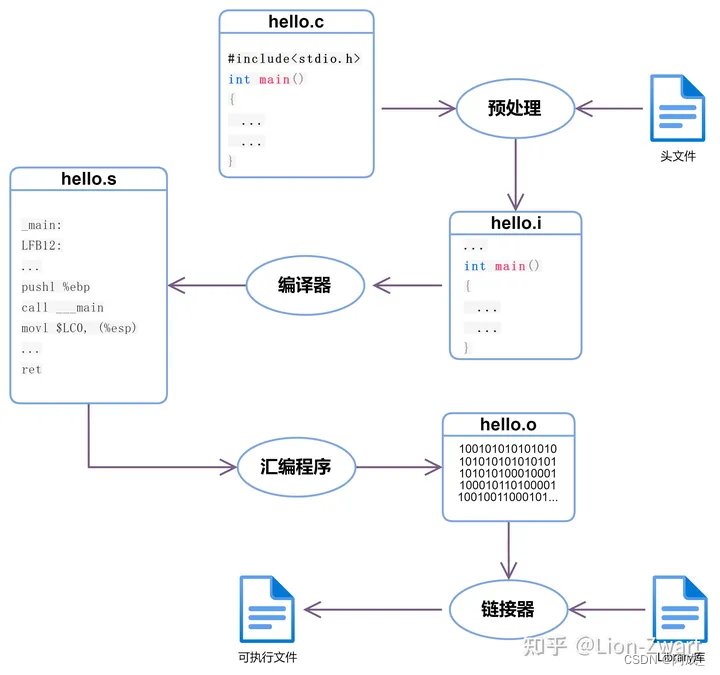
结论
- C中的编译过程也称为将人类可理解代码(C程序)转换为机器可理解代码(二进制代码)的过程。
- C语言的编译过程包括四个步骤:预处理、编译、汇编和链接。
- 预处理器执行删除注释、宏扩展、文件包含。这些命令在编译过程的第一步执行。
- 编译器可以提高程序的性能,并将中间文件转换为汇编文件。
- 汇编程序有助于将汇编文件转换为包含机器代码的对象文件。
- 链接器用于将库文件与对象文件链接。这是编译中生成可执行文件的最后一步。
参考网址: