转载自: https://blog.csdn.net/qq2414205893/article/details/78901517
论文阅读小结(以下内容为论文阅读笔记及总结)
NIPS2017
-
6608-deep-subspace-clustering-networks
这篇文章的创新点在于,提出了一个自表达层,来对特征进行具有自表达能力的子空间学习。其目标函数为:
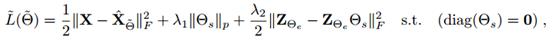
该函数借鉴了,周志华多源数据聚类传统方法的目标函数,几乎没有变化。其主要算法流程为将数据输入xi经过神经网络编码为zi,然后在通过反卷积将zi解码为输出表达`Xi`,最后使用传统谱聚类算法根据学习到的邻接矩阵θs对数据进行聚类。其网络构架如下:

其中本文的一个可以借鉴点是将传统方法中涉及矩阵学习的迭代优化算法,改为使用神经网络做端到端的梯度下降优化,其具体实现模块如图所示:
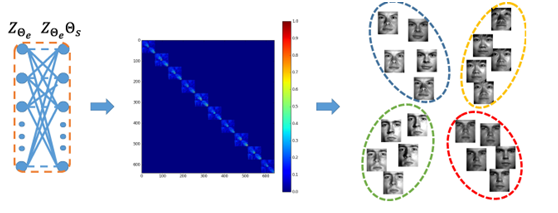
整个过程是非监督地聚类。本文局限在于,有多少个样本,为了学习对应的邻接矩阵,需要使用对应个数的全连神经网络,不能做到自适应聚类样本个数,可以看做是特征的refine。
-
6644-pose-guided-person-image-generation
本文采用了对抗生成式网络,通过在一个具有同一个不同姿势的数据库上训练,使网络学习到不同姿势对应的像素漂移映射,然后只需要给出目标pose,即使用21*2的矩阵表示人体关节的21个关键点位置,就能够生成一张同一个人的目标姿势照片。效果图如下:

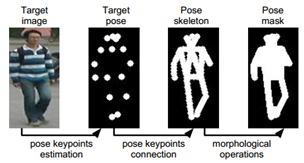
其中本文所用的关节点检测模型为Realtime multi-person 2d pose estimation using part affinity fields是目前最先进的姿势估计网络之一。其主要过程如下图所示:

然后通过两个阶段的对抗生成网络:
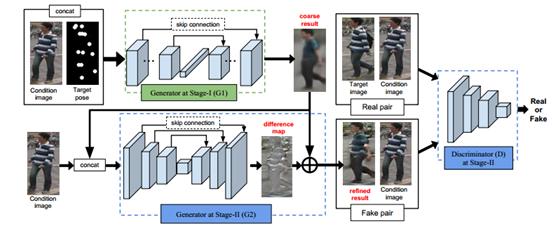
第一阶段使用原图和pose关键点mask级联作为输入,得到粗糙生成图片,然后第二阶段再由粗糙图片和同一个人的候选图片进行提炼refine,然后再把图片输入判别模型,采用极大化极小策略对目标函数优化:

最后他的贡献用于扩充行人重识别数据库,使得网络在学习时就能捕捉到各种同一个人的姿势变化,从而达到提取出姿势不变的特征。
-
6609-Attentional Pooling for Action Recognition
随着注意力机制在NLP和CV任务中的广泛运用,越来越多的学者对注意力机制的具体模块做出了建设性的探索,本篇文章是NIPS的oral文章,它提出了二阶注意力模块,同时用大量的实验探索了,注意力模块应该加入在深度网络的什么位置,不同的基本网络与注意力模块的相互影响等等。
本文的算法印证主要是在人体行为识别数据库UCF101等上进行,其效果如下:

右侧为注意力模块学习到的注意力关注区域。
传统一阶注意力网络大多为学习一个locations*1的mask向量,向量的值代表了对应位置上的权重,但是它没有挖掘到,location之间的关系或者说是相互作用的权重。所以产生了二阶注意力机制。
二阶注意力流程图如下:
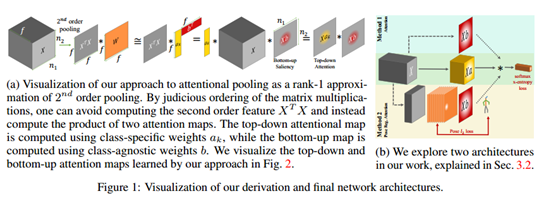
通过所提Attention pooling层可以学到一个二阶attention矩阵,而不仅仅只是一个mask向量,然后再conbine二阶和一阶的mask,就能得到更加精确的注意力关注区域。
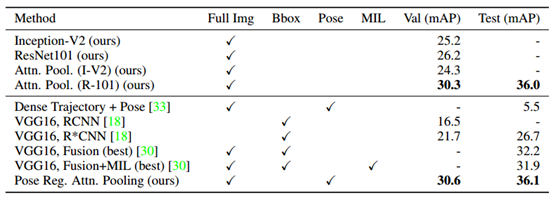
从结果中可以看到,使用了attention pooling接近从baseline提升了9个百分点。
CVPR2017
-
【CVPR2017】Beyond triplet loss: a deep quadruplet network for person re-identification
本文提出了四重损失函数:
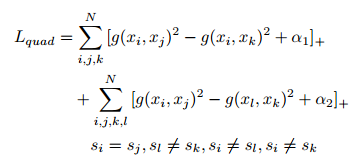
其中i为anchor,j为positive,k为negative1,l为negative2,目标函数物理意义在于使用另个不同的negative进一步增大类间距离,但是如果相对于使用足够多的triplet组进行训练时,理论上应该能够达到相同效果。本文trick在于:
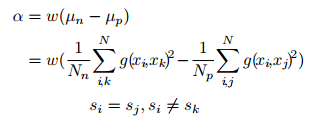
其中的a是loss函数中的margin,其物理意义在于针对每一个batch的数据所组成的an和ap对之间距离的间隔,应该是动态变化的,所以这篇文章将margin动态地设置为所有an对距离的均值和所有ap对之间距离的均值的差值,这样能够使网络学习时每一个batch都能起到拉开类间距离和缩小类内距离的作用,如果margin 固定,当margin过小时,针对一个batch中类间距离很大的情况,这一次的学习就会没有意义,应为不管怎样类间距离都会远大于类内距离,所以类内距离没有被压缩。并且作者还用w来平衡三元组和四元组的影响,三元组为1,四元组为0.5.
本文没有做Market数据集上的实验。
-
【CVPR2017】Consistent-Aware Deep Learning for Person Re-Identification in a Camera Network
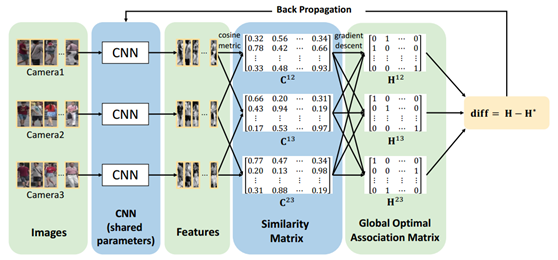
本文提出了和普通行人重识别不一样的任务目标以及评价标准,其主要思想在于设计一个网络使得通过这个网络提取出的图像特征能够在同一个摄像头中尽可能地匹配准确,例如通常我们评估行人重识别精度在具有很多个摄像头,或者摄像头信息不完全等数据库时,采用多射策略——即只要匹配到同一个的图就算匹配上,无论这两张图是否来自同一个摄像头。而本文则是只有同一个人的不同摄像头之间的照片匹配正确了才算是成功的行人重识别,并且希望尽可能多的让每个不同摄像头之间的照片匹配得上的多,就是一号摄像头匹配二号和三号的数量和二号匹配三号的数量都要尽可能多。本文并不是一个端到端的过程,但是其自定义的feedback求导过程值得研究。
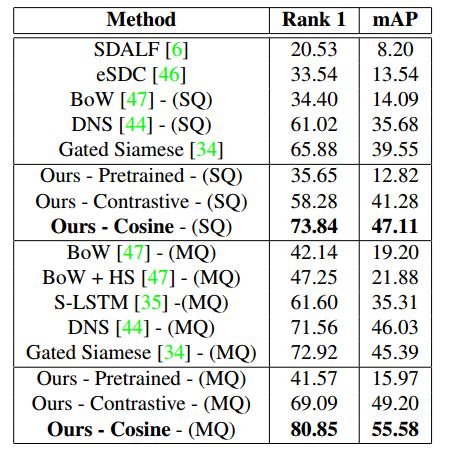
其在Market数据集上的精度如下:
-
【CVPR2017】Fast Person Re-Identification via Cross-Camera Semantic Binary Transformation
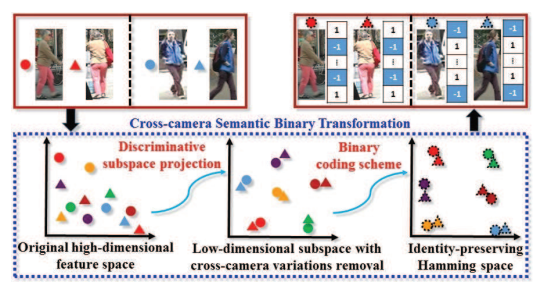
本文思想和我本身的Cross-domain latent space projection for reid工作十分相似,其代价函数也是学习一个投影向量,将分图像部分的高维特征向量投影到低维子空间中并且保持类内距离变小,类间距离拉大,然后把分部分的向量二值化,通过逐部分的比较,然后综合来考虑这两张图片是否匹配正确。
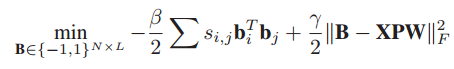
该方法是将最终的哈希函数也加入到类内类间的代价函数中,一次性优化而成,主要属于哈希算法和子空间学习的联合应用。
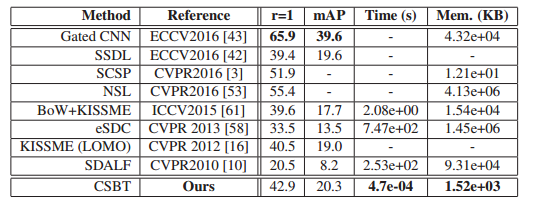
Market数据库精度,主要是速度大幅提升:
-
【CVPR2017】Joint Detection and Identification Feature Learning for Person Search
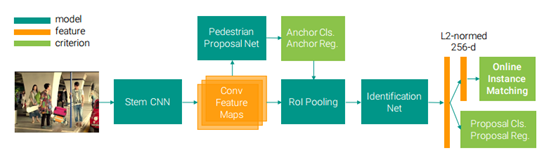
本文是将行人检测网络和行人重识别网络联合在一起,模型和算法没有创新,主要是解决了行人检测网络的回归框大小和行人重识别网络的输入图像大小之间的问题。使得整个端到端的过程更加接近真实场景的行人重识别。没有新的代价函数。
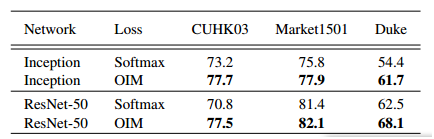
其在Market数据集上的精度如下:
-
【CVPR2017】Learning Deep Context-aware Features over Body and Latent Parts for Person Reidentification
本文提出了所谓的身体潜在块学习网络,其网络构架如下:
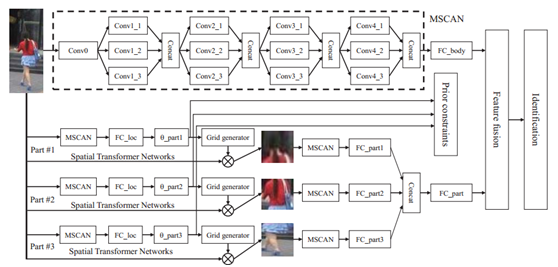
整个网络使用堆叠的CNN(MSCAN)对整张图像进行特征提取,同时也将图像的部分作为一个输入进入这个MSCAN进行特征提取,最终将一个全局特征和三个局部潜在块特征级联起来进行最终的分类损失计算。其中图像的部分是使用NIPS2015的空间变换网产生的,该网络的作用为产生一个六维的向量来表示单应性矩阵,然后通过梯度下降来端到端的优化参数,从而达到自动学习需要将输入图像进行怎样的几何变换才能使得最终的分类精度提高。本文构造了基于三个部分的损失函数如下:
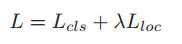
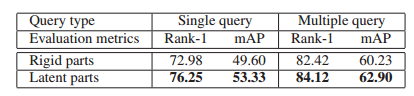
其物理意义第一项是分类损失,其实现为交叉熵损失,第二项是定位损失,即潜在块的位置对最终分类的精度的损失,通过优化这个函数,可以得到潜在块怎么提取,也就是NIPS2015的空时转换网的参数。论文中提到加入了定位损失,使得精度提高了9%。其Market精度如下图所示:
-
【CVPR2017】Multiple People Tracking by Lifted Multicut and Person Re-identification
本文主要的重点是跟踪,没有使用任何通用的行人重识别库,主要是通过跟踪来实现行人重识别但是不能跨非交叠视野。
-
【CVPR2017】Person Re-identification in the Wild
本文也是提出了整合行人检测和行人重识别任务的端到端的行人重识别框架,同时推出了新的行人重识别数据库PRW。没有新的代价函数和网络构架。
-
【CVPR2017】Quality Aware Network for Set to Set Recognition
本文提出的是针对视频序列的行人重识别方法。没有进行详细的阅读。
-
【CVPR2017】Re-ranking Person Re-identification with k-reciprocal Encoding
本文暑假何悠读过,主要思想是利用已有的搜索结果,通过公共邻元关系进行再排序,其示意图如下:

-
【CVPR2017】Scalable Person Re-identification on Supervised Smoothed Manifold
本文为AAAI2016可扩展流形在行人重识别中的应用,其主要核心思想是使用监督嵌入流形来对行人图像特征向量进行降维表示,同时保证了降维时对类内距离和类间距离的约束,可扩展流形与普通流形所不一样的地方在于,使用可扩展流行即在流形嵌入过程中除了对其邻元关系进行保持以外,还可以扩展嵌入全局的相互关系。即下图的affinity graph:
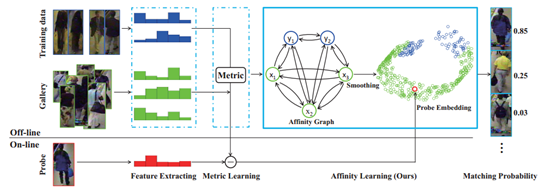
本文使用CNN特征作为本算法的输入,本算法属于子空间学习(流形学习),最终Market精度如图所示:
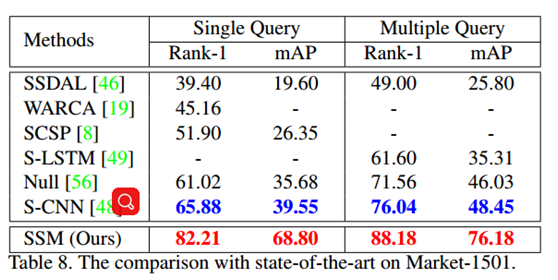
该度量学习算法能提升CNN特征的较大精度。
-
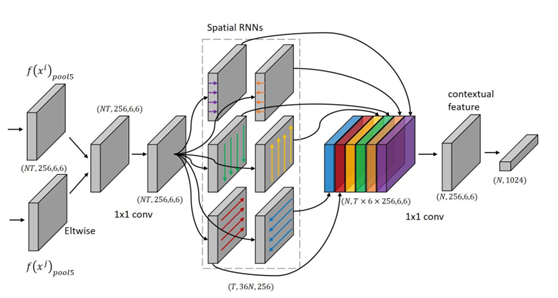
【CVPR2017】See the Forest for the Trees
本文为使用注意力机制的循环神经网络在视频行人重识别领域的应用,其所提创新模块如下图所示:
-
【CVPR2017】Spindle Net Person Re-identification with Human Body Region Guided
本文使用预训练的人体姿态估计先检测出人体关节点,然后对其进行局部特征提取,与我暑假期间所做工作相似:
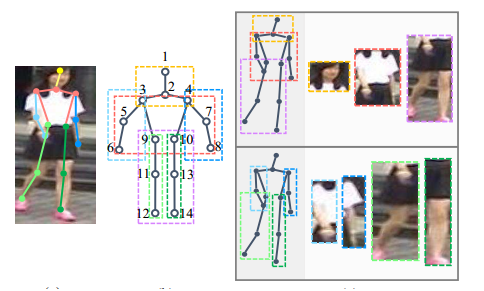
但从文章末尾的表格可以看出本文主要的精度来自于全局图像,身体区域特征对整体精度提升很小。其网络构架如下:
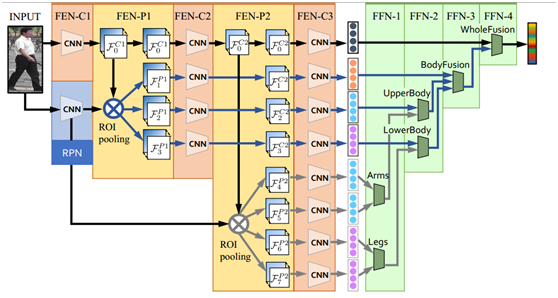
并且其融合局部和全局特征存在大量的全连接参数,计算代价极大,并且效果并未提升很多,融合方式不合理,其在market上的精度:
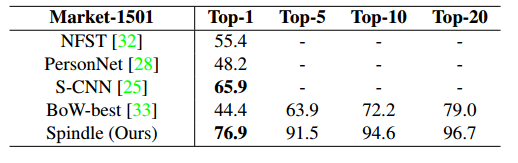
ICCV2017
-
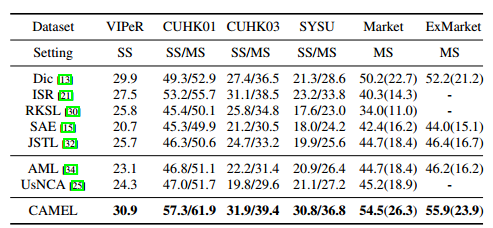
【ICCV17】Cross-view Asymmetric Metric Learning for Unsupervised Re-id
中山大学郑伟诗团队的经典算法延续,唯一不一样的地方在于改成了非监督的算法。其核心思想在于先使用K-means聚类给出初始的类标签,在进行度量学习,所使用的时传统特征,其精度如下:
-
【ICCV17】Deeply-Learned Part-Aligned Representations for Person Re-Identification
该文章与暑假读过的端到端的注意力网络for Reid非常相似,只是没有使用LSTM循环神经网络,并且还提升了精度,其效果如下:

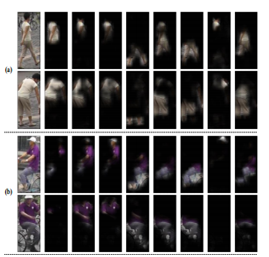
本文的主要思想为:在特征图上学习一个Mask,Mask在对应位置的值得大小被认为是Attention需要侧重的程度,本文使用了NLP领域应用广泛而且也相对较为先进的Attention机制,其目标函数为普通Triplet loss,如下:
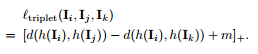
本文最后的融合方式也是直接级联,证明了全局结合局部的方式能达到更好的精度:

-
【ICCV17】Group Re-Id via Unsupervised Transfer of Sparse Features Encoding
针对野外行人重识别提出的组匹配算法,没有使用标准行人重识别数据集。其算法主要思想为使用跟踪信息或者视频信息构成多张行人照片的组信息,从而采用集合到集合的匹配策略,适用于基于视频行人重识别。
-
【ICCV17】In Defense of the Triplet Loss for Person Re-Identification
提出了目前为止精度最高的Triplet loss 函数:
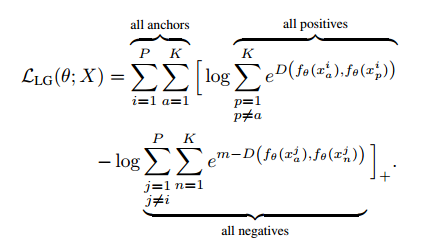
其物理意义在于取出Batch当中类内最大的距离和类间最小的距离进行Triplet loss计算,有效增加了Hard Mining的能力,同时本文也采用了Soft-margin的思想,如下图所示:
其在market库上到达了现在最高的精度如下:

本文的trick在于使用了最新的网络构架残差网,相比较而言比vgg的baseline 会更高一些。
-
【ICCV17】Jointly Attentive Spatial-Temporal Pooling Networks for Video-based Person Re-Identification
本文是针对视频的行人重识别网络构架,几乎照抄了Attention机制的新形式Attentive pooling 在NLP当中的形式,结构如下:
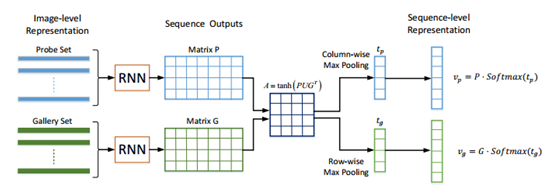
在自然语言理解领域有许多针对序列建模的方法和算法模型,其实远超于图像领域对序列的建模算法,涉及序列建模可借鉴NLP。
-
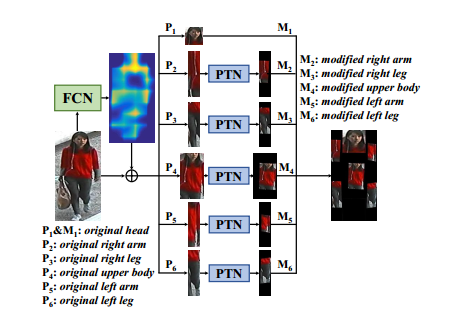
【ICCV17】Pose-driven Deep Convolutional Model for Person Re-identification
本文与CVPR2017作者相同,是基于之前的工作,同样采用了预训练的关节检测网络:
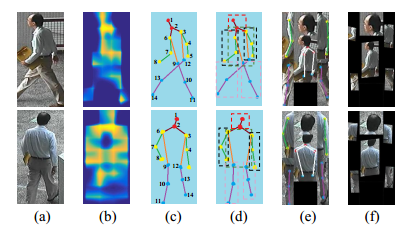
与CVPR2017 Spindle Net Person Re-identification with Human Body Region Guided不一样的地方在于,被检测出的身体部分,要通过NIPS2015的时空变换网(STN)进行几何旋转和缩放后,再进行特征提取和融合,是整合了CVPR2017中使用STN的网络和pose关节点检测网络的混合构架,其示意图如下:
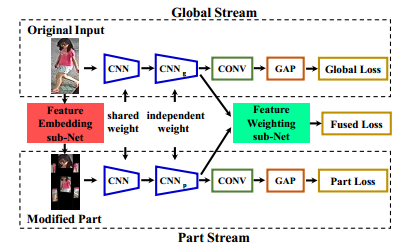
最终的融合方式也更加合理,使用了avgpooling之后将part stream和global stream融合起来:
其融合的方式公式化如下:
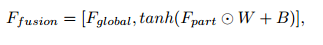
相当于级联了和全局特征一样长的局部特征,而这个局部特征是使用权重相加方式合成的。与我们自己的工作不一样。
-
【ICCV17】RGB-Infrared Cross-Modality Person Re-Identification
本文针对红外图像跨模态地重识别行人构建了网络,并且分析了双流网络和单流网络的区别,最终采用独特的Zero-Padding模式进行训练,其框架如下:
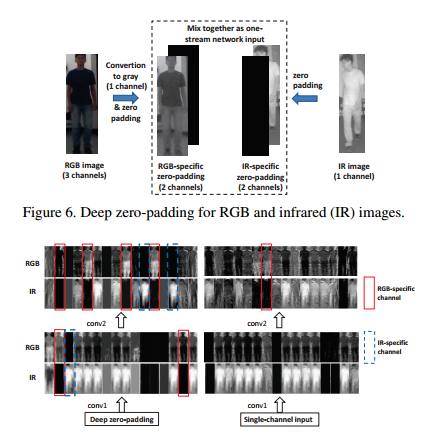
是一篇提供了很多训练网络经验的文章,虽然其数据我们不经常能够获取得到。
-
【ICCV17】SVDNet for Pedestrian Retrieval
本文是一个传统方法与深度网络的结合,主要目的是利用SVD来对学习到的卷积核进行提炼,即希望学习到的卷积核相互正交,这样不仅可以减少参数,同时可以去除噪声,但是并非端到端算法,实现过程比较复杂,其框架如下:

最终实验证明,SVD大幅度提高了行人重识别的精度:
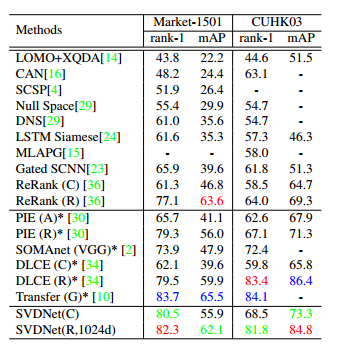
-
【ICCV17】Unlabeled Samples Generated by GAN Improve the Person Re-identification Baseline in vitro
本文通过生成对抗网络,生成更多的"人"图片:

通过增强训练样本,来使得网络的精度能够提高,同时也推出了新数据集vitro。
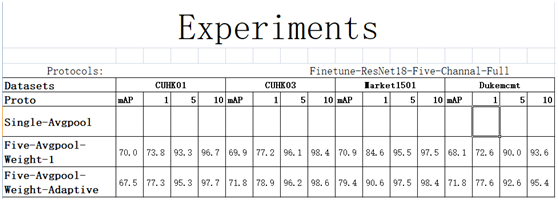
针对行人重识别任务的分块多通道自适应融合深度神经网络
网络构架图如下:
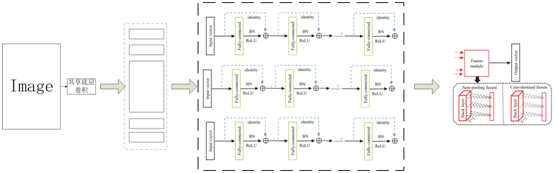
创新点:
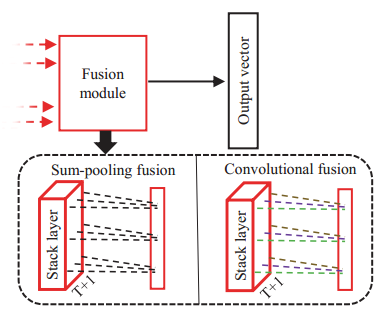
我们的融合模块采用局部全连接方式,学习到的权重经试验分析合理。
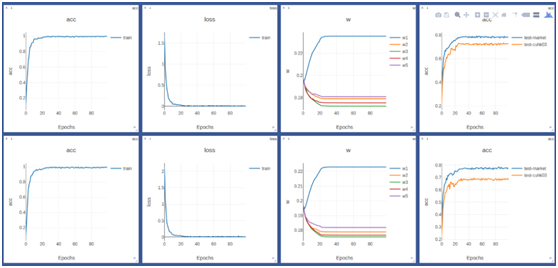
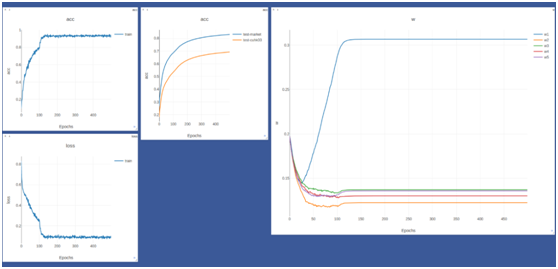
其中w1为全局流权重等于0.4其他w2,w3,w4,w5分别为头,衣服,裤子,腿和鞋所对应的位置,分别为1.1,1.9,1.8,1.3在market数据库上。
在CUHK01数据库上也表现出相同的趋势:
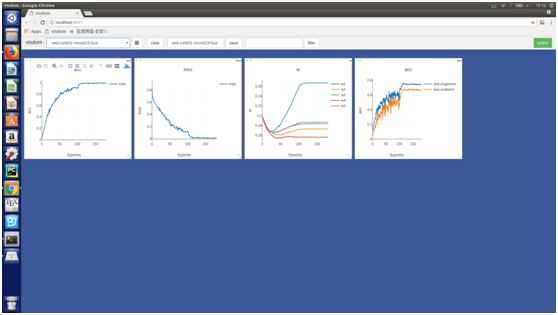
同样我们在CUHK03数据库上也做了对比试验:
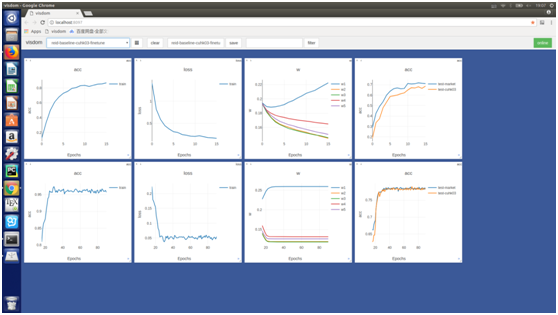
通过对比试验我们发现在每个库上,使用自适应权重均能获得较大提升:
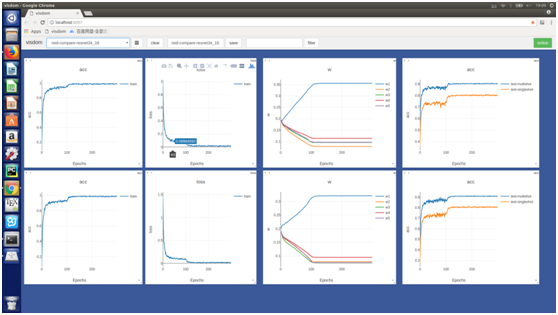
目标函数采用流形对齐中的强约束条件:
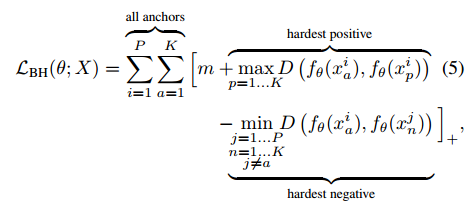
最大类内距离要小于最小类间距离。
我们的精度: